

LaCulturaDelDato #122
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il centoventiduesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del centoventiduesimo numero:
👅Etica & regolamentazione & impatto sulla società. Dalla tecnica alla filosofia: Massimo Chiriatti
Presentati
Massimo Chiriatti. Tecnologo, dopo qualche decennio in altre multinazionali, oggi sono il CTO di Lenovo. La mia radice è tecnica a cui ho aggiunto lo studio delle scienze politiche e master in gestione dei sistemi informativi; ho cercato di mantenere questi due percorsi contemporanei e complementari.
Provo a scrivere concetti che suscitino riflessione e che mettano delle altre idee in testa, o definiscano meglio quelle che abbiamo. Per esempio, collaboro con Rai 1 nel programma #Codice, e ho scritto un paper con il prof. Luciano Floridi che sta ancora ricevendo molte migliaia di citazioni.
Ho provato anche nell’ultimo libro, Incoscienza artificiale, dove ho teorizzato l’AI come Sistema 0 (sulla base del modello promosso dal premio Nobel Daniel Kahneman) e nelle cattedre nelle quali sono titolare in Luiss a Roma e alla Cattolica a Milano.
Tutto ciò serve per rendere l’AI più accessibile a più persone.

Il mio ruolo tra 10 anni sarà …
cercare sempre di stare con persone per bene e divertendoci innovando.
L’innovazione significa preoccuparsi del domani, per realizzarla occorre almeno fare due cose: studiare e immaginare le future regole del campo di gioco.
È il mio metodo per portare il futuro più vicino al presente, ognuno fornendo la propria competenza, umiltà e onestà.
Cercherò di conoscere persone, avviare conversazioni, portare delle informazioni: belle, nuove, utili, vere e giuste. Se ci sarà tempo di vita disponibile, le conseguenze non potranno che essere positive.
Quale è la sfida più importante che il mondo dei dati e algoritmi ha di fronte a sé oggi?
Accanto alle grandissime opportunità, si possono intravedere almeno un paio di sfide: sul piano sociale e individuale.
La società rischia di stratificarsi in pochissimi proprietari di infrastrutture (e dati) e miliardi di affittuari perpetui. Prima con il cloud si cedeva la proprietà delle infrastrutture, ma l'economia dei dati è un gran business e così sono un nuovo fattore di produzione. Si può e si deve ancora scegliere, perché la sfida più che tecnologica è attrarre le migliori persone con le migliori competenze.
E quando parliamo di persone con l’AI dobbiamo far riferimento alla statistica, perché è qui che si annida l’incertezza. È nel nostro imprevedibile scarto che emerge la qualità dell’essere umano, che sappiamo decidere nell'incertezza con istantaneità e con la nostra unica responsabilità morale.
Senza dimenticare che indossiamo i computer e la loro logica è già entrata dentro di noi; i dati ne stanno uscendo.
Segnalaci il progetto o la risorsa nel mondo dei dati di cui non potresti fare a meno
“La Cura” del compianto Salvatore Iaconesi, perché non dobbiamo dimenticare il suo genio che deve restare con noi, per continuare la sua opera di condivisione, e ostacolare la logica estrattiva che ci domina, purtroppo.
Sto cercando di fare a meno dei social, tranne Linkedin per ora.
Non posso fare a meno dei tanti libri che guardano all’AI con una prospettiva filosofica (per esempio: M. Gancitano, F. D’Isa, R. Manzotti etc.) che ci portano al pensiero lungo, ai principi primi, alle cose che non cambiano mai, come i desideri degli esseri umani. Perché, se studiata bene la filosofia, ci si accorge che è il pensiero più concreto e duraturo ad aiutarci a dare un senso in questi tempi allucinanti. Per noi, non per le macchine.
PSS (Post Scriptum di Stefano): Ho conosciuto Massimo diverso tempo fa, a poco a poco, attraverso interazioni rade ma di un valore inestimabile. La cosa che mi sorprende ogni volta che ci sentiamo e facciamo qualcosa insieme è la facilità con cui sa spiegare le cose a diversi livelli di complessità e a diverse platee. E questo è la garanzia di quanto bene comprenda il presente (e intraveda il futuro). La prefazione che ha fatto al libro che ho scritto con Alberto Danese "La Cultura del Dato" è qualcosa che rileggo periodicamente, stupendomene tutte le volte 🙂
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Dalle grotte di Lascaux a Great Tables: il lungo viaggio delle tabelle e dei suoi dati
“Le tabelle sono nate da griglie quadrate. Quando le griglie vengono realizzate in questo modo, si generano invariabilmente dei contenitori che possono contenere qualche tipo di informazione. I primi esempi conosciuti di griglie risalgono a tempi molto lontani nella storia dell'uomo. Rappresentazioni della griglia risalenti a 25.000 anni fa sono state trovate sulle pareti delle grotte di Lascaux e Niaux, in Francia …”
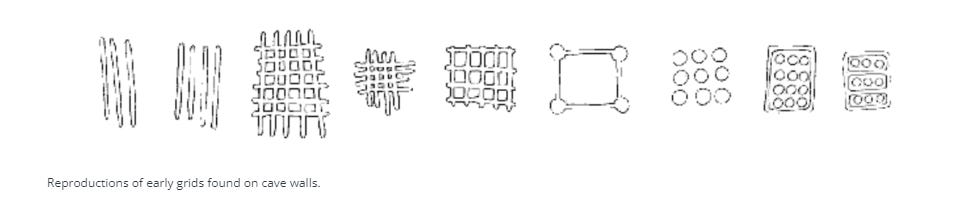
Questo è l’inizio dell’approfondimento che ti consiglio oggi se sei curioso di conoscere l’evoluzione da 25.000 anni fa ad oggi del contenitore di dati più longevo della storia dell’umanità. Contenitore che è ancora la forma più usata di rappresentazione di dati all’interno delle moderne organizzazioni. Alla fine, viene ancora usato prevalentemente per la stessa finalità di questa tavoletta cuneiforme originaria della Mesopotamia (proveniente dal Tempio di Enlil a Nippur, circa 1850 a.C.), contenente le fonti di reddito e gli esborsi mensili per 50 addetti al tempio.

Se poi vuoi provare a fare con Python tabelle abbastanza belle ma un po’ più moderne, puoi provare proprio la libreria “Great Tables” realizzata dall’azienda da cui proviene l’approfondimento di oggi.
🖐️Tecnologia (data engineering). Dal 2020 a Oggi: L'evoluzione delle architetture dati secondo Andreessen Horowitz e non solo …
Ritornando al numero 3 della newsletter, ti segnalo il link a questo post “Emerging Architectures for Modern Data Infrastructure” redatto dal fondo di investimento Andreessen Horowitz. Questo è stato anche il link più cliccato dai lettori 28 mesi fa.
Ti fornisco quattro motivi per cui vale la pena leggerlo o rileggerlo, se ti occupi di architetture dati o comunque hai tante interazioni con esse:
1. Nonostante sia un articolo originariamente del 2020 e aggiornato successivamente, l’unica cosa obsoleta del titolo è forse l’aggettivo “emerging” perché di fatto i modelli architetturali descritti sono ormai emersi e sono quelli attualmente più moderni.
2. Anche se la parte relativa al machine learning (e all’uso degli LLM) non contiene tutti gli ingredienti emersi recentemente, presenta tutti i blocchi architetturali necessari per integrarli.
3. Lo strapotere “mediatico” dell’intelligenza artificiale generativa, anche a livello di architetture dati, ha fatto perdere di vista l’importanza di investire sui dati e sull’avere una data platform solida e performante. Questo non è opzionale, ma un forte prerequisito per sfruttare al meglio gli LLM.
4. Te lo avevo già scritto 28 mesi fa: di solito mi fido molto di chi, oltre a dare consigli e proporre modelli, ci investe anche (è “skin in the game”, come dicono gli Americani). E i modelli proposti sono indipendenti dai vendor di tecnologia. Sono solo citati alcune soluzioni di mercato come esempio per ciascun pezzo di architettura, e questo probabilmente agevola comprensione e lettura.
Cosa ne pensi di questi modelli di infrastruttura dati proposti? E della sezione back to…? Scrivimelo via mail (st.gatti@gmail.com) e/o nei commenti.
👃Investimenti in ambito dati e algoritmi. Start-up del mese Maggio 2024: Deepl
Come ogni mese, grazie alla mia attività di monitoraggio dell'innovazione e degli investimenti a livello mondiale, ho l'occasione di presentarti una startup che ha catturato particolarmente la mia attenzione, distinguendosi per aver ottenuto finanziamenti significativi a maggio 2024. Questa startup opera nell'ambito dei dati e degli algoritmi, integrando queste tecnologie in modo sostanziale nei suoi prodotti destinati al mercato.
Iniziamo, come sempre, con qualche dato su maggio 2024 a livello globale: il numero e i valori degli investimenti sono decisamente in crescita rispetto alla media dei primi quattro mesi dell’anno, non tanto in termini di numero di transazioni quanto sul totale investito. Ho inserito nel mio database 533 investimenti a livello globale, di cui circa 88 associabili al settore Data & AI, con una crescita di quasi il 40% in termini di volumi investiti. Questi dati sono in linea con quelli di Crunchbase nello stesso periodo, con AI, robotica e healthcare sugli scudi.
La startup del mese non poteva che essere DeepL, un servizio di traduzione automatica che magari anche tu, come me, usi da anni. Pur non avendo provato tutti i servizi di traduzione attualmente esistenti, ritengo DeepL il servizio più accurato e che uso quando tengo particolarmente alle sfumature della traduzione. Per la prima fase di traduzione ho usato il loro servizio a pagamento per la pubblicazione dell’edizione inglese di "La Cultura del Dato".
“Ci sono due tipi di aziende di IA: quelle che sono state lanciate prima del ChatGPT e quelle che sono state lanciate dopo. La startup di traduzione AI DeepL, fondata nel 2017, fa parte della prima categoria, ma sta felicemente cavalcando l'onda del boom dell'AI …”. Questo è l’inizio dell’intervista al CEO di DeepL, che racconta come non solo sono sopravvissuti alla grande concorrenza di ChatGPT ma sono riusciti a incrementare l’utilizzo dei loro servizi. Spoiler: come molte storie di questo tipo, ha molto più a che fare con l’ossessione per la qualità del prodotto e la gestione dei talenti che con operazioni commerciali. L’articolo, e se hai tempo l’intervista nel podcast collegato, meritano il tuo tempo per vedere da vicino una cultura di successo. DeepL era già diventato un unicorno a inizio 2023 ed ora, con un ulteriore round di 300 milioni di dollari, è diventato un unicorno ancora più in carne, raddoppiando la sua valutazione a 2 miliardi di dollari.
E se non l’hai ancora fatto, ti consiglio di provare direttamente il loro servizio, gratuito per traduzioni limitate.
👀 Data Science. Open Source e LLM: la battaglia per una definizione
"Ma se la comunità open-source non riesce a trovare una definizione, e in fretta, qualcun altro ne troverà una adatta alle proprie esigenze. 'Riempiranno questo vuoto', ….. 'Mark Zuckerberg ci dirà cosa pensa che significhi 'open' e ha un megafono molto grande'."
Questo è il finale dell’approfondimento che ti suggerisco oggi. Discute un argomento che mi sta molto a cuore e credo sia centrale nell’evoluzione del mondo dell’intelligenza artificiale e soprattutto dei Large Language Model e in particolare il concetto di Open Source dei modelli. Te ne avevo già parlato nel numero 113 della newsletter, evidenziando il mio scetticismo sull’adattamento di questa definizione, che arriva dal mondo del software, al mondo dei modelli di intelligenza artificiale.
Il dibattito all’interno della community open source è comunque evoluto e si stanno delineando tre livelli di apertura che, pur avendo una forte diversità tra loro, potrebbero effettivamente portare a maggior chiarezza. In termini concreti, con livelli di apertura crescente, possiamo parlare di:
1. Modelli aperti ma senza indicazione di quali dati sono stati usati per il training dei modelli stessi.
2. Modelli aperti con una descrizione dei dati usati per il training ma senza rilasciare anche i dati.
3. Modelli e dati di training disponibili per chi li voglia usare, con una completa tracciabilità di come è stato creato il modello, dati compresi.
Nell’articolo, se sei curioso, puoi anche trovare le posizioni con tutte le sfumature dei principali attori, come OSI (Open Source Initiative), che stanno discutendo e riflettendo per arrivare a una o più definizioni che siano condivise dai più.
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!