

LaCulturaDelDato #131
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il centotrentunesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
🚀 Questa puntata è sponsorizzata da “Data Masters”
E’ veramente un piacere ospitare come sponsor di questa puntata gli amici di Data Masters per l’approccio concreto che hanno alla formazione e per la qualità dei loro insegnanti. Parlo, proprio nell’approfondimento sulla tecnologia di oggi, di agenti applicati alla scrittura del codice e sottolineo soprattutto quanto sia importante la formazione su queste tematiche. Per questo se vuoi fare sul serio puoi scoprire insieme a Data Masters, le Agentic Applications la nuova frontiera nell’automazione intelligente del lavoro. Combinando la potenza di modelli di linguaggio avanzati, come Chat-GPT, Llama, Phi-3 e i migliori LLMs Open Source, con le ultime evoluzioni di sviluppo dei sistemi RAG, potrai sviluppare innovativi sistemi decisionali autonomi, con capacità dinamiche che permettendo di agire, interagire e prendere decisioni in modo proattivo. Un’ Agentic Application comprende il contesto aziendale, anticipa le esigenze dell’utente e intraprende azioni mirate eseguendo casi d`uso pratici e reali. Questi nuovi sistemi possono elaborare grandi quantità di informazioni, analizzare dati complessi e fornire soluzioni personalizzate, il tutto in tempo reale.
Se vuoi essere all'avanguardia nello sviluppo di applicazioni di Intelligenza Artificiale, sviluppare sistemi RAG in locale, avendo un controllo completo sui tuoi dati sensibili puoi acquisire padronanza completa grazie alla Masterclass su LLMs Agentic Application con LangChain. La Masterclass più avanzata in Italia promossa da Data Masters che ti insegnerà a:
Unificare la tua base di conoscenza (documenti aziendali, sito web, excels, e tanto altro)
Orchestrare i large language models
Creare la tua Local GPT
Sviluppare le tue Agentic Applications
Il corso include 7 lezioni in diretta con i docenti, che si tengono dopo le 18, pensate per adattarsi ai tuoi impegni lavorativi ed è in partenza il 10 Ottobre Scopri il programma completo.
Data Masters è una Tech Academy Italiana che offre percorsi di formazione per professionisti ed aziende in Data Science, Machine Learning e Intelligenza Artificiale.
Ed ora ecco i cinque spunti del centotrentunesimo numero:
👃Investimenti in ambito dati e algoritmi. Biology + Engineering = Synthetic Biology & Progress
“La biologia sintetica è una combinazione di molteplici tendenze e progressi tecnologici che si sono incontrati all'inizio degli anni 2000 e hanno iniziato a trasformare la bioingegneria. Si tratta di strumenti più economici e potenti per la lettura, la scrittura e la modifica del DNA, nonché dello sviluppo di algoritmi e machine learning più avanzati e di robot più capaci ed economici...” Questo è l’inizio dell’approfondimento di oggi, che ha come obiettivo quello di introdurti, se non sei già a conoscenza, a uno degli ambiti più interessanti a livello di investimenti per il futuro, il quale sta facendo sempre più leva su dati e intelligenza artificiale.
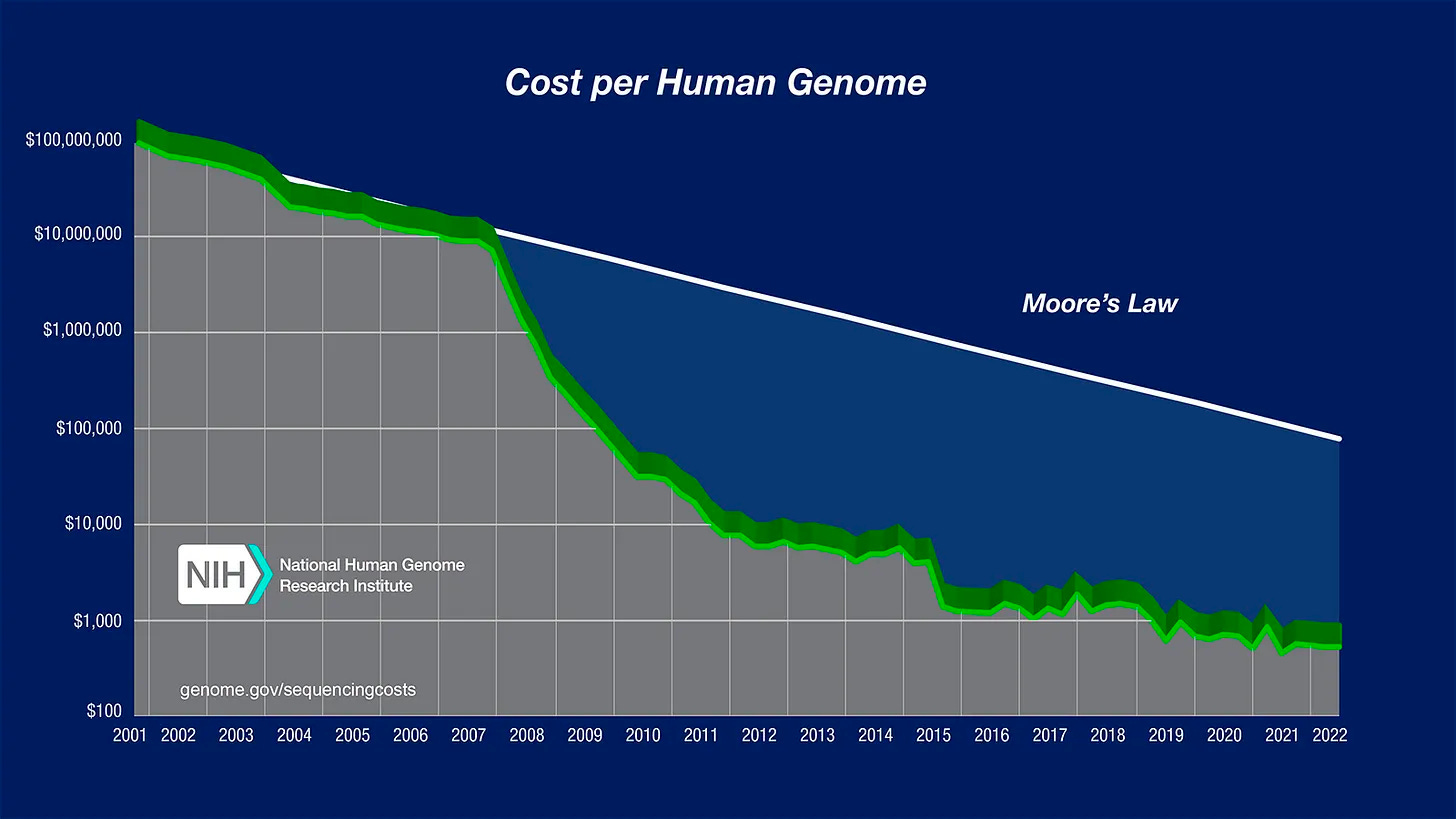
La biologia sintetica è stata sicuramente accelerata dalla drastica riduzione, negli ultimi 25 anni, del costo di lettura del DNA umano, che si è ridotto a un milionesimo del suo costo iniziale. Oltre a migliorare in maniera significativa il settore agroalimentare, la biologia sintetica è stata protagonista, spesso silenziosa e poco conosciuta, di successi come:
- La rapida creazione di un vaccino mRNA per Covid;
- La diminuzione del costo dell’insulina per i diabetici;
- L’accelerazione del ciclo di scoperta e test di molti farmaci, grazie anche alle recenti innovazioni nell’intelligenza artificiale generativa, come AlphaFold, di cui ti ho parlato in altre puntate della newsletter.
Nella seconda parte dell’approfondimento trovi molti dati interessanti sul lato degli investimenti nel biotech. In particolare, come si afferma nel post: “salute e medicina sono i principali motori degli investimenti in questo ambito, che rappresentano quasi l'80% degli investimenti nel primo trimestre del 2023, secondo il rapporto di SynBioBeta. Il fatto che la salute e la medicina ricevano la stragrande maggioranza degli investimenti non sorprende, se ricordiamo gli stretti legami tra biotech e farmaceutica.” Nella parte finale del report trovi anche la descrizione di diverse start-up che stanno facendo innovazione in questo settore.
Nonostante tutto l’ottimismo suscitato dai recenti successi, ci sono almeno due motivi di grande cautela quando ci si muove in questi ambiti:
1. I cicli di investimento nel biotech rimangono ancora molto lunghi, visti gli alti livelli di regolamentazione nazionale a cui i prodotti sono sottoposti, e il fatto che il mondo reale rimane ancora il modo per validare questi successi in maniera definitiva.
2. I rischi legati a errori o a interazioni con ecosistemi esistenti, come nel caso di tecniche legate all’agricoltura, rimangono ancora possibili e tuttora condizionano l’accettazione dei prodotti su larga scala.
Entrambi i punti non sono da sottovalutare se non vogliamo mettere a rischio la resilienza dell'ecosistema in cui viviamo.
🖐️Tecnologia (data engineering). LLM e Agenti Autonomi: potenzialità, sfide e consigli pratici
La scorsa settimana ho parlato delle attuali difficoltà nell'uso della generative AI per migrare codice legacy e ho espresso, con un po' di sarcasmo, quanto sia sopravvalutata questa tecnologia, anche a causa di tanto marketing "consulenziale". Visto che molti di voi mi avete scritto chiedendomi i motivi del mio scetticismo, oggi vorrei approfondire e chiarire che la mia posizione sull'utilizzo della generative AI nello sviluppo software non è affatto neo-luddista.
Credo che l'uso degli LLM come supporto per scrivere codice e la loro evoluzione in Agenti (quindi con un alto grado di autonomia) sia il caso d'uso più importante di tutti, perché è il più trasversale tra le diverse industrie. Tuttavia, il mio scetticismo nasce dal modo in cui spesso viene affrontato il problema nelle organizzazioni: si parte dai casi più complessi (come la reingegnerizzazione del codice legacy) senza un'adeguata formazione e preparazione all'uso di questi nuovi sistemi di supporto.
Proprio per evitare questi errori, se scrivi codice ti consiglio di dedicare parte del tuo tempo alla formazione per usare al meglio questi sistemi, seguendo i suggerimenti e gli esempi di chi, a mio avviso, sta facendo un ottimo lavoro utilizzando le tecnologie migliori. Ecco alcuni approfondimenti sul tema da parte di persone e aziende che stimo molto:
Il “solito” Andrew Ng spiega qui in modo semplice ma non banale perché la “multi-agent collaboration” è un pattern molto importante che sta ottenendo diversi risultati e suggerisce vari strumenti da provare.
Nicholas Carlini, scienziato e ricercatore di Google Mind, illustra come usa gli LLM in maniera efficace, evidenziando molti task legati alla scrittura del codice.
Ti consiglio di dare un'occhiata a LLM Codestral, recentemente rilasciato da Mistral e specializzato nello sviluppo software, e al sistema di Mistral per creare Agenti.
Infine, anche se è un suggerimento meno tecnico, se sei un leader tech, ti invito a leggere questa descrizione della “Egg-theory” per capire, dal punto di vista psicologico, come introdurre e facilitare al meglio l'uso della generative AI anche in contesti tecnici.
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Dalla Great Resignation ad oggi: cosa è davvero cambiato in due anni di rivoluzione del lavoro?
Era stato il link più cliccato dai lettori del numero 10 di questa newsletter. Eravamo, a inizio 2022, in un mondo che stava, faticosamente, cercando di uscire dai cambiamenti a cui ci aveva obbligato il Covid. Eravamo ancora nel pieno di un fenomeno, all'interno delle organizzazioni, che veniva chiamato, in modo pop, "Great Resignation". In questi due anni e mezzo è cambiato molto. C'è stato il periodo dei licenziamenti in molte aziende tech, il ritorno al lavoro in ufficio o, meglio, ad un assetto ibrido che sembra essere un punto di equilibrio stabile, almeno per molti knowledge worker. Tuttavia, molte esperienze e riflessioni che quasi tutti, e i data expert non fanno eccezione, abbiamo vissuto sono rimaste.
L’approfondimento che ti ri-suggerisco è un breve fumetto che spiega molto bene e in modo semplice il fenomeno della great resignation e del perché, soprattutto per le nuove generazioni, i soldi non sono la principale motivazione nella scelta del lavoro. Nel fumetto si parla di fattori che sono diventati e diventeranno, con il ricambio generazionale, ancora più importanti, soprattutto negli ambienti tech, e cioè:
la cultura aziendale
quello che preferisco non tradurre (perché non ne sarei capace), ma che viene citato come "meaning", ovvero l'incrocio tra la ricerca dello scopo nel lavoro (purpose) e il seguire la propria passione (passion)
la possibilità di crescere come professionista
la possibilità di circondarsi di persone di valore (network)
Non serve nulla di più per convincerti a rileggerlo, se non lo avevi fatto, che dirti che il progetto di questi due bravissimi giovani professionisti dell’arte grafica di Singapore si è allargato: ora hanno una newsletter molto popolare su Substack e hanno scritto anche un libro.
👀 Data Science. SQL e Generative AI: come stanno davvero le cose?
Se mi segui da un po' di tempo, sai quanto (e non sono l'unico a pensarla così) ritengo importante il linguaggio SQL per qualunque data expert, inclusi i data scientist. Ne abbiamo già scritto e ne abbiamo parlato approfonditamente insieme ad Alberto, anche nel nostro libro "La Cultura del Dato". Credo che l’SQL abbia mantenuto tutta la sua importanza, e moltissimi progetti di data science che ho visto e in parte “vissuto” negli ultimi 20 anni avevano e hanno una componente significativa di SQL, per non parlare di tutti i progetti di business intelligence.
Trovo quindi pericolosa e, per certi versi, semplicistica, la visione che sta prendendo piede in alcune organizzazioni secondo cui, grazie alla generative AI, non ci sarà più bisogno di SQL, o che sarà presto totalmente utilizzato da agenti intelligenti. Uno degli errori più grandi di questa prospettiva è ignorare che una delle difficoltà maggiori nell'estrarre informazioni dai database aziendali non risiede "solo" nel saper scrivere bene l’SQL, ma richiede una conoscenza semantica dettagliata dei dati, una buona qualità del dato e una solida comprensione del contesto. Saper combinare questi tre elementi con una buona conoscenza di SQL è il sacro Graal di ogni data analyst e data scientist.
Dire che oggi la generative AI è in grado di mettere insieme tutto questo in un ambiente reale e complesso, come quelli in cui lavoriamo, è perlomeno fuorviante. Quello che le tecnologie di generative AI riescono a fare oggi nell'area del Text-To-SQL rappresenta solo l'ultima fase del processo. Quindi, di fatto, iniziano a generare buoni risultati solo in ambienti semplici, dove la semantica dei dati è chiara, la qualità del dato è ottima e il contesto è semplice.
Se vuoi conoscere lo stato dell’arte delle soluzioni Text-To-SQL, ti consiglio una serie di approfondimenti tratti dalla “vita reale” di organizzazioni e team che stanno cercando di implementarle (con tutte le difficoltà tecniche del caso):
1) Qui trovi l’esperienza del team di Pinterest, davvero molto approfondita. Ti consiglio vivamente di perderti nei dettagli tecnici dell’articolo, ma la parte finale è particolarmente illuminante: “Lavorando a questo progetto, ci siamo resi conto che le prestazioni di text-to-SQL in un contesto reale sono significativamente diverse da quelle dei benchmark esistenti, che tendono a utilizzare un numero ridotto di tabelle ben normalizzate (che sono anche prestabilite). Sarebbe utile per i ricercatori produrre benchmark più realistici che includano un maggior numero di tabelle denormalizzate e che trattino la ricerca delle tabelle come parte centrale del problema.”
2) Per chi sottovaluta l'importanza della conoscenza del contesto quando si formulano query, consiglio di leggere l'articolo “Text to SQL and its uncanny valley”, che spiega molto bene le difficoltà che emergono in questo ambito.
3) Se comunque vuoi imparare lo stato dell’arte del Text-To-SQL in un ambiente semplificato (e te lo consiglio), questo corso di Andrew Ng (che lavora con file CSV) è un ottimo punto di partenza.
Come ho già scritto nella sezione dedicata alla tecnologia, non sono affatto contrario all'utilizzo degli LLM per scrivere SQL (per esempio, in situazioni semplici, anche lo stesso ChatGPT lavora già molto bene). Tuttavia, la generazione di SQL che risolve problemi reali di business è più complessa di quanto a volte si possa pensare 🙂. Questa attività coinvolge aspetti come la semantica e, più in generale, la generazione di metadati, ambiti in cui la generative AI ha ancora margini di miglioramento e necessita di capacità di integrazione.
👅Etica & regolamentazione & impatto sulla società. Dalla Mente Umana agli LLM: un viaggio tra Neuroni, AI, “Riassuntori” e Creatività
In questa ultima sezione della newsletter, non ti segnalo semplici e brevi approfondimenti. Ma se, come me, sei appassionato a percepire (capire sarebbe forse una parola eccessiva) quanto differisca o meno il funzionamento di una rete neurale — alla base della generative AI e degli LLM — dalla mente umana, allora è un cammino che devi intraprendere assolutamente. Intuire questi concetti è fondamentale anche per discutere e prendere decisioni efficaci su temi come l'interpretabilità dei modelli generativi o i rischi associati al loro utilizzo. Spesso si cade in metafore troppo pop o in analogie troppo azzardate tra i neuroni della mente umana e quelli che abbiamo chiamato allo stesso modo, ma che funzionano con il silicio 🙂. Ma basta con le parole, e non voglio farti perdere tempo perché ne dovrai usare tanto se vuoi seguire il percorso che ti suggerisco di fare:
1) Non puoi ignorare uno dei migliori articoli usciti quest'anno sul tema, ovvero quello pubblicato da Anthropic: “Mapping the Mind of a Large Language Model”. Questo articolo fa un passo in avanti nella comprensione del funzionamento degli LLM. Vi si evidenzia l’importanza di ciò che chiamano "features", che di fatto rappresentano direzioni interpretabili nello spazio delle attivazioni neuronali del modello, utilizzate per rappresentare informazioni specifiche nei dati. Una feature può essere considerata come una combinazione di attivazioni dei neuroni che rappresenta un concetto o un pattern specifico nei dati. Lo so, è complesso, ma se leggi l’articolo o, ancora meglio, il paper alla base di tutto, sono sicuro che ti sarà meno oscuro 🙂
2) A questo punto, anche se sono certo che, soprattutto se sei più giovane di me, lo avrai già studiato a scuola, ti consiglio di ripassare com'è fatto, come funziona e come si è evoluto il nostro cervello attraverso questa serie di cinque post, chiamati “The Brain”, di
nel suo Intelligent Blog. Valentino fa un’ottima sintesi sul tema, basandosi su alcune lezioni di un bravissimo neuroscienziato, Jan Schnupp.3) E se ti rimane ancora del tempo 🙂, ti consiglio di leggere il punto di vista del fondatore di Every (una piattaforma concorrente di Substack) con un titolo interessante: “ChatGPT and the Future of the Human Mind”. L’articolo esplora come i modelli linguistici avanzati, come ChatGPT, influenzino la nostra percezione e per certi versi l’evoluzione dell'intelletto umano. L'autore sostiene che questi strumenti non minacciano l'unicità umana, ma piuttosto ne cambiano il ruolo nella creatività e nel lavoro. Propone che ChatGPT sia un "riassuntore", capace di migliorare la trasmissione culturale e l'uso della conoscenza, lasciando comunque spazio alla creatività e all'unicità umana in altre aree. Alla fine, l'adattabilità umana è vista come la vera qualità distintiva che resta rilevante.
Se, dopo aver letto tutti (o anche solo alcuni…) questi approfondimenti, hai ancora voglia di scrivermi o di lasciare un commento su questo tema, ti ringrazio in anticipo perché sono super interessato a proseguire la discussione! 😊
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!
Il link https://learn.deeplearning.ai/courses/building-your-own-database-agent/l ha una lettera di troppo alla fine