

LaCulturaDelDato #015
Dati & algoritmi attraverso i nostri 5 sensi

Ciao,
io sono Stefano Gatti e questo è il quindicesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del quindicesimo numero:
🖐️Tecnologia (data engineering). - Play & Fun for learning
Il modo migliore per imparare è giocare e divertirsi. Per questo sia che tu voglia imparare a programmare, ti voglia perfezionare o preparare al test per un colloquio ti consiglio caldamente le sfide in cui devi metterti in gioco scrivendo righe di codice per superare alcune prove. Il tutto è spesso condito con storie fantasy che aggiungono un pizzico di storytelling al tutto. Questa settimana, anche se il clima ci fa chiaramente percepire che non siamo a Dicembre, ti propongo “AdventofCode” che ogni anno dal 2015 propone 25 sfide, a difficoltà crescente, che ci consentono di risolvere, nel nostro linguaggio preferito, degli enigmi lungo una storia. Il tutto con una grafica che ci rimanda ai gloriosi anni ‘80. Se invece siete affascinati dalla matematica allora vi consiglio il progetto Eulero, un’alternativa decisamente più sfidante.
👀 Data Science. Useful datasets
Jeremy Singer-Vine è un giornalista (Wall Street Journal e BuzzFeed News), un programmatore ma soprattutto un data-lover nerd che propone da anni utili e curiosi datasets aperti attraverso la sua newsletter “Data is Plural” che è diventata molto cool tra i datascientist di tutto il mondo. Gli argomenti sono veramente i più disparati: si va dal dataset di tutti gli incidenti con armi da fuoco negli Stati Uniti dal 1970 ad oggi al database di tutti i libri perfettamente annotati di Art Garfunkel. Vista la sua professione, i dati che propone sono prevalentemente legati all’attualità e a tematiche economiche. E ogni settimana, ti condivide i suoi più di 1500 dataset suggeriti da quando ha cominciato a fine 2015 consentendoti anche una facile ricerca nella collezione. Se, come spero, oltre a scrivere codice, come datascientist, ti occupi anche di data-scouting Jeremy è assolutamente da seguire!
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. - Coder for money
Partendo da un tweet di una data-expert americana che illustra, con il diagramma di Venn che riporto sotto, la numerosità e complessità dei ruoli lavorativi nel mondo dei dati, Benn Stencil fa il punto della relazione tra job title e retribuzione negli Stati Uniti nel mondo dei dati.
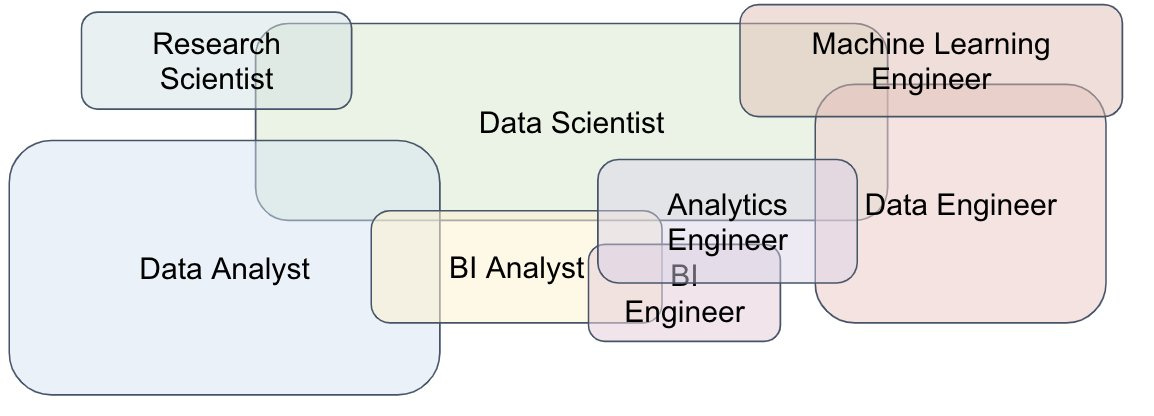
La differenza di cultura e forse di maturità dell’industria (USA vs Europa continentale) porta l’autore a lamentare una sostanziale differenza di retribuzione troppo sbilanciata verso chi scrive codice rispetto a chi non lo fa ma che invece, cito testualmente, “deve identificare quali sono le sfide aziendali più urgenti, capire come risolvere i problemi più complessi e mutevoli, e confezionare le loro conclusioni in narrazioni persuasive, il tutto navigando nella politica organizzativa dei suoi interlocutori. È disordinato, scomodo e, almeno secondo la mia esperienza, molto più difficile di usare git.” Mi sembra che in Italia la situazione non sia esattamente questa e sulla base della mia esperienza non la penso esattamente come lui. Credo comunque che la discussione, trattata nel post, sull’allineamento tra la corretta definizione di job-title e retribuzioni medie, sia un problema molto complesso, attuale e su cui ci sono ampi spunti di miglioramento su cui lavorare in collaborazione con l’HR delle aziende.
👃Investimenti in ambito dati e algoritmi. Corporate+Start-up=CVC a winning equation?
Si chiama Corporate Venture Capital e significa, se sei una grande azienda, investire, in maniera strutturata e continuativa, in start-up o aziende innovative. Secondo questa ricerca condotta da Accenture sembra essere una cosa positiva, per le aziende che lo fanno. In realtà non è un “esercizio” semplice per diversi motivi: in primis la struttura, preposta a fare questa attività, deve avere al suo interno persone che conoscano bene il settore e i trend in cui si opera ma anche le dinamiche di funzionamento delle aziende più innovative.
A mio modo di vedere ci possono essere due motivazioni principali per cui si fa CVC.
La prima è legata ai meccanismi di Open Innovation: fare investimenti in ottica industriale per avere benefici in termini di innovazione anche all’interno dell'organizzazione che investe. Mi è capitato di farlo in passato: non è semplice ma a volte il tutto riesce particolarmente bene. La seconda è invece legata solo a motivi finanziari e non sempre, gli investimenti, sono legati al business dell’azienda che investe. È questo il caso, stando in ambito dati e algoritmi, di Bloomberg Beta, il CVC di Bloomberg che ha il “manuale di funzionamento” su Github e gestisce tutto in maniera molto trasparente, criteri di investimento e portfolio compresi, con ottimi risultati!
👅Etica & regolamentazione & impatto sulla società. Living with artificial Intelligence
Ogni anno dal 1948 la BBC dedica una serie di lezioni, le Reith Lectures (4 o 5 ore di programmazione), ad un argomento di grande importanza per l’evoluzione della società, il tutto realizzato da un importante esperto del settore. L'argomento del 2021 è stato dedicato all’intelligenza artificiale e a come, secondo Stuart J. Russell, un personaggio iconico del settore, riusciremo a convivere e ad evolvere insieme (e la cosa mi interessa molto più della mediatica uscita dell'ex-ingegnere di Google Black Lemoine e della sua presunta AI senziente). Se non avete quattro ore da dedicare all’ascolto, questo articolo di Chiara Sabelli, ne sintetizza molto bene i contenuti e evidenzia i passaggi chiave. Quello che mi ha particolarmente colpito e che mi trova molto d’accordo sono tre cose. La prima è che gli obiettivi, l’intelligenza artificiale, non se li dà da sola ma glieli forniamo noi: per questo si tratta di un meccanismo di scelta particolarmente complesso e delicato. Il secondo, strettamente correlato, è l’insieme dei tre principi che Russell formula e che dovrebbero guidarci nella ricerca in questo ambito e cioè:
L'unico obiettivo dell'IA dovrebbe essere quello di massimizzare la realizzazione delle preferenze umane.
La macchina è inizialmente incerta su quali siano queste preferenze.
La fonte ultima di informazioni sulle preferenze umane è il comportamento umano (compreso ciò che diciamo e scriviamo).
Il terzo ed ultimo è l’autonomia che riusciremo a mantenere nel rapporto con un’intelligenza artificiale sempre più “generale”: questo sarà cruciale per non scivolare, per chi ha visto il film, in un mondo simile a quello raccontato in Idiocracy. Del resto quando mi muovo per Milano senza GPS, non un algoritmo di AI di ultima generazione, mi rendo conto di quanta autonomia abbia perso negli ultimi 20 anni :-)
Da questa settimana puoi leggere la mia newsletter anche su Mindit, una nuova piattaforma di informazione, realizzata da due ragazzi svegli e dall’acuto spirito imprenditoriale. Attraverso la loro App potrai leggere le tue newsletter preferite isolate dal traffico mail quotidiano.
Un grazie in particolare a te e tutti i tantissimi lettori della newsletter che mi suggerite spunti e link. Alcuni di quelli che segnalo e approfondisco sono merito tuo.
Continua a farlo e … se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!