

LaCulturaDelDato #034
Dati & algoritmi attraverso i nostri 5 sensi

Ciao,
sono Stefano Gatti e questo è il trentaquattresimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del trentaquattresimo numero:
👃Investimenti in ambito dati e algoritmi. Prompt Marketplaces for Generative Models: fad or future?
Ti ho parlato in diverse sezioni, nei numeri precedenti, della crescente importanza dei modelli di intelligenza artificiale generativi: quelli che, semplificando un poco, creano nuovi dati da dati esistenti in modalità non supervisionata come per esempio testo da altro testo (GPT-3) o immagini o video da testo (Dall-E o Stable Diffusion per esempio). Tutto questo cambierà la modalità di lavoro nel prossimo futuro di molti creativi! Ma per farti capire quanto fermento ci sia in questo ambito ti segnalo una start-up, che non ha ancora ricevuto investimenti, ma che sta cercando di fare business in maniera decisamente innovativa. La start-up si chiama PromptBase ed è un marketplace di prompt, sostanzialmente breve testo, che si dà in ingresso a sistemi come quello di Dall-E per generare immagini specifiche. L'idea è quella di fornire a un sistema di intelligenza artificiale delle "linee guida" o delle istruzioni dettagliate in modo che, attingendo alla sua conoscenza del mondo, possa realizzare in modo affidabile ciò che gli viene richiesto. La scommessa della start-up è che questo processo di generazione abbia delle specificità tali da rendere l’acquisto di questi script efficiente sia in termini qualitativi che di risparmio di tempo. Ci sono anche aspetti legali non chiarissimi in queste nuove modalità di scambio e utilizzo commerciale di questi testi ma intanto quello che era solo a Giugno 2022 un piccolo e marginale progetto di un programmatore è diventato realtà. E nel mese di ottobre sono sicuro che abbia fatturato 1,99 dollari visto che le immagini che vedete sotto le ho generate proprio acquistando un prompt (a tema gatto e non solo …) da PromptBase. Se questa start-up sia una follia (dal punto di vista della sostenibilità) o possa avere un futuro lo scopriremo solo vivendo! Comunque chi gestisce investimenti nel nostro ambito deve tenere oggi ben presente tutto quello che ruota attorno ai modelli generativi.

👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. AI TRiSM & Adaptive AI: Gartner 2023 predictions for the world of AI & Data
Ogni anno, verso la fine di Ottobre, puntuali come il piatto di Natale della Royal Copenhagen e il calendario dell’avvento, le previsioni dei trend tecnologici del 2023 ci annunciano la fine dell’anno e anticipano le riflessioni per il futuro. Gartner è un’azienda unica, con un punto di vista completo sul presente e una buona vista sul prossimo futuro. Mi piace definirli “i notai dell’innovazione incrementale” perché raramente ho visto loro previsioni, su argomenti molto “disruptive”, azzeccate ma sicuramente aiutano a valutare trend importanti in corso. Per questo ti segnalo l’uscita della previsione dei 10 trend tecnologici del 2023, realizzata proprio da Gartner, e ti consiglio di leggerla con attenzione. Tra i 10 di quest’anno ce ne sono due che riguardano l’intelligenza artificiale e in particolare:
1) Quello che loro chiamano AI TRiSM (AI Trust Risk & Security Management): cioè la crescita di importanza dei metodi per spiegare i risultati dell’AI, per distribuire rapidamente nuovi modelli, per gestire attivamente la sicurezza dell'AI e per controllare la privacy e le questioni etiche.
2) Adaptive AI: che con, una traduzione un po’ azzardata, definirei intelligenza artificiale adattiva che consente di modificare il comportamento dei modelli dopo l'implementazione. Il tutto utilizzando il feedback in tempo reale, per migliorarli e apprendere continuamente sulla base di nuovi dati e obiettivi, modificati per adattarsi rapidamente alle mutevoli circostanze del mondo reale.
🖐️Tecnologia (data engineering). Cosmograph: a quick and easy way (library) to visualize (not too) big networks within seconds!
Visualizzare bene e in maniera semplice grafi complessi (tanti nodi e relative relazioni) è un problema importante nel mondo dell’analisi dei dati e non di facile soluzione. La soluzione che ti propongo di provare, se hai un grafo grande ma non grandissimo, è una libreria uscita a fine estate: Cosmograph capace di rappresentare fino a 1 milione di nodi e più di un milione di relazioni. Lo fa in maniera abbastanza innovativa sfruttando la potenza della GPU del tuo processore e utilizzando uno specifico algoritmo (GPU-accelerated Force Layout) lasciando quindi i dati in locale. Se vuoi avere più dettagli tecnici, li puoi trovare qui così come le istruzioni per preparare un semplice CSV e per provare il tutto in pochi minuti. Io l’ho fatto e ho trovato interessante il risultato, se confrontato con altre librerie, provate in passato, soprattutto per la sua estrema praticità. Ci sono comunque anche esempi molto chiari sul sito della stessa libreria sia tratti da contesti reali (mondo crypto) sia utilizzando grafi “sintetici”.
👀 Data Science. The State of Data Science and Machine Learning 2022 (from the most important datascientist community in the world: Kaggle)
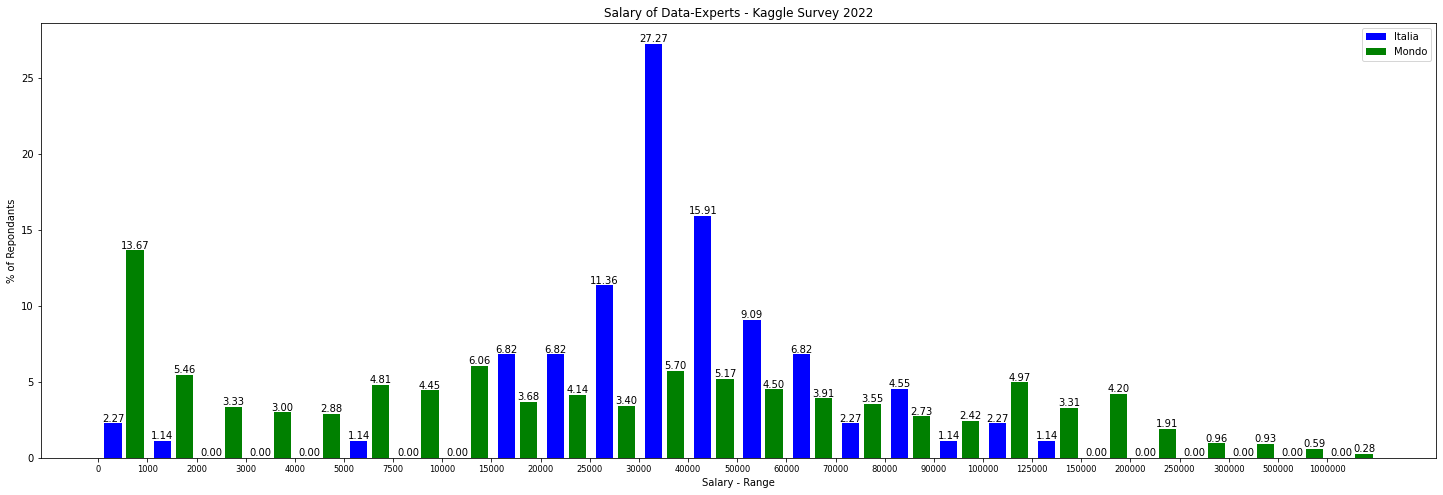
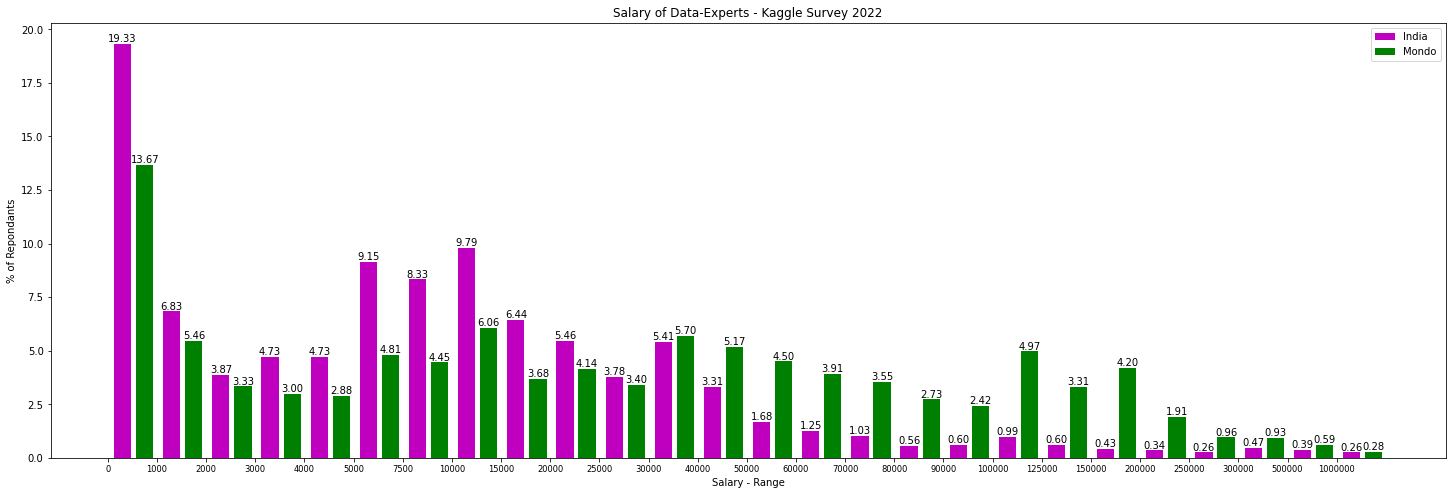
Kaggle è sicuramente la più importante e numerosa comunità di datascientist al mondo. Dichiara ad oggi più di 11,2 milioni di iscritti provenienti da 194 paesi diversi. Ha acquistato gradualmente importanza nei suoi 12 anni di storia grazie alla convergenza, sulla sua piattaforma, di competizioni ben remunerate dalla più importanti aziende nel mondo, di un ambiente dove di possono avere gratuitamente strumenti (notebook) e computazione e più recentemente di una sezione dedicata esplicitamente all’apprendimento strutturato. L’acquisizione da parte di Google 5 anni fa ha chiaramente accelerato questa crescita. Ogni anno dal 2017 a Settembre Kaggle conduce un questionario di indagine tra i suoi iscritti, utile a capire diverse variabili: tecnologiche, organizzative ed economiche nel mondo della datascience. Ogni anno la leggo con molta attenzione perché aiuta a capire i trend in corso e quelli che stanno nascendo. Essendo, la compilazione, su base volontaristica ha un bias di selezione dei partecipanti significativo e comunque gli iscritti a Kaggle non possono essere considerati un campione fedele della popolazione dei data-expert mondiale, sopra campionando, a mio parere, la fascia alta. Nonostante questo le circa 24.000 persone che hanno partecipato all’indagine 2022 offrono parecchie informazioni e tra l’altro è stato rilasciato il dataset completo con tutte le domande e le risposte: lo puoi trovare qui come fosse una reale competizione di Kaggle. Se hai poco tempo puoi vedere l’executive summary dove ci sono però solo alcune domande ma un utile confronto con gli anni passati. Personalmente ho analizzato in dettaglio tutte le domande e ho trovato tanti spunti interessanti su base geografica e tecnologica. Troppo lungo fare una sintesi qui. Ti lascio comunque le immagini, tratte dal mio notebook, della distribuzione del salario rispetto al campione totale per i rispondenti indiani (8792 al questionario non specificatamente a questa domanda), americani (2920) e italiani (182). Lascio a te osservazioni e commenti ma media e mediana del salario spiegano molto della cultura e della fase di sviluppo di queste tre nazioni molto diverse tra loro. I numeri, per gli Stati Uniti, sono peraltro allineati (parlando di mediana) con quelli pubblicati in un altro recente autorevole articolo segnalatomi da un amico e lettore della newsletter. Probabilmente farò in futuro un post specifico sull’analisi puntuale delle domande perché gli spunti sono tantissimi. Se hai curiosità specifiche scrivimi pure (st.gatti@gmail.com) e cercherò di soddisfare la tua curiosità!

PS: se sei curioso di vedere come ha saputo competere un "kaggler" italiano con la passione per i dati finanziari con i più esperti "quant" ti consiglio di seguire giovedì prossimo 10 Novembre il meetup on-line di Kaggle Days Milano. In questo talk Davide Stenner racconterà come è riuscito a piazzarsi in 2a posizione (su quasi 3.000 partecipanti!) nella previsione dell'andamento di diverse tipologie di investimenti.
👅Etica & regolamentazione & impatto sulla società. 10 Things You Should Know About AI in Journalism
Mattia Peretti è un esperto di giornalismo di nazionalità italiana che gestisce JournalismAI, un progetto di ricerca e formazione presso Polis, il think tank giornalistico internazionale della London School of Economics, che aiuta le testate giornalistiche a utilizzare l'intelligenza artificiale e farne un uso responsabile. Il progetto è fatto veramente bene e, se tu sei un giornalista o comunque ti occupi di creare contenuti a carattere informativo, dovresti assolutamente leggere questo breve saggio, scritto in 10 punti sul Global Investigative Journalism Network da Mattia, che sintetizza le sue esperienze sul campo usando e sperimentando software che dovrebbero sempre di più facilitare l’attività quotidiana di ogni giornalista. Ci sono passaggi che andrebbero letti da chi scrive o parla in qualunque contesto proprio su tematiche legate ai dati e agli algoritmi. Ve ne segnalo due ma non ritenete il mio elenco esaustivo:
1. L'IA non è ciò che pensi: “ …Ogni volta che leggi "IA" - o scrivi "IA" nei tuoi articoli se sei un giornalista - fermati per un secondo a pensare a quale altra parola potrebbe sostituirla in quella frase. Forse è la parola algoritmo, o automazione, o software. Quel piccolo esercizio di sostituzione aiuterà la tua comprensione e anche i tuoi lettori …”
2. L'IA non ti sta rubando il lavoro: “ … La verità è che l'intelligenza artificiale non è così intelligente come dovrebbe essere per sostituirti. Può portare via alcuni compiti che normalmente svolgiamo. Ma siamo noi a decidere quali sono questi compiti, in base a quali strumenti decidiamo di costruire con l'IA. Non è un caso che, nel contesto del giornalismo, l'IA attualmente svolga per lo più compiti noiosi e ripetitivi che comunque non ci piace molto fare. Cose come trascrivere interviste, vagliare centinaia e centinaia di documenti trapelati , filtrare i commenti dei lettori, scrivere la stessa storia sui guadagni finanziari delle aziende, per centinaia di aziende, ogni tre mesi. Nessuno è entrato nel giornalismo perché non vedeva l'ora di fare queste cose …”
Ma c’è molto altro nel saggio di Mattia e se anche non sei un giornalista ma sei un data-lover i suoi consigli ti potranno essere molto utili!
E’ giusto ringraziare (almeno ogni tanto) le persone che mi aiutano a rendere questa newsletter migliore sia dal punto di vista tecnico che dal punto di vista della leggibilità e scorrevolezza: Grazie Alberto! Grazie Federica! Grazie Guglielmo!
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!