

LaCulturaDelDato #035
Dati & algoritmi attraverso i nostri 5 sensi

Ciao,
sono Stefano Gatti e questo è il trentacinquesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del trentacinquesimo numero:
👃Investimenti in ambito dati e algoritmi. Start of the month - October 2022. Vara: data-driven breast cancer screening
Come ogni mese, sfruttando un’attività che sto facendo per studiare il mercato dell’innovazione e degli investimenti, ti segnalo la start-up internazionale che più mi ha più colpito e che ha avuto un funding nel mese. Come detto questa start-up deve lavorare in ambito dati e algoritmi o farne largo uso (avere al suo interno o nelle selezioni in corso un numero significativo di data-expert). Tra le 79 start-up classificate come “data & algorithms” in Ottobre (sulle 588 visionate cioè circa l’13,5%) ti segnalo Vara, un’azienda fondata nel 2018 all’interno di Merantix, un Venture Studio situato a Berlino e specializzato nel costruire, supportare e far scalare start-up che sfruttano sistemi di intelligenza artificiali in differenti ambiti. Varda in particolare, che ha chiuso recentemente un series A da 15 milioni di dollari, si concentra nel settore della radiologia medica ed in particolare applica il suo algoritmo per migliorare la classificazione delle mammografie.
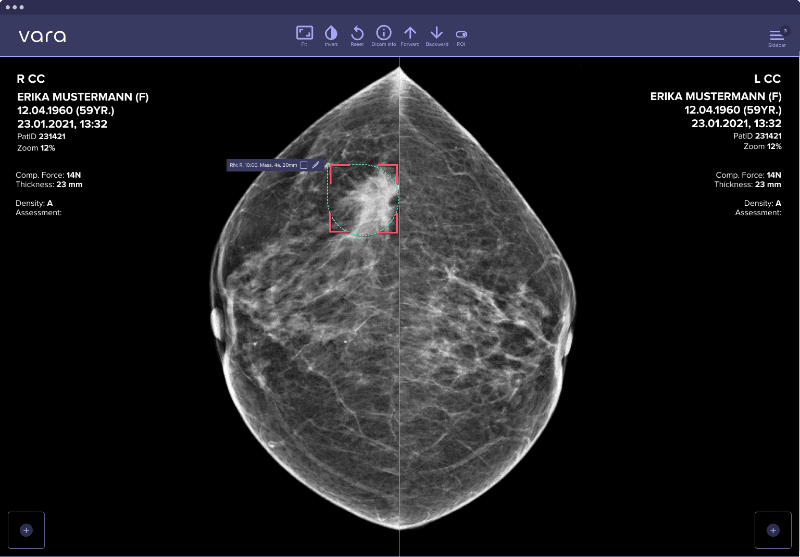
Vara non è un semplice software complementare agli attuali ma è stato progettato come sistema che segue tutto il flusso dello screening mammografico e si integra molto bene con le attività del radiologo. A seconda delle varie geografie dove viene usato può sostituire il radiologo fornendo una classificazione del livello di rischiosità emerso dalle immagini, soprattutto nei paesi in via di sviluppo, o può fornire un servizio di verifica post classificazione del medico per recuperare potenziali errori di valutazione. Combinando le capacità umane e quelle dell’algoritmo si è stimato che abbia migliorato del 2,6% la qualità della decisione umana eliminando anche un alto numero di falsi positivi. Questo è l’approccio di “augmented intelligence” che preferisco e che ritengo vincente almeno nel medio periodo!
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Data Engineer 101
Una delle figure, nel mondo dei dati, che si è rilevata più importante e strategica, soprattutto dopo l’hype della figura del datascientist, è quella del data engineer. Questo ruolo non è però ancora così chiaro e definito all’interno delle organizzazioni e mi è capitato più volte di averlo visto confuso con quello del machine learning engineer, del data analyst o addirittura del datascientist. Per questo, soprattutto se ti occupi di selezione del personale, è importante che tu legga questo articolo, del famoso blog “The Pragmatic Engineer” che definisce in maniera semplice ma non banale quali sono le attività, i tools e i contesti dove si muove questa figura. Lo fa riportando l’esperienza diretta di un data engineer di esperienza internazionale che ha svolto questa professione anche in Facebook. La chiarezza delle sue parole mi hanno colpito molto anche perchè si adattano benissimo al ruolo svolto con efficacia in tutte le realtà, di qualunque grandezza e geografia, in cui mi sono imbattuto. Che cosa fa un data-engineer, quali sono gli artefatti chiave del suo lavoro e perché sta diventando così importante: queste sono le tre domande a cui risponde molto bene Benjamin Rogojan. E soprattutto, scendendo nel concreto, Benjamin esprime i tre obiettivi primari della sua attività: rendere i dati facilmente utilizzabili dagli altri data-expert, dare ai dati e a chi li usa una prospettiva temporale di lungo periodo e soprattutto renderli integrati tra loro e con le strutture informatiche dell’organizzazione. C’è molto altro nell’articolo e anche se non sei un esperto di tecnologia non aver paura a leggerlo perché imparerai molte cose e ti aiuterà a capire e a dialogare meglio con chi svolge questo ruolo sempre più importante all’interno delle organizzazioni moderne.
🖐️Tecnologia (data engineering). Confidential Computing and Machine Learning
Quando si parla di confidenzialità e integrità dei propri dati le aziende devono saper gestire in maniera sicura tutti e tre gli stati all’interno del ciclo di vita del dato stesso: in transito, a riposo e durante il suo utilizzo. Quando si parla dei primi due stati le metodologie applicate sono più vicine a quelle della sicurezza del software tradizione. Se invece ci concentriamo sulla fase di utilizzo del dato le tecniche sono molto più vicine al nostro mondo o meglio operano proprio direttamente sugli stessi dati e algoritmi. Per incominciare a conoscere almeno le famiglie di tecnologie oggi disponibili o, se le conosci già, per approfondire i trend di popolarità ti consiglio vivamente questo post di Ben Lorica che lo fa usando una metodologia simile a quella del Tiobe Index (ricordi? te ne ho già parlato a proposito di misurazione di popolarità dei linguaggi di programmazione). Tra le famiglie di tecnologie quella dei dati sintetici la fa da padrone ma non risolve tutti i casi d’uso per estrarre valore dai dati. La Secure Multiparty Computation, di cui ho fatto positiva esperienza in passato, e anche l’Homomorphic Encryption promettono di essere molto interessanti se riusciranno ad estendere le casistiche gestite, consentendo l’utilizzo di tutte le tecniche di machine learning senza dover accedere in chiaro al micro-dato. Serve però un alert su questo tema: nessuna di queste due ultime tecniche supera eventuali vincoli legislativi di non usabilità del dato né è capace di cambiare l’opinione degli uffici interni di compliance soprattutto se non li si aiuta fino in fondo a capirne i benefici.
👀 Data Science. Python and Data Science in every branch of human knowledge: economics, literature and more!
Per darti un’idea, se ancora non te la sei fatta, di quanto pervasivi Python e la Data Science stanno diventando in ogni area di sapere oggi ti propongo alcuni link e risorse aperte che in giro per il mondo, prevalentemente in quello universitario, studiosi ed esperti stanno mettendo a disposizione di tutti noi. Questo ha un immenso valore soprattutto per le giovani generazioni perché queste risorse sono di alta qualità, alta accessibilità (perché aperte) e di facile fruibilità perché partono dai concetti base ma hanno contenuti anche di alta complessità e specificità. Queste risorse sono, come usano dire gli anglofoni, “low floor and a high ceiling”. Incominciamo dalla prima segnalazione, forse quella che preferisco: “Coding for economists”. Il progetto ha una completezza di spiegazione di tutte le componenti di Python per la data analysis che ho raramente trovato in altri testi. Ma anche nelle parti più specifiche la qualità si mantiene altissima come per esempio quando si addentra a spiegare come si scrivono paper in maniera moderna.
Anche in area umanistica, soprattutto nel mondo anglosassone e nordico, il coding e le sue metodologie per analizzare i documenti stanno prendendo sempre più piede. Un esempio è questo progetto aperto dove ovviamente Python e le sue tecniche di analizzare il testo (NLP) la fanno da padrone. Quello che mi ha impressionato, provandone alcune parti, è la ricchezza di esempi che ne fa uno strumento molto pratico per “moderni letterati”. Sempre nello stesso ambito ma più orientato ad una introduzione al coding per umanisti è ”Python for digital humanities”. Per finire ti segnalo, se sei un appassionato di dati geospaziali, questo progetto che fornisce gli strumenti, i metodi e la teoria per affrontare le sfide della scienza dei dati contemporanea applicata ai problemi e ai dati geografici.
I realizzatori di questi progetti, per l’impatto sul futuro della distribuzione della conoscenza, sono i veri filantropi del 21° secolo.
👅Etica & regolamentazione & impatto sulla società. Italian and European Olympic games of statistics (as an entrance test for managers in a company)
Tornano, come ogni anno, le Olimpiadi italiane di statistica, competizione destinata agli studenti delle prime quattro classi delle secondarie superiori, divisi in due categorie: 14-16enni e 17-18enni. Il tutto mi arriva dalla puntuale newsletter dell'Istat che vi consiglio di seguire perché decisamente informativa su quanto produce il nostro ente di Statistica, le cui attività, i cui lavori e i cui dati sono troppo poco seguiti e utilizzati a livello nazionale. Ed ora una call to action e una provocazione:
1) Se qualche insegnante, non necessariamente di matematica mi segue, le consiglio vivamente di far partecipare i propri studenti a questo evento perché è un investimento per il loro futuro. Si tratta di un esercizio non solo di statistica in senso stretto ma anche logico e di comprensione del testo: provate un test, magari per il 3° e 4° anno, e controllate le soluzioni per conferma! C’è tempo fino al 21 Novembre. In alternativa usatelo per un'esercitazione (anche senza voto … che non è lo scopo della didattica) per stimolare i vostri alunni.
2) La provocazione, invece, è che userei l’esame come test di ingresso per qualunque manager (e dico manager perché voglio essere particolarmente provocatorio …) che entri oggi in azienda e fisserei una soglia non troppo alta: diciamo 10 risposte corrette sui 20 quesiti del test. Potremmo vederne delle belle. Vi consiglio di provarlo. Ci vogliono 40 minuti. Non tutte le domande sono scontate così come l’esercizio di comprensione dei testi delle domande stesse. Io ho fatto quello del 2022 e non ho ottenuto 20/20 ma ci sono andato vicino. Qui trovate il testo e qui la soluzione. Non siate timidi e fatemi sapere cosa pensate della proposta ;-)
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!