

LaCulturaDelDato #062
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il sessantaduesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del sessantaduesimo numero:
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Grasping the AI Zeitgeist: Readiness and Adaptation in Modern Enterprises
Nonostante debba essere presa con cautela, poiché rappresenta principalmente un campione americano e proviene da un'azienda del settore, ritengo interessante segnalarti questo report che esamina il presente e il prossimo futuro dell'adozione dei sistemi di AI all'interno delle aziende. Data l'attuale situazione, l'attenzione è principalmente sulla Generative AI, ma molti temi sono comuni anche ad altri sistemi di intelligenza artificiale. Ciò che emerge e che mi sento di condividere pienamente è che "i manager delle aziende stanno rapidamente comprendendo che non si possono adottare questi sistemi e aspettarsi di ottenere un vantaggio commerciale unico: è necessario addestrarli per soddisfare le specifiche esigenze aziendali, utilizzando i propri dati... così come sono forti le preoccupazioni relative alla sicurezza e alla privacy". Emerge chiaramente la consapevolezza che i prossimi 2 o 3 anni saranno strategici per come l'AI verrà utilizzata nei rispettivi ambiti, probabilmente per decenni. Tuttavia, emergono temi già critici all'interno delle organizzazioni, quali la gestione della qualità dei dati e le competenze interne per gestire questa transizione. E sulla capacità di guidare con risorse interne questo passaggio credo, come abbiamo scritto nella “Cultura del Dato”, si giochi la partita e il futuro di molte aziende. È sempre stato così, ma come in tutti i momenti di grande cambiamento, questa capacità farà ancora di più la differenza. Non basta, come emerge dallo studio, aumentare i budget all'interno delle aziende per cogliere il valore di questa trasformazione. Non è un caso che (pagina 12 dello studio) due risorse che le aziende ritengono di non avere sono la cultura aziendale e l'esperienza interna, intesa soprattutto come talenti che sapranno gestire la transizione. Ancora una volta, nel corso della storia, sono i talenti umani a essere scarsi nelle organizzazioni e non la tecnologia e le risorse economiche. Tutto il resto, come sempre, lo trovate nelle slide della presentazione, utili ma che da sole non generano cambiamento 🙂.
🖐️Tecnologia (data engineering). Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
Ci sono tre modi in cui puoi sfruttare il consiglio di approfondimento di oggi. Tutti e tre sfruttano il lavoro di un gruppo di esperti provenienti da Amazon, Rice University e Texas A&M University. Te li presento in base al tempo che potresti voler dedicare a ciascuno.
Il primo è molto visuale e rappresenta una sorta di albero genealogico dei modelli linguistici di ultima generazione, a partire dal 2017. È realizzato molto bene e, se sei già un po' familiare con l'argomento, potrebbe aiutarti a ripassare l'evoluzione di questi modelli e la loro suddivisione nelle varie macro-categorie. Forse (#sischerza) tra 100 anni questo albero potrebbe spiegare ad alieni atterrati sulla Terra l'evoluzione dell'Homo sapiens sapiens verso l'Homo ChatGPT 🙂
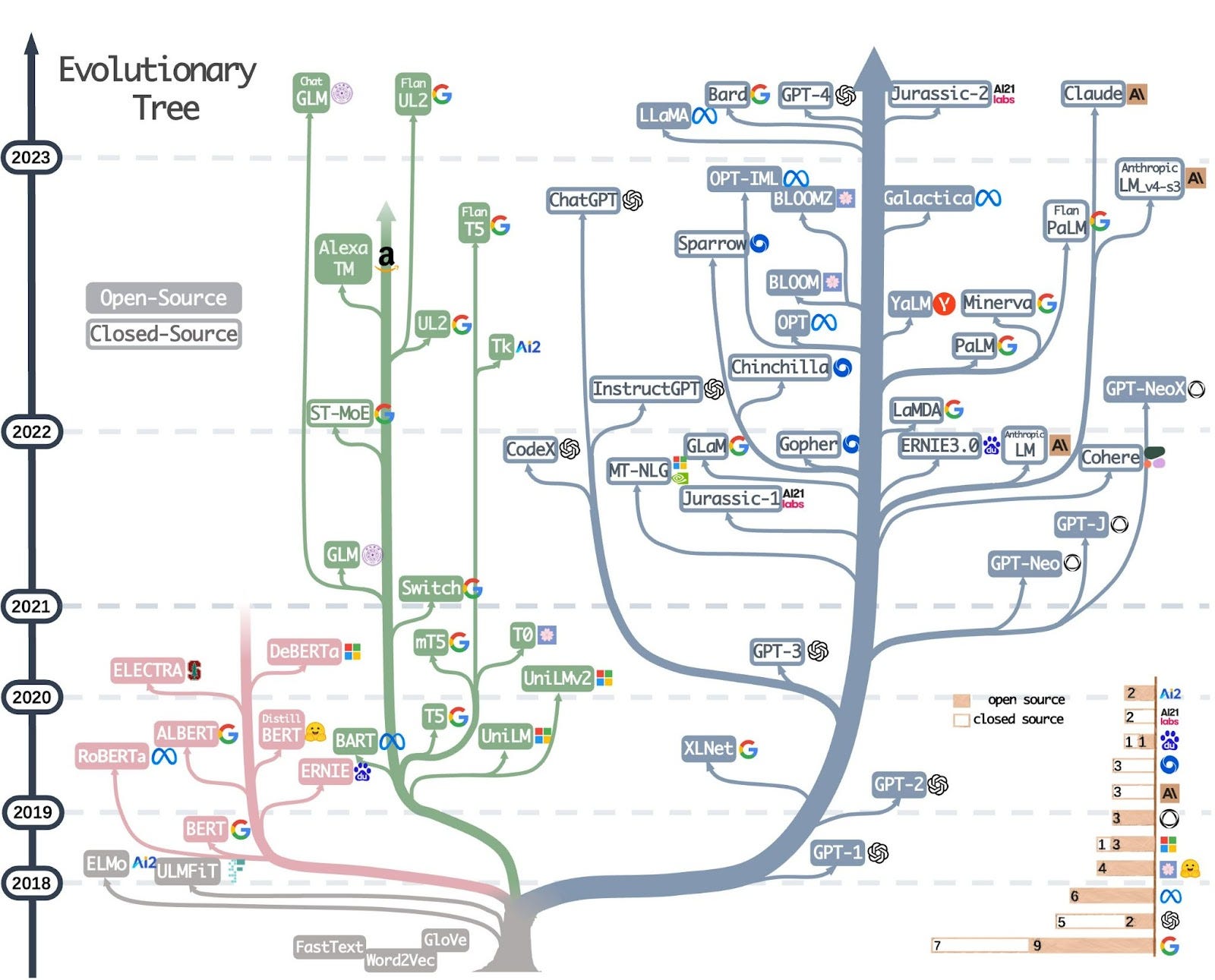
Il secondo metodo richiede un po' più di tempo: leggere il paper pubblicato a fine aprile, dal quale ho tratto l'immagine sopra. Questo documento è lungo 24 pagine e non è troppo complesso. Oltre a delineare l'evoluzione dei vari modelli, spiega molto bene i diversi tipi di compiti che questi modelli possono svolgere (dal Natural Language Understanding alla Reasoning Ability) e, soprattutto, illustra i casi d'uso, particolarmente rilevanti in ambito aziendale, che riescono a risolvere meglio.
Il terzo metodo, utile anche per rimanere aggiornato, consiste nel seguire l'area Github del progetto (The Practical Guides for Large Language Models), dove troverai tutte le informazioni presenti nel paper, ma in modo molto più dettagliato, con molti riferimenti storici che hanno contribuito all'evoluzione attuale.
👀 Data Science. SQL-ly Entertaining: Level Up Your Skills with This Fun Learning Game!
Questa settimana torno alle origini e ti segnalo una risorsa molto divertente per tenerti in allenamento o anche migliorare con lo strumento più diffuso tra i data expert, ovvero il buon vecchio SQL, "50 anni e non sentirli"… come abbiamo scritto Alberto ed io in un approfondimento dedicato a questo linguaggio in Data Culture. Sì, l'aspetto del divertimento, se mi seguite da un po' di tempo, è per me centrale nell'apprendimento. Per questo, "Lost at SQL: The SQL Learning Game" è uno strumento imperdibile: una story adventure dove progredisci superando sfide a colpi di SQL. Puoi giocarci in due modalità, in realtà: in modalità apprendimento, che è il modo più facile e dedicato a chi vuole imparare a piccoli passi, e in modalità sfide, dove, in funzione del tuo livello che puoi testare in partenza, avanzi nella storia solo se risolvi quesiti usando SQL in modalità abbastanza avanzata. Se poi non ti basta l'SQL, sempre prodotto dall'eclettico Robin Lord, trovi un altro learning game tutto basato sulle Regex. E l'ultimo suggerimento che ti fornisco è quello di seguire il suo blog, tecnico e pratico allo stesso tempo, dove puoi trovare suggerimenti come questo, che ti consiglia come usare al meglio Google Colab, definito in maniera simpatica e molto azzeccata da Robin come "Google Docs but for Python".
👃Investimenti in ambito dati e algoritmi. (Not Only) The Economics of Large Language Models
Una delle domande che molti investitori si pongono di fronte all'avvento della Generative AI è chi e come si approprierà della parte sostanziale del valore generato. Ti avevo condiviso diversi articoli in questi mesi sulle varie opinioni, ma al di là delle sfumature prevale una grande incertezza. L'articolo che ti consiglio oggi è un'approfondita analisi del costo dell'utilizzo dei LLMs ( i calcoli sono fatti principalmente su GPT-3 ) confrontandoli con quelli di una ricerca standard effettuata su Google. L'opinione generale è che il futuro della ricerca sarà l'integrazione dell'attuale con gli LLMs. È ciò che sta facendo Microsoft con Bing, e ci sono già diversi esempi in giro. Tuttavia, non sono convinto che questo debba essere necessariamente l'unico futuro possibile e, anzi, ritengo che la ricerca puntuale a cui siamo abituati su Google sia qualcosa di non facilmente sostituibile e/o integrabile con gli LLMs, se non altro per una questione di UX. Ti lascio anche alcune personali osservazioni che emergono anche dalle più recenti evoluzioni dei casi d'uso:
Il valore dei dati proprietari o dello specifico dominio diventa sempre più importante per use-case efficaci, soprattutto con l'affinamento delle tecniche di fine-tuning che si appoggiano agli attuali LLMs.
La diminuzione dei costi sia di training che di elaborazione delle inferenze è sempre più accentuata e potrebbe rendere lo strato degli LLMs quasi una commodity, soprattutto in abbinamento con l'uscita di soluzioni open source.
A livello di investimento il confronto non va fatto solo con la ricerca di Google, che è solo uno dei tanti use case degli LLMs, ma con le attività operative e i processi che va a sostituire o alleggerire. E questa analisi è molto legata al settore industriale, anche per una questione non secondaria legata alla regolamentazione.
Credo che il valore di questi sistemi, a differenza di quanto è stato per la ricerca (di Google) nei primi anni 2000, sarà meno disintermediato dalla pubblicità e molto più pay-per-use.
Vedremo quante di queste mie osservazioni/previsioni saranno corrette e non ci vorrà molto tempo per verificarlo …
👅Etica & regolamentazione & impatto sulla società. Revolutionizing AI Agents: Unleashing the Power of GPT-4 for Enhanced Interactions
Ti avevo già parlato qualche settimana fa dell'importanza che sta assumendo, all'interno dell'evoluzione della generativa AI, l'interazione tra diversi agenti AI, ossia “dei bot potenziati da GPT-4 in grado di completare compiti mediante analisi, ricerca e assimilazione di informazioni dal web”, come scrive Andrea Zurini nell'approfondimento che ti suggerisco in questa sezione. La lettura del post è molto scorrevole e si presta a diversi livelli di lettura, offrendo anche spazio a utili approfondimenti tecnici se si desidera testare o avere un'idea di questa tecnologia senza dover scrivere troppe righe di codice. Ho effettuato alcune prove con sistemi di questo tipo e devo dire che, pur considerandoli molto promettenti, li ho ancora trovati acerbi. In particolare, manca ancora quella fluidità di integrazione con i vari servizi di ricerca e informazione presenti sul web, che è necessaria per ottenere risultati decisamente superiori a quelli che possiamo ottenere in modo più deterministico noi umani. L'evoluzione e l'efficacia di questi agenti dipenderanno dall'accesso a servizi di terze parti che possano garantire anche la qualità informativa necessaria per molte attività di ricerca e sviluppo. Ciò potrebbe favorire anche ecosistemi e mercati di dati e informazioni “certificate” in grado di interagire in modo strutturato con questi sistemi di agenti per generare conoscenza strutturata e ricorsiva... che è un po' il sacro Graal del progresso.
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!