

LaCulturaDelDato #070
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il settantesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del settantesimo numero:
🖐️Tecnologia (data engineering). Mastering Feature Engineering: Unlocking the Power of Data for Business and Data Science
"Il feature engineering si riferisce al processo di trasformazione dei dati in rappresentazioni utili (features) per migliorare il modello, ridurre il costo computazionale e migliorare l’interpretabilità" - questa è la definizione, molto completa, che fornisce l'approfondimento sul feature engineering che ti suggerisco oggi. L'ho trovato particolarmente interessante perché non solo fornisce una descrizione completa di questo processo nelle sue fasi principali, ma lo colloca anche all'interno delle attività di data science che si svolgono in azienda, delineando l'intero ciclo di vita. Credo che questa fase sia spesso sottovalutata in molti progetti rispetto alla sua rilevanza. Trovandosi tra la fase di ricerca e studio dei dati e l'integrazione nei modelli, è spesso gestita a quattro mani dai data scientist e dai data engineer, rischiando di perdere una vera titolarità. Invece, una buona gestione del feature engineering permette di costruire una vera "piattaforma", arrivando al concetto moderno di feature store, su cui si possono costruire agilmente molti progetti e che può essere abilitante nella fase di creazione di nuovi.

Questo è ancora più vero quando i progetti di data science non sono attivati solo attraverso lineari flussi di "demand" che dal business vanno ai data scientist e poi all'IT, ma attraverso diverse modalità, anche spesso molto serendipiche, come mostra concretamente il grafico, tratto dalla guida, che ho riportato sopra. Ci sono molti motivi per leggere questa guida, anche squisitamente tecnici, ma il principale è che sembra nascere e quindi rispondere a decenni di problematiche vissute sul campo in progetti di data science non sempre perfetti 🙂. Se invece sei interessato specificamente alla fase del data wrangling, questo contributo mostra come le stesse operazioni possano essere eseguite in diversi linguaggi di programmazione, da Python fino ad arrivare ad Excel…
👀 Data Science. (Not Only) Preparing for Your Data Science Interview: Insights and Useful Resources
Prepararsi per un colloquio di lavoro non è un'attività banale e spesso solo attraverso l'esperienza si apprendono quali sono le caratteristiche personali che necessitano di maggiore allenamento. Soprattutto nelle fasi iniziali della carriera di un data-expert, una parte del colloquio ruota attorno alla conoscenza tecnica, spesso contestualizzata nell'area e nei metodi di lavoro dell'azienda in cui si ambisce lavorare. Ricordati che valutare le domande che ti vengono fatte, incluso quelle tecniche, può darti una comprensione del contesto e del lavoro che andrai a svolgere molto più della lettura dell'annuncio stesso o della descrizione che ti viene data durante il colloquio stesso. Se vuoi essere preparato per le domande più comuni e desideri investire tempo per ripassare o approfondire alcuni concetti di data science che potresti aver affrontato solo parzialmente, il progetto di Youssef Hosn, un esperto data scientist e appassionato formatore, potrebbe esserti d'aiuto. Troverai infatti, suddivise in sei ambiti, alcune delle domande più frequenti durante un colloquio per una posizione da data scientist. Oltre alle domande, ci sono anche le risposte con link molto utili. Anche se non stai per affrontare un colloquio di lavoro, utilizzare questo progetto potrebbe essere un modo per studiare alcune tematiche molto utilizzate oggi all'interno delle aziende.
Anche le soft skills sono importanti durante un colloquio e in molti momenti della vita aziendale. Saper presentare i propri progetti e i risultati raggiunti è di fondamentale importanza. Per fare ciò, ti consiglio di dare un'occhiata a questo framework in dodici semplici, ma non banali, passaggi presentati dal sito storytellingwithdata.
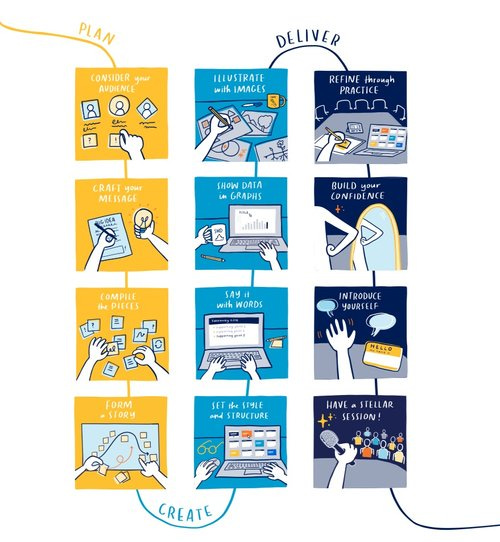
Tutti sono importanti, ma il primo: "conosci la tua audience", è sicuramente quello da cui partire e a cui dedicare più tempo. Questo vale anche durante un colloquio, che alla fine non è altro che presentare il progetto di vita professionale, non solo quella passata, a persone che non conosci (bene).
👃Investimenti in ambito dati e algoritmi. Predicting the Future of Value Generation in Generative AI Architecture: A Look at LLMs, Infrastructure, and Applications
Non è assolutamente facile né scontato prevedere quale dei tre livelli di cui si compone l'architettura standard della AI generativa sarà in grado di generare più valore nel tempo. I Large Language Models (LLMs come OpenAI, Cohere, ecc.), le infrastrutture (come HuggingFace, Replicate, LangChain, ecc.) e le applicazioni (come Jasper, Github Copilot, ecc.) si muoveranno in contesti molto complessi e dinamici per diversi anni. Tuttavia, si cominciano a delineare le prime tendenze. Ritengo che i due strati inferiori (LLMs e Infrastrutture) seguiranno un modello di sviluppo economico più vicino a quello delle piattaforme del Web 2.0.
Per quanto riguarda le applicazioni, trovo particolarmente convincente lo scenario delineato da Paris Heymann, partner del fondo di investimento Index. In un post su LinkedIn e più in dettaglio nell'articolo correlato (sotto paywall) su TechCrunch+, Heymann ipotizza che "la prossima iterazione del Vertical SaaS (software as a service per specifiche necessità) sarà il Vertical AI: piattaforme di AI focalizzate su settori specifici, costruite sulla base di modelli addestrati in modo esclusivo su set di dati specifici del settore". In questo senso, Heymann intravede due possibili evoluzioni:
1) Nuove applicazioni verticali native dell'AI generativa che guadagnano credibilità andando a soddisfare bisogni specifici.
2) I leader SaaS verticali esistenti incorporano funzionalità AI nei loro prodotti per i loro clienti.
Aggiungo io, le acquisizioni da parte dei leader di nuove applicazioni appena sviluppate potrebbero rappresentare una terza via. Tuttavia, l'integrazione tecnologica non è al momento così agevole da rendere questa possibilità concreta su larga scala.
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Shaping Leadership in Modern Organizations: Trends and Challenges in the Era of Generative AI
Negli ultimi 20 anni, il dibattito su come la leadership stia cambiando nelle organizzazioni moderne, sempre più fluide, si è intensificato. L'avvento dell'AI generativa, se possibile, ha ulteriormente accelerato questo processo. Se desideri leggere un contributo che offre una buona sintesi senza cadere nel tecno-narcisismo tipico della costa ovest americana, questo post di Giorgio Fatarella rappresenta un buon punto di partenza.
Sono convinto che ci siano alcune caratteristiche con cui la leadership si sta già confrontando e che diventeranno ancora più importanti in futuro. Queste caratteristiche emergono da tendenze che i dati ci stanno indicando da un po' di tempo, ma i cui effetti sono così lenti che tendiamo colpevolmente a subirli più che ad adattarci attivamente. Mi riferisco in particolare a tre macro fenomeni:
1. Modalità diverse di lavoro, come:
- La convivenza di molteplici generazioni di lavoratori profondamente diverse tra loro, un fenomeno accentuato dalla riduzione della natalità e dall'aumento della vita media in tutte le regioni del mondo.
- Modalità ibride di lavoro (remoto e in presenza) a cui la pandemia da Covid-19 ha dato un'accelerazione molto forte.
- L'interazione con intelligenze non solo umane, un fenomeno accentuato dalla AI generativa ma già presente fin dall'inizio del millennio.
2. L'importanza crescente della diversità e della trasversalità dei saperi all'interno dei team e delle organizzazioni. Le persone T-shape sono e saranno i veri protagonisti del cambiamento e della gestione della diversità. Tuttavia, l'aumentata frammentazione del sapere rende la loro esistenza ancora più complessa.
3. Innovazione continua e poco prevedibile. Ogni ruolo di leadership deve e dovrà sempre più saper gestire, facilitare, “formare” e guidare il cambiamento. Il mondo dei dati non fa certamente eccezione, come abbiamo cercato di illustrare nel ciclo di isteresi del Chief Data Officer nel libro scritto con Alberto Danese “La Cultura del Dato”. Questo ruolo dovrà sempre più essere orientato all'innovazione piuttosto che alla governance.
Prendi queste mie riflessioni come gli appunti sparsi di un viaggiatore... pronti a sbiadire al prossimo acquazzone!
👅Etica & regolamentazione & impatto sulla società. Let's Focus More on the 'How' than the 'If' in the Use of Generative AI
Trovo affascinante come stiano emergendo forti dibattiti sull'uso dell'intelligenza artificiale generativa. Tali questioni avrebbero dovuto sorgere con lo stesso vigore anche per l'IA non generativa, ampiamente utilizzata dalla metà degli anni 2000.
Vorrei condividere alcuni esempi e riflessioni recenti che ho trovato particolarmente rilevanti.
Cominciamo dal dibattito che sembra essere molto intenso all'interno della community di Wikipedia riguardo l'uso dell'AI generativa per facilitare la manutenzione e l'evoluzione dell'enciclopedia. La mia posizione non si focalizza tanto sul se usarla o no - per me l'uso è un dato di fatto - quanto sul come possiamo utilizzarla. Non è concepibile una generazione di voci in totale autonomia, ma l'IA potrebbe supportare la creazione di voci da parte dei contributori, l’omogeneizzazione del loro stile, la traduzione in lingue meno diffuse o l’adattamento dei contenuti per pubblici specifici, nonché il collegamento di concetti rilevanti.
Nel settore educativo invece, ignorando l'uso di Google da parte degli studenti negli ultimi 20 anni, ora ci interroghiamo se gli LLMs possano essere strumenti utili e leciti. Anche qui, la tipologia di domanda è fuorviante, poiché dovremmo concentrarci sul 'come' impiegarli, più che sul 'se'. Se apprezzi la tassonomia di Bloom, che classifica le fasi dell'apprendimento per strutturare il processo educativo, potrebbe interessarti sapere che il mio amico Ajit Jaokar, presso l'Università di Oxford, sta sperimentando i nuovi strumenti generativi per stimolare la fase creativa dell’apprendimento invertendo di fatto l’ordine di utilizzo della tassonomia stessa.
Concludo questa serie di riflessioni polemiche con un'altra scoperta interessante 🙂. Sembra infatti che siamo diventati tutti "AI’s free data workers" per le grandi aziende tecnologiche, come sottolineato da questo interessante articolo del MIT Technology Review che cita un paper, redatto da studiosi di prestigiose università americane, che chiarisce il concetto di "data labor" e le sue sei dimensioni. È molto interessante da (ri)scoprire questo nostro status, ma non è differente dallo "sfruttamento" delle nostre scelte da parte dei motori di ricerca che avviene da quasi 25 anni. La questione non è se, in un sistema capitalistico, ciò sia lecito o meno, ma quanto ampia sia la possibilità di utilizzo di questo(i) lavoro (dati). Perciò, a meno di pensare a sistemi economici differenti da quelli occidentali, la soluzione non è bloccare questo sfruttamento, ostacolando il progresso, ma aprire e liberalizzare il mercato, consentendo a tutti noi, lavoratori di dati a titolo (quasi) gratuito, di partecipare maggiormente e in maniera più consapevole a questa creazione di valore, invece di diventarne meri schiavi e consumatori. Il tutto per creare il nostro futuro anziché subirlo.
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!
Ciao Stefano, mi trovo molto d'accordo con quanto riporti nella sezione investimenti in ambito dati e algoritmi, riguardo la posizione di Paris Heymann. Credo che una delle industry che beneficiera' maggiormente dell'AI generativa sara' l'healthcare. A tale riguardo, condivido un suggerimento ad un post su LinkedIn che ho trovato molto 'inspiring' in tema di Vertical AI
https://www.linkedin.com/posts/kumli_innovation-ai-healthcare-activity-7085566103665397761-TGjc?utm_source=share&utm_medium=member_desktop
Alla prossima!
L'ultima considerazione, che riprende il "surveillance capitalism" della Zuboff, è il motivo per cui questi modelli che sono di fatto "open sourced" per quanto riguarda i dati, dovrebbero essere di fatto "open source"