

LaCulturaDelDato #081
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è l'ottantunesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti dell’ottantunesimo numero:
🖐️Tecnologia (data engineering). Behind the Code: A Chat with Serena Sensini on Data, Algorithms, and Challenges Ahead
Presentati:
Serena Sensini. Ingegnera informatica specializzata nel campo dell’intelligenza artificiale, ho indossato diversi cappelli durante la mia carriera: sviluppatrice, sistemista, data scientist, ma anche team leader, data & software engineer, docente. Ad oggi, Enterprise Architect in Dedalus di giorno, e divulgatrice di notte. Attualmente ho pubblicato diversi manuali tecnici su temi come l’analisi del linguaggio naturale in Python, Docker, le basi di dati e Kubernetes - altri sono in cantiere -, oltre a pubblicare settimanalmente diversi post a tema tech sul mio blog TheRedCode.it. Ho iniziato prestissimo a occuparmi di informatica, grazie a mio padre che mi ha avvicinato al mondo della programmazione di Visual Basic permettendomi di sviluppare la mia prima calcolatrice quando avevo circa 10 anni. Da piccola avevo infatti tre sogni nel cassetto: diventare una scrittrice, un’informatica e un’archeologa. I primi due li ho realizzati, chissà il terzo!

Il mio ruolo tra 10 anni sarà ... (continua la frase come fossi GPT-10)
In ambito ricerca e sviluppo, possibilmente a capo di una divisione che si occupi di sistemi di intelligenza artificiale in ambito healthcare. Combinare la potenza di una serie di strumenti e tecniche che quest’area mette a disposizione in un settore come quello sanitario rende la sfida più complessa, ma ancor di più allettante: l’innovazione in questo campo dev’essere una priorità e massimizzare i risultati per il benessere collettivo è fondamentale. Non solo: vorrei continuare con l’attività di divulgazione, magari rendendo il blog un vero e proprio portale nazionale per chi si affaccia o vive il settore tech giorno dopo giorno!
Quale è la sfida più importante che il mondo dei dati e algoritmi ha di fronte a sé oggi?
La comunicazione tra tecnologia e governance è fondamentale, perché spesso le persone che lavorano in questi due ambiti non riescono a “comprendersi” e ad unire le proprie energie: parliamo di due mondi che non hanno un linguaggio comune, e che spesso parlano attraverso dei propri tecnicismi, rendendone incompatibile una sana ed efficace collaborazione. Rendere più democratico l’accesso ad una serie di risorse, come avviene in parte tramite gli open data, e semplificarne il lavoro e la divulgazione anche per chi si approccia per la prima volta al tema è diventato critico, in un’era dove i dati e gli algoritmi proliferano senza sosta!
Segnalaci il progetto o la risorsa nel mondo dei dati di cui non potresti fare a meno …
Ad oggi, direi il sito Towards Data Science: si tratta di uno dei portali più letti da chi lavora in ambito data science e che tratta non solo aspetti tecnici e pratici relativi alla materia con tutorial ed esperimenti attraverso gli ultimi strumenti messi a disposizione anche dalle big companies, ma fornisce diverse riflessioni utili su ciò che concerne i dati e più in generale le applicazioni e il settore tech con la relativa e rapidissima evoluzione. Grazie ad una community molto attiva, è possibile trovare articoli scritti anche da voci illustri nel settore, come Susan Li e Cassie Kozyrkov, risorse di inestimabile valore per tutte le persone che vogliono aggiornarsi su queste tematiche.
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Diving Deep into Agile: From 90s Roots to Today's AI Innovations with Andrew Ng
Usare la modalità di sviluppo agile in azienda è importante e non ti dico nulla di nuovo, dal momento che questo tipo di sviluppo ha le sue radici nella metà degli anni '90 ed è stato formalizzato nel manifesto dello sviluppo agile nel 2001. Tuttavia, lo sviluppo di algoritmi nel mondo dei dati e del machine learning si discosta un po' dal tradizionale sviluppo software e alcune sue declinazioni, come ad esempio lo Scrum, non si adattano perfettamente alle prime fasi di sviluppo di un progetto di datascience. Non per questo devi rinunciare alla modalità agile di sviluppo, anzi! Piuttosto, devi cercare di adattare e capire quali sono le pratiche e le metodologie che meglio si adattano alla tua tipologia di progetto e al tuo assetto organizzativo, stakeholder compresi.
Considero le pratiche agili particolarmente importanti nel nostro mondo per diversi motivi che ti elenco insieme ai suggerimenti di approfondimento di questa sezione:
La costruzione di un MVP (Minimum Viable Product) piuttosto che di un POC (Proof of Concept) ti consente di concentrare nelle prime fasi tutti i problemi di integrazione (dati e sw) con i sistemi legacy aziendali e dei relativi rischi.
Nell'aumentato dinamismo dei mercati, capire velocemente se è corretta la direzione che stiamo prendendo insieme all'interazione con i primi utilizzatori dei nostri prodotti/modelli è fondamentale.
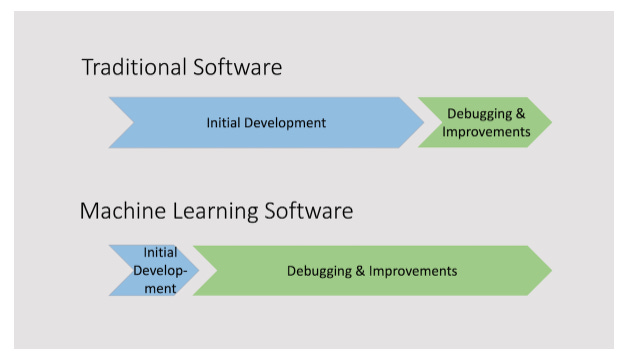
L'evoluzione degli strumenti a nostra disposizione, generative AI compresa, rende ancora più veloce la fase iniziale di sviluppo e rende ancora più importante tutta la fase di debugging & improvements che è molto più efficace quando il nostro prodotto/modello/algoritmo vive nelle sue "normali condizioni di uso", cioè con dati reali e/o in tempo reale. Andrew Ng spiega molto bene questo concetto nell'editoriale della sua newsletter. Sempre Andrew Ng spiega poi in maniera puntuale alcune metodologie specifiche che stanno emergendo insieme all'utilizzo della generative AI ed in particolare, in alcuni casi, il superamento del Test Sets e il Visual prompting nella Computer Vision. E se sei scettico, Andrew ha messo a disposizione un ambiente dove puoi toccare queste nuove metodologie con mano.
E a proposito di nuove metodologie che aiutano la rapidità di sviluppo in ottica di guadagnare agilità, ti segnalo questi due contributi di due persone che stimo molto:
Ben Lorica e il suo articolo "Dieci modi per accelerare l'adozione dell'AI Generativa nelle aziende" approfondisce metodologie e tecnologie che ti potranno servire nel tuo percorso.
Ajit Joaker in una serie di post sul tema sta sviluppando con la sua community ad Oxford un framework (metodologico) per generare casi d'uso di successo della generative AI ... con la generative AI.
👃Investimenti in ambito dati e algoritmi. AI Assistants: From Today's ChatGPT to Tomorrow's Pals, with Insights from a16z and Deep Water Management
Pochi temi nell'uso dell'intelligenza artificiale suscitano il mio interesse quanto l'evoluzione degli assistenti personali sviluppati prevalentemente con la generative AI. Questo argomento mi affascina perché si trova all'incrocio tra avanzamenti tecnologici, uso dei dati, sviluppo di nuovi prodotti e mercati, e investimenti. Oggi voglio suggerirti alcuni spunti che esplorano aspetti legati principalmente ai mercati e agli investimenti in questi settori. Avendo sperimentato questi sistemi fin dalle loro fasi iniziali e investendo sia tempo che denaro (sottoscrizioni piuttosto che equity, almeno per ora), ciò che ti condivido potrebbe riflettere una certa polarizzazione.
Ma andiamo al sodo... per iniziare ti consiglio una combo di articoli di Doug Clinton, della società di investimenti Deep Water Management, che delinea tre possibili scenari di evoluzione del mercato dell’AI personal assistant (io propendo per lo scenario “aristocratico” ma sono un uomo bianco, occidentale e di mezza età e questo potrebbe influenzare la scelta...): uno molto centralizzato (un po’ come si è evoluto il web 2.0), uno semi-centralizzato e uno totalmente decentralizzato. Sulla base di questo primo articolo più filosofico e di visione, Doug nel successivo post prevede un mercato di almeno 1000 miliardi di dollari facendo delle ipotesi a tratti azzardate ma non prive di senso. Leggili nell'ordine che ti ho consigliato e poi, se ti va, scrivimi il tuo parere o il tuo scenario più probabile, o commentali: mi interessa molto!
Sullo stesso argomento ma più ancorati al presente ci sono gli altri spunti che ti propongo:
Qui a16z fa un'analisi basata su dati di cosa (quali prodotti) e come le persone stanno usando l'AI generativa. Contiene anche sei tesi molto interessanti. La mia preferita, e molto importante per il tema di cui parlavo sopra, è la quinta: "Acquisition for top products is entirely organic—and consumers are willing to pay!".
In quest'altro articolo, sempre a16z fa un'analisi di come anche la percezione dei primi utenti di questi personal AI stia cambiando, da strumento informatico, come erano percepiti i chatbot, a compagno. È chiaro che le domande etiche e filosofiche su questo argomento sono tante, ma occorre osservare il fenomeno prima di dare giudizi definitivi.
Riporto per non peccare di ottimismo che l'utilizzo di Chat-GPT, stando ai dati, sembra essere sceso negli ultimi mesi anche se potrebbe essere dovuto alla pausa scolastica estiva ;-) . Ma il mio entusiasmo sull'argomento mi fa notare che l'interfaccia di Chat-GPT e le sue funzionalità non sono esattamente quelle del futuro personal AI. Inoltre, si sono create tante altre alternative verticali e orizzontali (a livello di funzionalità) a ChatGPT e quindi anche questa notizia non ha solo aspetti negativi nell'evoluzione complessiva del mercato.
👀 Data Science. Google's Med-Palm2: The Game-Changer in Medical AI You Can't Ignore!
Esiste un ambito della generative AI in cui, sulla base di paper e notizie decisamente affidabili, Google sta accumulando un deciso vantaggio sulle altre big tech. Se sei un data-expert che lavora in ambito healthcare, non puoi ignorare Med-Palm2. Ma cos'è in concreto Med-Palm2? Per saperlo ti suggerisco di leggere tutto l’approfondimento di oggi che ne parla in dettaglio, dalla sua storia all'evoluzione, fino ai casi d’uso più promettenti.
In estrema sintesi, come scritto nell’articolo di Fixter.com: “Med-PaLM 2 è il modello linguistico di Google per il settore medico, progettato per rispondere in modo accurato e sicuro alle domande di carattere medico. È stato il primo LLM a ottenere prestazioni di livello "esperto" su un dataset MedQA di domande in stile USMLE (US Medical Licensing Examination), raggiungendo un'accuratezza superiore all'85%... Il LLM è stato valutato in base a diversi criteri, tra cui il consenso scientifico, il ragionamento medico, l’uso delle conoscenze mediche, la parzialità e la probabilità di possibili danni. Queste valutazioni sono state eseguite da medici e non medici provenienti da diversi contesti e Paesi. Google consente un accesso limitato a Med-PaLM 2 per test e feedback a un gruppo selezionato di clienti Google Cloud”.
Il campo della prevenzione e della cura è molto complesso, sia in termini di conseguenze legali che di tutela della privacy. Sono però convinto che in futuro non potremo farne a meno, soprattutto a causa della convergenza di alcuni trend. L'allungamento della vita in quasi tutti i paesi del mondo, la bassissima natalità nei paesi sviluppati e la già scarsa disponibilità di lavoratori nel settore sanitario, rendono l’utilizzo dell’AI una necessità.
Il tema centrale, almeno nel medio periodo, non è tanto se ma come verrà utilizzata. Su questo, iniziare ad usarla per aumentare l’attività degli operatori sanitari e trovare modi moderni per garantire la privacy senza penalizzare l’uso dei dati a livello individuale e collettivo, è la più grande sfida che abbiamo di fronte.
Se poi vuoi approfondire, e se sei un data-scientist ti consiglio il paper originale di Maggio 2023 che è il miglior riferimento che ti posso indicare per conoscere tutti i passaggi tecnici che hanno portato a Med-Palm2.
👅Etica & regolamentazione & impatto sulla società. Living Longer and Loving It: Andrew J. Scott Breaks Down the Data-Driven Future!
"Penso che la sfida che abbiamo in questo momento è che ci sono tre dimensioni dell'allungamento della vita. Una l'abbiamo già conquistata: le nostre vite sono già più lunghe. Dobbiamo assicurarci che la nostra salute si adegui a queste vite più lunghe. E dobbiamo assicurarci che il nostro potenziale produttivo si estenda, perché così potremo finanziare queste vite più lunghe”. Questo è un riassunto dell'analisi che ti propongo oggi, strettamente correlato al tema trattato nella sezione precedente. "Forward Thinking on how to live our longer lives with Andrew J. Scott" è un'intervista approfondita realizzata dal McKinsey Institute con Andrew J. Scott, un economista che ha scritto molto (tra le altre cose, insieme a Lynda Gratton, il best-seller “The 100-Year Life”) di quello che significa l’allungamento della vita su diverse dimensioni, tutte esplorate con quell’approccio data-driven che piace a noi. E non si parla solo di economia nell’articolo, ma di tutte quelle problematiche che, a livello di storia umana, non abbiamo mai affrontato! I dati e l’intelligenza artificiale, che fanno capolino molte volte nell’intervista, hanno e avranno sempre di più un impatto rilevante non solo sull’allungamento della vita (Lifespan) ma soprattutto sulla qualità di questo allungamento (HealthSpan) e sui livelli di produttività che riusciremo a mantenere nella fase finale della nostra vita, che ha molto a che vedere con la sua sostenibilità per le generazioni a venire (Longevity Economic Sustainability).
Ti lascio con una riflessione personale su come il mondo dei dati e dell’intelligenza artificiale possa contribuire, a livello sistemico, a migliorare le tre direttrici di evoluzione: LifeSpan, HealthSpan e Longevity Economic Sustainability. Sono tre livelli, a partire da quello più “basso” dei dati fino ad arrivare alle intelligenze artificiali del futuro che ci suggeriranno i migliori comportamenti per arrivare in salute a 120 anni 🙂:
1. Interoperabilità e integrazione dei nostri dati legati alla salute. Senza cadere in eccessi alla Bryan Johnson, abbiamo sempre più dati, con serie storiche di grande importanza, legate ad esami strumentali e a device che misurano a volte in tempo reale molti parametri vitali. Sembra una banalità ma non lo è! Trovo molto frustrante, nell’era della generative AI, non avere un punto unico dove possono essere facilmente accessibili, in formati dati standard, i parametri dei periodici esami del sangue (e questo può non accadere anche nella stessa regione su diversi laboratori specializzati). Sappiamo l’importanza di correlare dati di diverse fonti e momenti quando si parla di diagnosi e prevenzione sanitaria. Possiamo avere le migliori intelligenze artificiali ma se non mettiamo a posto a livello nazionale (e forse mondiale) questo punto, tutti i successivi passaggi perdono di efficacia.
2. Aumentare la precisione e l’efficienza degli operatori sanitari (medici ma non solo) con algoritmi e intelligenze non umane. Anche su questo punto il tema dell’integrazione con gli attuali strumenti è cruciale. Integrazione non solo tecnologica ma che significa anche formazione e riqualificazione degli operatori sanitari attuali. Non è solo una questione di qualità degli algoritmi …
3. L’aumento del focus sulla prevenzione e su quel concetto di Medicina 3.0 che Peter Attia ha descritto molto bene nel suo recente libro Outlive. E per fare questo certamente gli operatori sanitari avranno un ruolo importante, ma non potremo non fare affidamento sui Personal Health Advisory che, magari attraverso le future versioni di Med-Palm, ci aiuteranno a fare le scelte migliori per vivere più a lungo e più in salute.
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!
Attenzione che The 100-Year Life non ha un solo autore ma due coautori: Lynda Gratton e Andrew Scott. Per come il libro è citato sembra che Scott sia l'unico autore, con lo sfortunato effetto di cancellare la coautrice.
Complimenti. L’intervista apre molti spunti. E questo, deragliando un po’, anche per l’evoluzione del mondo della consulenza.