

LaCulturaDelDato #083
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è l'ottantatreesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti dell'ottantatreesimo numero:
👀 Data Science. Navigating the Data Landscape: A Conversation with Giuseppe Sollazzo
Presentati:
Giuseppe Sollazzo. Dopo una laurea in informatica, ho passato un paio d’anni a digitalizzare laboratori di analisi in giro per l’Italia a metà anni 2000, imbattendomi nei problemi della generazione di analisi di milioni di record al giorno – quando non si usavano ancora locuzioni come “big data” o “data science”. Poi ho velocissimamente fallito un PhD a Imperial College (sono scappato dopo 5 mesi), e ho passato circa 10 anni a lavorare in IT al St George’s Hospital Medical School, un lavoro che mi ha permesso non solo di affinare le mie conoscenze tecniche ma anche di confrontarmi con Open Data, Open Access, Open Source, Data Ethics e Data Management Policy, High-Performance Computing, analisi di terabyte di dati – tutti concetti che sono diventati parte del mio bagaglio personale.
Dal 2018 lavoro nel pubblico in UK, prima come Head of Data al Ministero dei Trasporti, e poi come Deputy Director dell’AI Lab del servizio sanitario nazionale, dove il mio compito principale era capire se e come usare AI per problemi di sanità pubblica. Da fine agosto 2023 ricopro il ruolo di Deputy Director, Head of Data Products and Services al Ministero del Lavoro e delle Pensioni.
Negli ultimi 15 anni ho anche fatto molta libera professione e molti mi conoscono come il “data geek” che ha lanciato progetti personali che hanno riscontrato interesse nel pubblico, come Parli-N-Grams (una piattaforma di analisi del linguaggio usato in Parlamento), o il calcolo della “faccia media” del Congresso Americano. Dal 2012 realizzo la newsletter “Quantum of Sollazzo”, che raccoglie link ad articoli interessanti sui dati.

Il mio ruolo tra 10 anni sarà ... (continua la frase come fossi GPT-10)
…in evoluzione come oggi :) Vent’anni fa volevo fare il programmatore, quindici anni fa l’accademico, dieci anni fa il DevOps, cinque anni fa il data leader nel governo… oggi continuo a programmare nel weekend, a gestire i miei server, a supportare ricerca accademica con tanto di occasionali pubblicazioni. Per me ogni nuovo capitolo si somma ai precedenti: oggi tendo a descrivermi come un generalista che usa la tecnologia per avvicinarsi agli utenti e sfornare ciò di cui hanno bisogno, e questo credo che rimarrà nei miei ruoli futuri.
In termini di contenuti, mi sto sempre più interessando all’ambiente e credo che tra dieci anni è probabile che parte del mio lavoro potrebbe essere in quel campo – sia rispondendo alla domanda “cosa può fare la tecnologia per l’ambiente e il clima” ma anche “come possiamo ridurre l’impatto ambientale della tecnologia”. Nel frattempo, imparo: coltivo l’orto ogni domenica mattina e provo (senza molto successo) ad automatizzarlo con pannelli solari e Raspberry Pi.
Qual è la sfida più importante che il mondo dei dati e algoritmi ha di fronte a sé oggi?
È importante capire che i dati non hanno tutte le risposte e che abbiamo bisogno di diverse figure professionali per capirli in fondo. I dati, in realtà, spesso permettono di sviluppare domande, più che risposte. Dobbiamo imparare a capire che i dati non sono la panacea, e che solo facendo un passo indietro e capendo il contesto in cui quei dati si trovano possiamo usarli in modo efficace. Oltretutto, stiamo sempre più capendo, soprattutto con l’uso dell’AI, che il bias insito nel processo di raccolta dei dati deve essere quantificato e gestito. Mi ricordo un progetto del mio ultimo lavoro, in cui con un gruppo di dermatologi volevamo creare un modello per l’assessment delle piaghe da decubito in popolazioni non bianche; ci siamo resi conto che non c’erano dati (immagini, in questo caso) sufficienti per tutta la “scala” di tonalità della pelle, e il progetto è diventato un progetto di raccolta dei dati.
In sintesi, bisogna capire che il lavoro sui dati è sempre più multidisciplinare.
Segnalaci il progetto o la risorsa nel mondo dei dati di cui non potresti fare a meno …
Sicuramente il lavoro dell’Associazione OnData, che mette insieme attivismo sui dati aperti e lavoro tecnico di qualità, si pensi ad esempio al lavoro di data processing che hanno fatto durante le ultime elezioni. La loro mailing list è una fantastica risorsa su quello che succede in Italia nell’ambito dei dati e del pubblico. Recentemente Andrea Borruso, presidente dell’associazione, ha rilasciato un bellissimo, e molto accessibile, articolo sul come usare DuckDB per l’analisi di file CSV molto grandi, che è un esempio di come rendere l’uso dei dati più facile e comprensibile per tutti.
👅Etica & regolamentazione & impatto sulla società. Global AI Governance: A Dive into Diverse Regulatory Approaches
Dopo qualche settimana, torniamo a discutere in questa sezione della newsletter di come varie parti del mondo stanno approcciando la regolamentazione dell’Intelligenza Artificiale.
"Anche se una tecnologia così potenzialmente dirompente meriterebbe, probabilmente, dei tentativi di governance globale, la storia recente dell’umanità ci ha mostrato quanto questo sia difficile. Così, ci si deve accontentare di analizzare le operazioni di regolamentazione in diverse parti del mondo." Questa è l'ottima sintesi proposta da
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. From Tufte to Today: PowerPoint’s Persistent Reign Amid Criticism
“Nel 2003, l'esperto di statistica dell’Università di Yale, Edward Tufte, pubblicò un pamphlet che lo rese brevemente famoso. Si intitolava "The Cognitive Style of PowerPoint" (Lo Stile Cognitivo di PowerPoint) e sosteneva, in sintesi, che i formati attraverso cui vengono comunicate le informazioni influenzino le comunicazioni stesse. In particolare, evidenziava come PowerPoint, il popolare software per le presentazioni digitali incluso nel pacchetto Microsoft Office, avesse intorpidito le persone abbreviando e semplificando il modo in cui le informazioni venivano comunicate...” comincia così l'approfondimento che ti suggerisco, che non è altro che una riflessione fatta da “Il Post”, che riprende a sua volta un recente articolo di “The Atlantic”. Dopo 20 anni dall’analisi di Tufte, The Atlantic prova a fare un bilancio suggerendo che le preoccupazioni di Tufte su PowerPoint erano in qualche modo simili alle critiche contemporanee sui social media, entrambi accusati di privilegiare la forma sulla sostanza e di distorcere la comunicazione. La testata americana sostiene inoltre che nonostante le critiche, PowerPoint continua ad essere ampiamente utilizzato, indicando che le preoccupazioni iniziali potrebbero essere state esagerate o mal indirizzate.
Non sono totalmente d’accordo con le conclusioni, perché sono convinto che se da un lato può essere un fondamentale supporto per meeting di presentazione generale o di condivisione di contenuti, troppo spesso in molti ambiti è diventato l’unico strumento di supporto a qualunque discussione. Per esempio, nel mondo dei dati, PowerPoint può essere uno strumento molto utile in fase di Explanatory Analysis, cioè quando devo comunicare il risultato della mia analisi; lo trovo assolutamente inadatto e purtroppo utilizzato nelle fasi di Exploratory Analysis o in momenti dove queste fasi si possono parzialmente sovrapporre (se vuoi ripassare la differenza tra le due fasi, ti consiglio questo iconico articolo di Storytelling with Data). In questi momenti, trovo Jupyter Notebook o qualunque altro strumento che possa integrare coding, testo e immagini assolutamente più efficace e agile. Naturalmente, esistono diverse alternative a Jupyter Notebook pronte all’uso, come per esempio, se hai un account Google, Google Colab. Ci sono diversi ambiti in cui il sempre più avanzato uso di coding e dati rende l’uso del solo PowerPoint riduttivo e poco creativo. Per esempio, l’ambito universitario, per lo meno in una parte dei corsi di studi, meriterebbe la valutazione di strumenti alternativi a PowerPoint. Negli USA, questa pratica sta prendendo piede e devo dire che la mia sperimentazione nel corso all'Università Cattolica di Laboratorio di Decisioni Aziendali è stata decisamente positiva. Quindi, lunga vita a PowerPoint, ma usato nei contesti opportuni!
🖐️Tecnologia (data engineering). VectorDBs and RAG: Pioneering the New Wave of Knowledge Interaction
Le Retrieval Augmented Generation (RAG), introdotte per la prima volta in questo paper, sono modelli architetturali che combinano la capacità di recupero delle informazioni con la generazione di testo. Essenzialmente, questi modelli cercano informazioni pertinenti in un database o in un set di documenti e poi utilizzano queste informazioni per generare risposte specifiche e pertinenti. La fase di recupero è guidata da una rappresentazione vettoriale della query dell'utente, che permette di cercare e trovare informazioni rilevanti molto rapidamente. Mentre la parte di risposta è realizzata da un LLM.
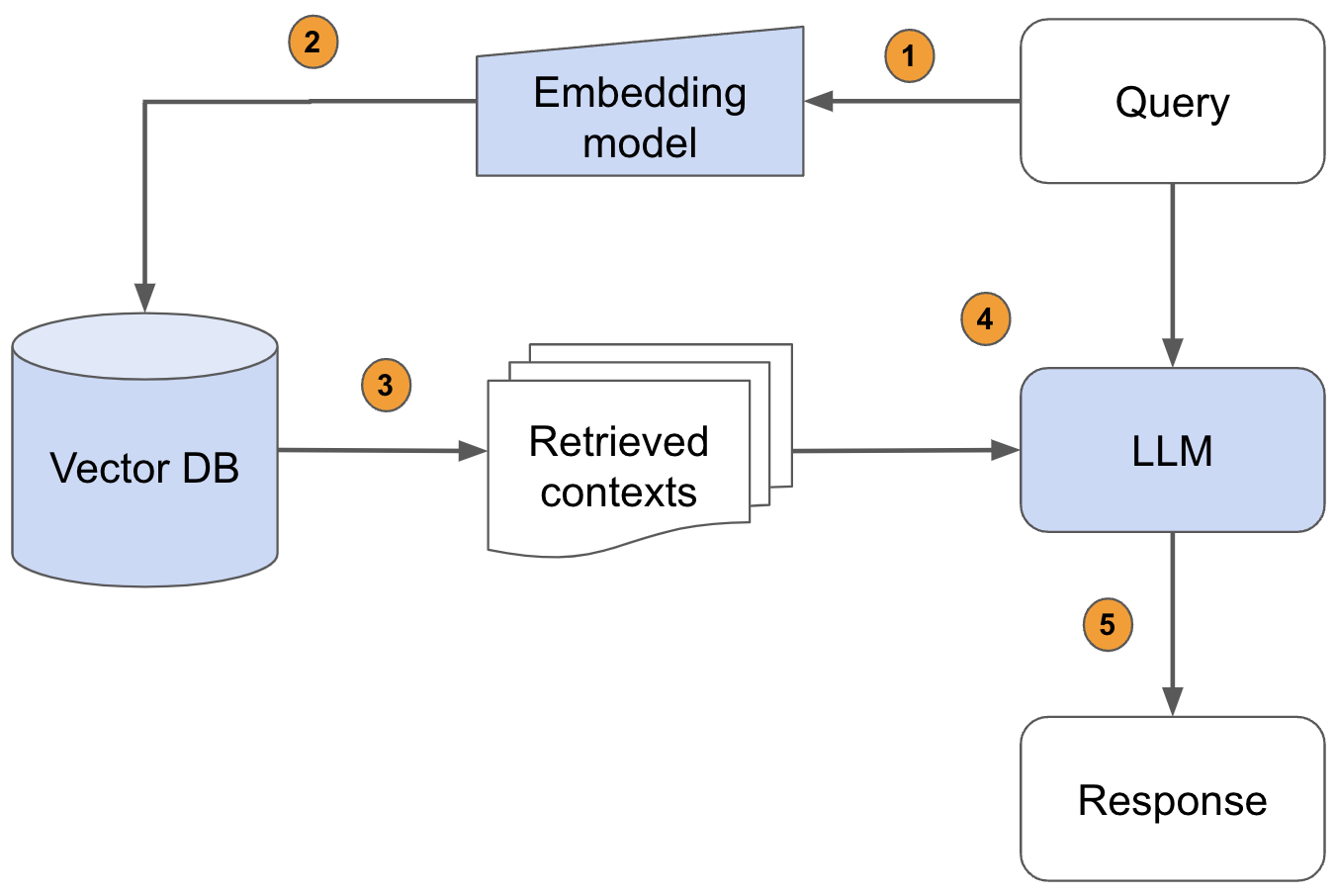
Non so se queste architetture (di cui vedete sopra una schematizzazione tratta dal blog di AnyScale) saranno l’architrave con cui interagiremo con vasti corpi di conoscenza nel futuro, ma sicuramente allo stato attuale sono uno dei tentativi di innovazione più convincenti in questo ambito.
I VectorDB sono cruciali in questo contesto perché rappresentano, per certi versi, la “memoria” degli LLM consentendo in aggiunta una ricerca efficiente e rapida attraverso grandi quantità di dati. Questi database sono in grado di gestire e indicizzare grandi quantità di dati strutturati e non strutturati, facilitando la fase di recupero delle informazioni in un modello RAG. Con i VectorDB, è possibile trovare rapidamente le informazioni più pertinenti a una determinata query, attività essenziale soprattutto quando si lavora con un corpo di conoscenza molto vasto. Infatti, al momento, anche l’LLM con la finestra di contesto più ampia, Claude2 di Antropic, non supera la lunghezza di un libro medio.
Per questo, i consigli di approfondimento di oggi sono sui VectorDB, tematica su cui sono concentrati molti investimenti e sviluppi dell'intera comunità tech.
In questo articolo trovi una delle migliori spiegazioni funzionali e tecniche sul perché questa tipologia di database è così importante e perché lo è in questo periodo storico.
In quest’altro post, Daniel Doubrovkine, uno dei più importanti conoscitori mondiali dei VectorDB e attualmente in Amazon, fa una carrellata sintetica ed esaustiva, anche dal punto di vista tecnico, dei principali database vettoriali sul mercato. Se vuoi sperimentare praticamente con poche righe di python le principali caratteristiche di questi database, ti consiglio il primo nella lista, cioè Chroma, che puoi provare semplicemente in Python come libreria.
E se vuoi andare un pochino oltre le funzionalità di un database vettoriale puro, ti consiglio di dare un’occhiata a questo progetto OpenSource Txtai, molto innovativo, che tecnicamente si definisce come database di embedding e che, oltre alla ricerca semantica, ha funzionalità specifiche per l'orchestrazione degli LLM e dei flussi di lavoro che utilizzano i modelli linguistici.
👃Investimenti in ambito dati e algoritmi. Unicorn Spotlight: Analyzing the Global Sprout of Billion-Dollar Startups
Un unicorno è una startup che raggiunge una valutazione di almeno un miliardo di dollari durante un round di investimento. È una caratteristica raggiunta da non molte start-up, poco più di un migliaio attualmente, e non esiste un registro mondiale ufficiale ma diverse raccolte dati di società specializzate come CB Insights e DealRoom che registrano questa informazione in maniera semi-automatica da testate specializzate e da comunicati stampa. Per questo, non sempre numeri e statistiche sono perfettamente replicabili ma dipendono spesso dalla fonte di raccolta dati. I dati di trend relativi a questa tipologia di start-up sono molto interessanti perché fotografano molto bene l’evoluzione del mercato di aziende che sono potenzialmente vicine al mercato azionario, visto che uno dei possibili momenti successivi al diventare un unicorno è quello dell’IPO, anche se non il più frequente.
Gli approfondimenti di oggi, nella sezione dedicata agli investimenti, ruotano proprio attorno all’analisi di questa particolare categoria di start-up di successo.
Il primo lo potremmo intitolare “Tutto quello che avresti voluto sapere sugli Unicorni degli ultimi 4 anni ma non hai mai osato chiedere…” 🙂. Infatti, l’analisi di Elad Gil, un imprenditore seriale e un investitore ossessionato dalla tecnologia e dalle start-up (così si definisce) e anche dai dati, propone, partendo dai dati di CB Insight, tantissime analisi sull’evoluzione degli unicorni su diverse variabili, da quella temporale a quella geografica con un livello di dettaglio degno di nota. Se non riesci a leggere tutto il post, non perderti i 7 punti chiave all’inizio. Per spronarti a leggerli ti spoilero il secondo, che è anche il mio preferito:
“L'ampia distribuzione di città con un solo unicorno (da 37 a 75 in 4 anni) riflette probabilmente un aumento degli "ZIRPcorni" (che poche righe sopra aveva definito come figli della “Zero Interest Rate Policy”, da qui l’acronimo ZIRPcorno) piuttosto che un vero decentramento di startup importanti. Gli ZIRPcorni sono unicorni che probabilmente varrebbero molto meno di 1 miliardo di dollari se non fosse per l'eccesso di multipli dell'era COVID/ZIRP”.
Il secondo approfondimento, sempre sugli unicorni, è questa infografica di Visual Capitalist che mostra come più del 54% degli unicorni americani ha almeno un founder immigrato, con l’India senza sorpresa a farla da padrona e con l’Italia più indietro in classifica, e questo francamente mi ha sorpreso un pochino. Questa statistica nel suo complesso evidenzia ancora una volta come una delle ricchezze e delle forze degli Stati Uniti sia proprio la valorizzazione dell’immigrazione!
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!