

LaCulturaDelDato #094
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il novantaquattresimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Prima di cominciare, due piccoli annunci:
1) Si avvicina il numero 100 e per festeggiarlo, volevo preparare un numero speciale della newsletter, ossia una meta-newsletter. Vorrei dividerla in due parti: la prima per raccontarti come la realizzo, compresi i passaggi in cui uso la generative AI. La seconda parte sarà formata da qualche domanda che vuoi farmi, una sorta di AMA (Ask Me Anything) per dirla all’americana. Per realizzarla al meglio, chiedo il tuo aiuto per capire se l'idea ti piace e per ricevere le tue domande. Lo puoi fare nella survey a cui accedi qui o, se preferisci, via mail (a st.gatti@gmail.com).
2) Con il nuovo anno, come ti avevo anticipato, inserirò la possibilità di sponsorizzare e supportare economicamente la newsletter per farla crescere ulteriormente e renderla sostenibile. Per le sponsorizzazioni, che saranno completamente trasparenti, ho fissato un principio fondamentale: devono riguardare prodotti, strumenti, servizi o corsi che ho provato personalmente o che ho capito, interagendo con chi li realizza, che possono essere utili ad una frazione significativa dei lettori e sono in grado di spiegarne il perché in maniera semplice all’interno del consiglio. Sto già raccogliendo richieste per programmarle all'inizio dell'anno. Se sei interessato scrivimi (a st.gatti@gmail.com).
Ecco i cinque spunti del novantaquattresimo numero:
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Navigating the Data Jungle: Expert Tips for Understanding News and Research
Quando leggi una notizia, uno studio o un grafico che influisce sul tuo processo decisionale o sulla formazione delle tue opinioni, è cruciale verificare i dati e le metodologie alla loro base. Capisco che farlo sistematicamente su tutto sia impraticabile e oneroso. Dunque, è fondamentale definire una strategia per ottimizzare l'uso delle risorse, soprattutto del tempo. Il primo passo è decidere quando farlo, basandosi sull'importanza strategica della decisione da prendere e sulla fonte dell'informazione. Conoscere bene la fonte informativa e i suoi metodi di lavoro aumenta la precisione di questa scelta. Ad esempio, personalmente tendo a fidarmi di più di una notizia de “Il Post” rispetto a Dagospia, conoscendo la professionalità con cui i redattori de “Il Post” validano notizie e dati.
Gli eventuali passaggi successivi sono altrettanto cruciali e vorrei suggerirti alcuni approfondimenti utili. Un primo consiglio viene da
1. Da dove arrivano i dati?
2. Che tipo di metodologia è stata usata?
3. Cosa dicono in più i metadati?
4. Cosa stiamo contando?
5. Cosa non dicono questi dati?
Ti consiglio di leggere l'intero post, arricchito da esempi pertinenti di Donata. Anche solo per leggerlo vale la pena di iscriversi al periodo di prova della sua newsletter e saggiare le qualità del prodotto!
Un secondo suggerimento è una serie di cinque post straordinari di Peter Attia, che descrive dettagliatamente come leggere studi scientifici, focalizzandosi soprattutto su quelli medici. Le sue spiegazioni, valide comunque per ogni tipo di studio o paper, sono sintetizzate anche in una puntata speciale del podast “How to Read and Understand Scientific Studies”. Per esempio, chiarisce molto bene la differenza tra studi osservazionali, sperimentali e meta-analisi, come mostrato nella figura realizzata dalla Purdue University da lui ampiamente commentata nel video.

Se lavori in azienda in un settore diverso dalla ricerca e sviluppo, ti imbatterai più spesso negli studi correlazionali, un tipo di studio osservazionale che Jim Frost spiega in maniera semplice qui. Se invece la tua notizia o studio deriva da un'indagine a campione, ricorda la guida che ti ho consigliato nel numero 64 di questa newsletter per raccogliere dati efficacemente attraverso i sondaggi: "How to Run Surveys: A Guide to Creating Your Own Identifying Variation and Revealing the Invisible", scritta dalla bravissima Professoressa di Economia Politica ad Harvard, Stefanie Stantcheva.
👅Etica & regolamentazione & impatto sulla società. Data Meets Climate and Geography: Unveiling MEDSAT's Geo-Insights at NeurIPS
La Conference and Workshop on Neural Information Processing Systems (abbreviata NeurIPS, precedentemente NIPS) è un evento significativo nel campo del Machine Learning e delle neuroscienze computazionali, che si tiene ogni dicembre. Negli ultimi due anni, la conferenza si è svolta a New Orleans, negli Stati Uniti. Anche Andrew Ng ha menzionato NeurIPS nella sua newsletter, sottolineando l'importanza dell'evento. Secondo Ng, NeurIPS è "un luogo privilegiato per esaminare un ampio volume di lavori di alta qualità provenienti da università e piccole aziende, le quali spesso non dispongono di budget di marketing paragonabili a quelli delle grandi aziende". Nonostante non abbia mai partecipato personalmente, seguo con interesse i risultati che vengono gradualmente resi pubblici nelle settimane successive.
Uno dei lavori presentati nella sessione "Datasets and Benchmarks" ha attirato la mia attenzione, non solo per l'importanza del progetto, ma anche perché conosco personalmente la professionalità e la competenza di uno dei ricercatori coinvolti, Daniele Quercia.
MEDSAT è un dataset che aggrega dati socio-demografici, ambientali e di salute dettagliati per le diverse aree geografiche dell'Inghilterra. Il suo scopo è migliorare la comprensione e l'analisi dell'impatto degli eventi meteorologici estremi e altri fattori ambientali sulla salute umana, sfidando la comunità di machine learning a sviluppare nuovi modelli e tecniche per capire e migliorare la salute pubblica.
L'abstract del progetto chiarisce fin dall'inizio la motivazione dietro questo lavoro complesso: "Con l'aumentare della frequenza degli eventi meteorologici estremi, diventa sempre più cruciale comprendere il loro impatto sulla salute umana. Tuttavia, l'uso dell'osservazione della Terra per analizzare efficacemente il contesto ambientale in relazione alla salute rimane limitato a causa della mancanza di dati spaziali e temporali dettagliati negli studi sulla salute pubblica e della popolazione. Inoltre, ottenere indici ambientali appropriati su diversi livelli geografici e intervalli temporali rappresenta una sfida. Per gli anni 2019 (pre-COVID) e 2020 (COVID), abbiamo raccolto indicatori spazio-temporali per tutte le Lower Layer Super Output Areas in Inghilterra. Questi indicatori includono: i) 111 caratteristiche socio-demografiche correlate alla salute, ii) 43 caratteristiche ambientali puntuali, iii) 4 immagini satellitari composite stagionali, ciascuna con 11 bande, e iv) prevalenza di prescrizioni associate a cinque condizioni mediche..."
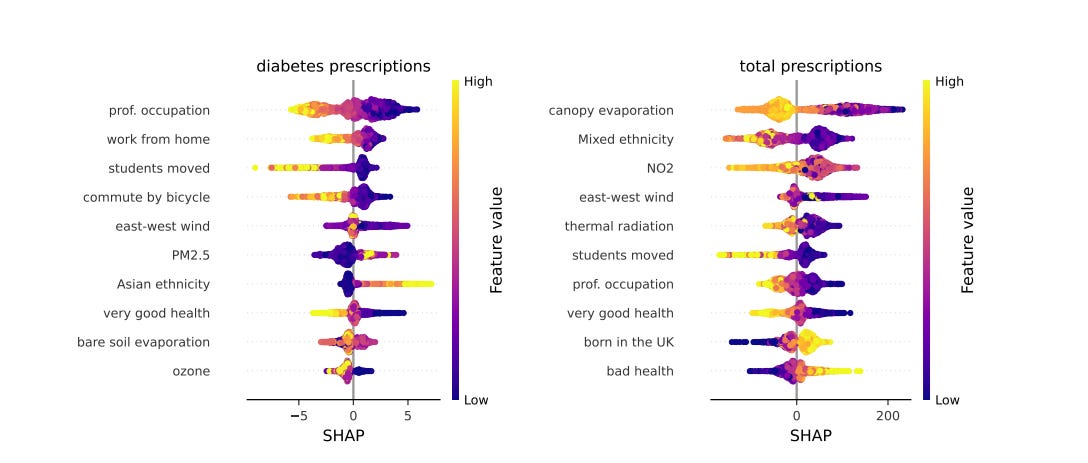
Il paper presenta una descrizione sintetica del progetto, delle variabili coinvolte, una statistica descrittiva di base e anche alcune analisi, comprese quelle fatte con SHAP (di cui ti ho riportato un esempio sopra), sulla contribuzione di alcune variabili in ingresso rispetto a quelle in uscita, come le prescrizioni di farmaci per il diabete o altre prescrizioni mediche. Ci sono molte analisi e informazioni da estrarre in questa abbondante quantità di dati, tutti disponibili qui, mentre il codice lo trovi qui.
🖐️Tecnologia (data engineering). Unlocking Data Secrets: How Andrea Borruso Transforms CSV Handling
Se avessi avuto tra le mani questo fantastico post scritto da
"Il formato CSV è uno dei formati più diffusi per lo scambio di dati. È un formato testuale, che può essere letto e scritto da quasi tutti i linguaggi di programmazione e da quasi tutti gli strumenti di analisi dati (i “quasi” si potrebbero levare). Non è consigliabile utilizzarlo come formato di lavoro, perché le operazioni di lettura e scrittura sono lente e costose in termini di risorse (tempo e memoria) e perché è in generale un formato “povero”. Un file CSV è “brutto e cattivo” ad esempio per queste ragioni .." Ecco come Andrea inizia a spiegare perché i CSV sono allo stesso tempo amati e odiati da chi lavora con i dati. Ma Andrea nell'articolo ci aiuta in due modi: ci suggerisce come soffrire meno nel gestirli e fornisce buone pratiche per chi pubblica questi CSV, rendendoli più standardizzati e ricchi di metadati per una maggiore interoperabilità (da non perdere il paragrafo il "CSV standard"). La pratica di associare al CSV anche la query SQL per la creazione della tabella è un consiglio che non avevo mai trovato e che sognerò per diverse notti. 😊 Ma l'articolo di Andrea offre molto di più: formazione preziosa, che non trovi sui libri, e strumenti come DuckDB e il formato Parquet, spiegati magnificamente e che fanno una grande differenza se usati come ci suggerisce. L'utilizzo congiunto di DuckDB e Parquet, come scrive Andrea, è quasi come avere delle API! Questo post non va solo letto, ma aggiunto ai preferiti perché un giorno ti salverà sicuramente ore di sonno!
Se vuoi analizzare rapidamente CSV, file Parquet, db formato DuckDB e SQLite, dai un'occhiata a Tadviewer, molto più utile e professionale di quanto si descriva: “work-in-progress hobby project”. Anche questo strumento mi ha fatto risparmiare molto tempo in tempi più recenti.
Invece, se devi gestire grandi quantità di dati in ambiente Python, questo post con benchmark recenti su dati di grandi dimensioni in formato Parquet ti guiderà nella scelta tra Pandas, Polars o Pandas2. Spoiler: Polars è numericamente superiore, ma potrebbe non essere sempre la scelta necessaria…
👀 Data Science. Decoding Texts: The Power of Entity Recognition and Linking in NLP
L’Entity Recognition e l’Entity Linking rappresentano due processi chiave nel campo del Natural Language Processing (NLP). L’Entity Recognition identifica entità specifiche all'interno di un testo, come nomi propri di persone, organizzazioni, luoghi, espressioni di tempo, quantità, valute, ecc. Ad esempio, in "Mario Rossi lavora in Google a Milano", "Mario Rossi" è identificato come persona, "Google" come organizzazione e "Milano" come località.
Di solito il passaggio successivo (nella catena del valore) è l’Entity Linking, che collega ciascuna entità identificata a una voce specifica in una base di dati come Wikipedia o un database aziendale, fornendo contesto e disambiguazione dettagliati. Questo passaggio è fondamentale per chiarire a quale entità specifica si riferisce il testo, superando possibili ambiguità.
Nel contesto NLP, questi processi sono essenziali per comprendere e interpretare i testi in modo strutturato, risultando spesso cruciali nei progetti di machine learning e analisi dati. Negli ultimi 15 anni, hanno migliorato notevolmente la loro efficacia, sebbene raggiungere alta precisione rimanga complesso, specialmente con testi in lingue diverse.
Per mitigare queste sfide nascono progetti come UNER (Universal Named entity Recognition) che ti consiglio di approfondire oggi se sei un appassionato dell’argormento. UNER punta a colmare un gap nel NLP multilingue, offrendo dataset di alta qualità per il riconoscimento di entità in diverse lingue con un set di tag condiviso. Ispirato a Universal Dependencies, UNER rappresenta un notevole sforzo di annotazione della comunità con linee guida universali per le lingue.
Se utilizzi metodologie di Entity Extraction o tecniche NLP, è fondamentale avere testi puliti e ben strutturati. A questo proposito ti suggerisco di esplorare la libreria Python Trafilatura, utilizzabile anche da riga di comando, progettata per raccogliere testi dal web. È riconosciuta per la sua efficienza e robustezza nell'estrazione di contenuti, essendo una delle migliori librerie open-source in questo ambito.
Personalmente, ho testato Trafilatura (con l'assistenza di ChatGPT-4 per costruire la pipeline) in combinazione con spaCy (per la NER) e ho ottenuto, in pochi minuti, risultati che in passato richiedevano giorni!
👃Investimenti in ambito dati e algoritmi: Behind the Scenes: Sam Altman and Ilya Sutskever in the Eye of AI's Storm
Ho aspettato qualche settimana prima di condividere alcune riflessioni sui “Cinque giorni matti di Open AI”, su cui tutti hanno scritto, commentando anche le minime parole dei protagonisti di questa incredibile vicenda. Tuttavia, si tratta principalmente di ipotesi, dal momento che credo che i dettagli più "intimi" di questi eventi non verranno mai completamente svelati. È importante parlarne in questa sezione della newsletter, poiché tutti noi, che stiamo dedicando tempo e risorse economiche alla generative AI, dovremmo formarci un'opinione su chi sta guidando questa rivoluzione. Una rivoluzione intorno alla quale il mondo sta investendo somme ingenti, soprattutto all’interno di quelle aziende che sviluppano prodotti e servizi basati su pochi LLM, sia closed source che open source, ma principalmente frutto del lavoro di poche grandi aziende. Per approfondire, ti suggerisco di leggere due interviste recenti, ma precedenti ai cinque giorni e quindi privi di bias relativi, a Sam Altman, CEO di Open AI, e Ilya Sutskever, Chief Scientist e Co-fondatore di Open AI. Premetto che avevo ed ho stima di Altman come imprenditore e anche leader di una vera azienda tecnologica e di Sutskever come tecnologo in questo ambito.
La prima intervista è a Sam Altman e risale a settembre 2023, condotta dall'Intelligencer, una prestigiosa rivista online di New York, curiosamente in occasione di Wisdom 2.0, un forum dedicato alla fusione tra saggezza e le grandi tecnologie del nostro tempo, dove Sam era seduto accanto a Jack Kornfield, il monaco buddista più in vista della Silicon Valley. È un'intervista lunga e complessa, quindi non la riassumerò qui. Tuttavia, la frase di Altman che più mi ha colpito è stata: “He’s aware that he’s pretty disconnected from the reality of life for most people.”
L'altra intervista, quella a Ilya Sutskever, si trova nell'edizione online del MIT Technology Review. Emerge la sua natura meno istrionica rispetto a Sam Altman e una maggiore introversione, ma una visione non troppo diversa. Tuttavia, traspare una certa incertezza di fondo, che forse lo ha portato a prendere una decisione molto umana ma poco prevedibile durante quei cinque giorni matti. Il suo voto nel board è stato decisivo per il temporaneo licenziamento di Altman.
Entrambi mi sembrano comunque immersi in quell’altruismo efficace di cui tanto si parla soprattutto nella parte Ovest degli Stati Uniti.
E per una meta-analisi 🙂, dopo aver scritto queste righe, ho fatto confrontare a Chat-GPT4 le personalità dei due chiedendogli di basarsi esclusivamente sulle informazioni presenti nelle due interviste. Per non allungare troppo questa newsletter, ti lascio il link all’analisi completa. Credo che Chat-GPT4 li abbia descritti meglio di quanto abbia fatto io, dimostrando che il miglior LLM in circolazione sia già abbastanza abile nel capire qualcosa degli umani. Questo mi inquieta e, allo stesso tempo, mi rassicura …
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!
Buongiorno, potrei chiedere il link al post di Borruso? Cliccandoci sopra mi rimanda al suo Substack che però mi risulta vuoto... :( Grazie!