

LaCulturaDelDato #110
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il centodecimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del centodecimo numero:
👅Etica & regolamentazione & impatto sulla società. Navigare la complessità con
: dati, mappe e aperture (anche algoritmiche) di possibilità …Presentati:
Mafe De Baggis. Pubblicitaria atipica, perché prestata al digitale fin dai primissimi tempi, da metà negli anni ‘90. Sempre un po’ fuori posto, troppo pubblicitaria per il mondo della tecnologia, troppo tecnologica per il mondo della pubblicità, ma alla fine mi sono resa conto di prosperare nelle terre di mezzo tra più mondi. Ho da sempre associato la ricerca di metodi e processi al lavoro creativo e ogni tanto concretizzo la mia ricerca in un libro, più saggi che manuali. L’ultimo è In principio era ChatGPT (scritto con

Il mio ruolo tra 10 anni sarà ... (continua la frase come fossi GPT-10)
molto più spostato sulla ricerca ma senza mai perdere di vista l’applicazione concreta di quanto pensato, per passare dall’eternal beta di Google all’eternal testing di tutto. Tra dieci anni, se non ci spaventiamo, avremo abbandonato del tutto l’idea di piano sequenziale per lavorare solo sull’apertura di possibilità, come Heinz von Foerster suggeriva già decenni fa. È l’azione che genera la realtà e la competenza centrale per i prossimi anni è la comprensione dei sistemi complessi, con tanti software nel team.
Quale è la sfida più importante che il mondo dei dati e algoritmi ha di fronte a sé oggi?
Un lavoro intelligente e collaborativo sulla propria reputazione, che parte dal togliere tutti gli scheletri dagli armadi per arrivare a una chiara e trasparente descrizione del modo in cui i dati vengono usati e del funzionamento degli algoritmi, dichiarando quando generano comportamenti emergenti (cioè non causali) e perché. Un lavoro prima di tutto di legal design e di linguaggio, poi di comunicazione: finché le persone avranno paura degli abusi dei dati perderemo molte delle possibilità che abbiamo, in particolare in campo medico, fiscale e di lotta al disastro climatico.
Segnalaci il progetto o la risorsa nel mondo dei dati di cui non potresti fare a meno …
Più che un singolo progetto, una community circolante: quella degli appassionati di cartografia, che comprende veri e propri artisti, guide di viaggio per perdersi e migliaia di persone che cercano, creano e pubblicano mappe che aiutano a vedere il mondo in modo diverso. A colorarlo, come fa da anni Stamen Study o a immaginare mondi alieni.
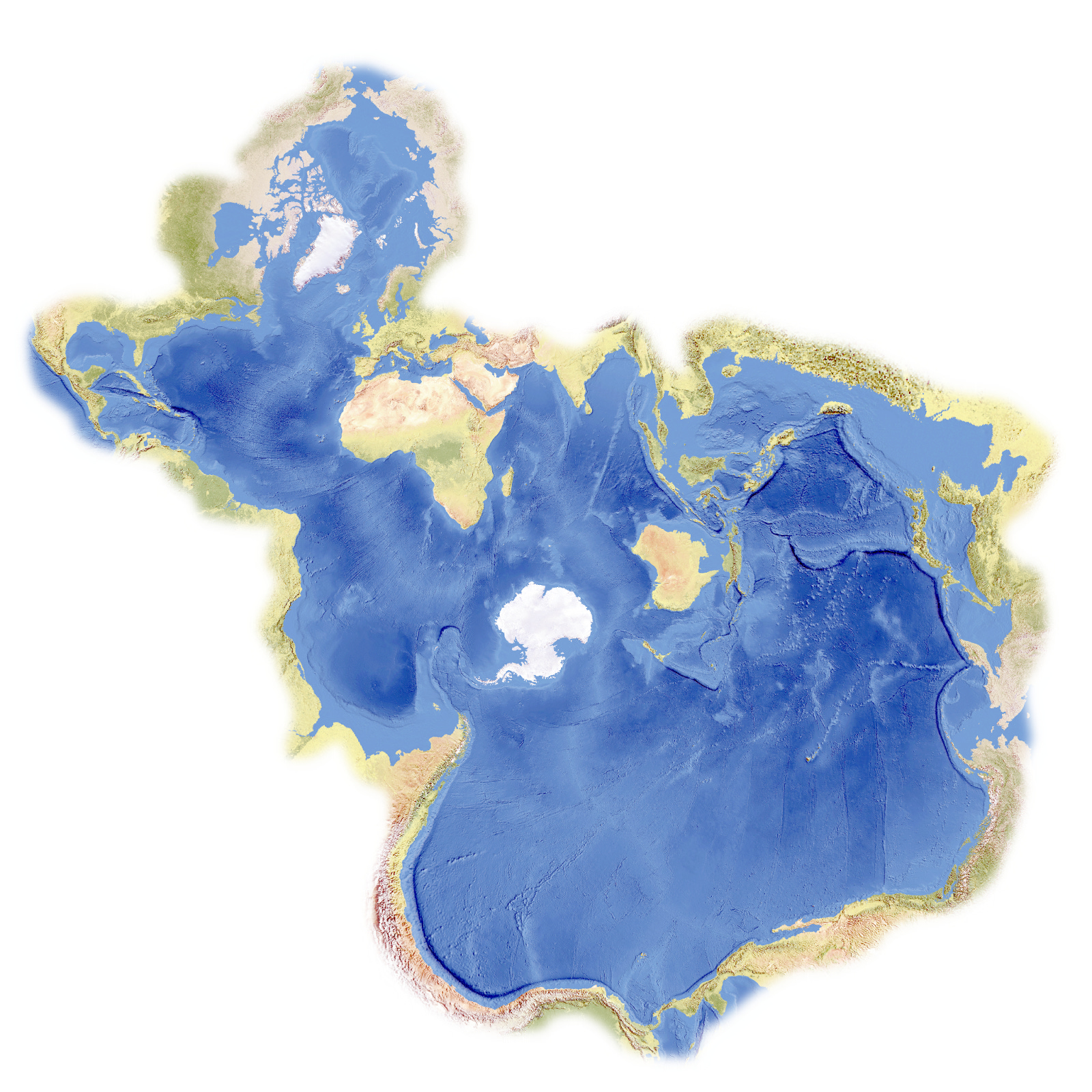
Ho una particolare propensione alle mappe isocrone e in genere alla visualizzazione integrata di altri dati, come il tempo di percorrenza o l’altitudine, ma anche la ricchezza o la salute o la felicità. C’è solo un tipo di mappa che detesto, quella politica. Il poter togliere i confini almeno da una visualizzazione è un superpotere. La mia preferita in assoluto? La proiezione di Spilhaus, che visualizza la realtà del nostro pianeta, più Acqua che Terra. Eccola …
PSS (Post Scriptum di Stefano): quando cerco uno dei libri di Mafe nelle librerie, trovo sempre quello che non sto cercando 🙂. Nonostante cerchi di sistemare i libri dello stesso autore in un’unica area tematica con quelli di Mafe non ci riesco mai! Questo mostra quanto ampia sia quella terra di mezzo dove ama prosperare. Ed è in questa terra di mezzo che, come ho già confessato più volte, è nata questa newsletter. Si perché l’aiuto di Mafe è stato molto importante nella fase di progettazione e partenza di questo progetto ed è di ispirazione continua per la sua capacità di navigare agilmente la complessità del presente senza perdere di vista passato e futuro.
👃Investimenti in ambito dati e algoritmi. Effetto Lindy e Vertical AI
"L'effetto Lindy (conosciuto anche come Legge di Lindy) è un ipotetico fenomeno per cui la speranza di vita di cose non deperibili (come tecnologie o ideali) è direttamente proporzionale alla loro età. In pratica, se un'ideologia o un'innovazione è sopravvissuta per molto tempo, allora si prevede che vivrà ancora più a lungo rispetto a una novità". Così viene descritto l’effetto Lindy dalla voce italiana di Wikipedia. E’ Nassim Taleb che mi ha fatto innamorare di questo concetto, spesso citato nei suoi libri. Taleb lo menziona, tra le altre cose, come consiglio ai giovani, suggerendo la lettura dei classici anziché delle novità editoriali, dato che i primi, essendo resistiti così a lungo, offrono probabilisticamente più spunti formativi.
Ma perché parlo dell'effetto Lindy? Lo faccio per introdurre l'argomento di oggi, un'analisi che risale a giugno 2023 - praticamente un'era geologica nella tecnologia di oggi. Sto parlando della tesi di investimento di un fondo di venture capital americano Greylock che seguo da tempo, noto per la sua capacità di adattarsi alla dinamicità moderna.
Oggi, più che mai, nel mondo degli investimenti si sottolinea l'importanza di un approccio verticale nella creazione di applicazioni software basate sulla generative AI. Se ne discute ampiamente, ma l'articolo di giugno 2023 rimane uno dei migliori per comprenderne le ragioni, fornendo un solido framework di supporto. E, come si dice, un'immagine vale più di mille parole - ecco quindi l'immagine chiave che riassume quasi tutti i componenti della tesi:

Concordo quasi in tutto, in particolare sull'importanza della conoscenza di dominio verticale e dell'esperienza degli imprenditori, così come sulla strategia multi-prodotto e/o su flussi di entrate aggiuntive per incrementare il valore del ACV (contratto medio annuale). Come suggerito nelle conclusioni, "siamo agli inizi di un incredibile periodo di innovazione... poiché la specializzazione verticale e l'AI adattata al dominio specifico" hanno il potenziale di generare valore duraturo. Per chi è interessato ad approfondire gli ultimi investimenti di Greylock, in particolare il loro 17esimo fondo e il nuovo programma Edge, pensato per supportare le idee nella loro fase iniziale, consiglio questo articolo su TechCrunch.
🖐️Tecnologia (data engineering). Privacy e Controllo: Scopri le Nuove Frontiere dell'AI con Jan.ai e Open Interpreter
Non credo che sarà il modo più frequente con cui useremo i nostri assistenti personali AI, ma gli approfondimenti che ti propongo in questa sezione riguardano due tecnologie utili se desideri utilizzare i tuoi dati in modo sicuro e offline anche con gli attuali LLM
La prima soluzione è jan.ai, una piattaforma innovativa di intelligenza artificiale che consente agli utenti di utilizzare gli LLM direttamente sui propri dispositivi, senza la necessità di connessioni a server esterni (ma puoi connetterti anche a servizi remoti). Questo approccio "local-first" offre maggiore privacy e controllo sui dati, rispetto alle soluzioni basate sul cloud. L’esperienza d'uso è gradevole (la sto provando in ambiente Windows, ma esiste il client anche per Linux e Apple) ed è facilissimo scaricare in locale i principali modelli Open e interagire con essi. Chiaramente, la velocità di interazione dipende dalle risorse a disposizione sul tuo PC e dalla grandezza del modello che hai scaricato. Questo è il limite più forte perché anche l’esperienza d'uso di un modello leggero non è paragonabile in termini di velocità a quanto siamo abituati con soluzioni cloud come ChatGPT4. Anche l’esperienza di personalizzazione dei modelli, come l’interazione con alcuni parametri come la temperatura, è facile ed agevole.
La seconda soluzione è Open Interpreter, che in realtà fa qualcosa di leggermente diverso rispetto a Jan.ai. Infatti, è una piattaforma open-source che offre un'interfaccia in linguaggio naturale per l'esecuzione di codice sul tuo computer, funzionando come un'alternativa locale al Code Interpreter di OpenAI. Questa caratteristica permette agli utenti di godere di maggiore privacy e controllo sui loro dati, dato che tutto viene eseguito localmente senza la necessità di connessioni a server esterni se non per la scrittura del codice, a meno che non usi anche per questo modelli che girano in locale. Codice e soprattutto dati e documenti rimangono tutti in locale Questa piattaforma si rivela un'ottima scelta per sviluppatori, ricercatori e hobbisti che desiderano esplorare e sfruttare le potenzialità dell'intelligenza artificiale mantenendo un pieno controllo sui loro ambienti di sviluppo e sui propri dati.
Entrambe potrebbero essere soluzioni maggiormente adottate se l’accoppiata Language Model Open e SLM (Small Language Model) sarà la direzione verso cui l’attuale stream di generative AI si indirizzerà. Non ho granitiche certezze ma non mi sento al momento di escluderlo!
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Navigare la Rivoluzione AI: Start-up o grandi aziende?
"Cosa ci riserva questa nuova rivoluzione dell'AI? I maggiori benefici saranno appannaggio delle aziende con ampie quote di mercato e risorse cospicue, o saranno riservati alle startup, agili e capaci di creare esperienze nuove e coinvolgenti?" Questa domanda apre l'approfondimento che oggi ti condivido. E, credimi, non si tratta solo di una questione di investimenti. Riguarda anche il futuro di chi lavora in qualsiasi organizzazione. Ed è per questo motivo che l'ho scelta per questa sezione della newsletter.
La domanda "È meglio lavorare, ora e nel prossimo futuro, in una startup o in un grande gruppo aziendale?" mi viene posta sempre più spesso, in incontri pubblici e privati. Se ti aspetti una risposta semplice e diretta, ti invito a passare alla prossima sezione della newsletter: qui non voglio farti perdere tempo. Le questioni complesse raramente hanno risposte semplici. Credo che, in questo momento, sia fondamentale porsi la domanda, riflettere ed esplorare anche aspetti quali le proprie inclinazioni personali e il contesto specifico del settore e dell'azienda, tutte cose che vanno oltre l'impatto della AI generativa. Tuttavia, se desideri esaminare l'effetto delle nuove evoluzioni dell’AI nel tuo settore, questo articolo può offrirti un prezioso punto di partenza. Come ho già accennato nella sezione sugli investimenti di questa settimana, un'immagine può riassumere efficacemente i concetti chiave dell'articolo. Eccola.

L'agilità a vantaggio delle startup e, al contrario, i dati e la conoscenza in mano ai grandi player emergono in aggiunta, a mio parere, come fattori cruciali. E per citare direttamente l'articolo: "In molti mercati, gli attori storici sono semplicemente troppo lenti nell'adozione dell'IA per competere con una startup che funziona a pieno regime. Questa è una delle ragioni per cui l'IA promette di essere così rivoluzionaria in settori tradizionalmente arretrati, come il govtech, la sanità, il mondo legale, l'edilizia e l'istruzione. Gli attori tradizionali sono più lenti nell'adattarsi (quando non sono completamente assenti)".
Concludo questa sezione, dedicata al dilemma tra i pro e i contro del lavorare in una startup o in un'azienda leader di mercato, segnalandoti il report di un'azienda americana, Carta, che gestisce processi retributivi per un significativo numero di startup statunitensi e pubblica periodicamente dati sull'occupazione e, in particolare, sulla retribuzione in queste realtà. Sebbene non sia direttamente applicabile al contesto europeo, almeno non nello stesso lasso di tempo, offre un'indicazione su come il mercato stia vivendo una contrazione occupazionale e una stabilizzazione dei salari. Ma il report è pieno di dettagli imperdibili!
👀 Data Science. Oltre le percentuali: misurare l'effettiva bontà delle previsioni “probabilistiche”
Le previsioni che facciamo o che abbiamo a disposizione attraverso i nostri modelli di data science esprimono a volte una probabilità che un determinato evento si verifichi. Pensiamo, per esempio, alla previsione meteorologica quotidiana, spesso espressa in percentuale. Tuttavia, esistono molti altri ambiti in cui l'output di un modello può rappresentare la probabilità di perdere o acquisire un cliente specifico, o di verificarsi di un particolare rischio. L'approfondimento di oggi mira a chiarire come misurare l'efficacia di queste previsioni basate su probabilità. L'articolo esamina e cerca di sintetizzare in un unico indicatore quello che definisce due misure distinte di previsione: l'accuratezza, ovvero quanto le previsioni si avvicinano alla realtà complessiva, e il discernimento, che si riferisce alla tua capacità di fornire previsioni significative puntuali. Prendendo l'esempio della pioggia: se in una regione piove il 30% dei giorni, potresti essere tentato di prevedere quotidianamente il 30% di probabilità di pioggia. Questo ti rende accurato in media, ma in realtà non stai prevedendo nulla di specifico; stai solo ripetendo una statistica generale. Il discernimento è la tua abilità di andare oltre questa media, ad esempio prevedendo l'80% di probabilità di pioggia in un giorno specifico in base all'analisi di particolari pattern meteorologici.
Concretamente, il discernimento rende il tuo modello veramente utile, permettendogli di offrire intuizioni specifiche e personalizzate basate sui dati disponibili, piuttosto che ripetere medie generali. Un modello con elevato discernimento è in grado di individuare e sfruttare le sottili variazioni nei dati per fare previsioni più precise e informative.
È vero che possiamo considerare il nostro problema (come quello della previsione della pioggia) un problema di classificazione e applicare le metriche standard. Il concetto di "discernimento" infatti si relaziona alla curva ROC (Receiver Operating Characteristic) e all'area sotto la curva ROC (AUC-ROC), che misurano la capacità di un modello di distinguere tra classi in scenari con soglie decisionali variabili. Tuttavia l'approccio, nella parte finale dell’articolo, di misurazione globale attraverso l'aggregazione dei due indicatori (accuratezza e discernimento) in un unico valore riassuntivo, il Forecasting Error Score, offre una prospettiva alternativa per valutare le previsioni, soprattutto, a mio avviso, in situazioni molto sbilanciate, dove l'evento da prevedere è raro e il suo impatto è elevato. Per gli appassionati di approfondimenti 🙂, l'articolo propone altri metodi per valutare l'affidabilità dei sistemi previsionali probabilistici, come il Brier score, che ho trovato particolarmente interessante!
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!