

LaCulturaDelDato #116
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il centosedicesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del centosedicesimo numero:
👀 Data Science. Algoritmi e didattica: Luigi Laura e la sfida della formazione delle nuove generazioni
Presentati
Luigi Laura. Quando facevo la quinta elementare mio padre mi portò dall'Inghilterra un Sinclair ZX81, uno dei primi veri personal computer. Solo un kilobyte di RAM e un interprete BASIC a disposizione all'accensione. Da lì è iniziata la mia passione per gli algoritmi... adesso, dopo una laurea e un dottorato in Ingegneria Informatica, entrambi in Sapienza, sono Professore Associato presso Uninettuno dopo aver insegnato, strada facendo, in Sapienza, Tor Vergata e Luiss. Faccio ricerca principalmente su algoritmi e sono il presidente del Comitato per le Olimpiadi Italiane di Informatica, una competizione per gli studenti delle superiori che ogni anno coinvolge più di quindicimila ragazzi. E da due anni abbiamo lanciato i Giochi di Fibonacci, una competizione per ragazzi delle medie e degli ultimi due anni delle elementari: già in ventimila si sono cimentati e divertiti, imparando gli algoritmi e l'informatica!

Il mio ruolo tra 10 anni sarà ... (continua la frase come fossi GPT-10)
Penso che continuerò a cercare di spiegare alle persone che gli algoritmi, e l'informatica, esistono da migliaia di anni, ben prima della nascita dei computer. Cito spesso una frase di un famoso informatico, Dijkstra, che non a caso appare nella retrocopertina del mio libro: "L’informatica riguarda i computer non più di quanto l'astronomia riguardi i telescopi". E continuerò a cercare di mitigare il fatto che le Olimpiadi di Informatica siano tra i più grandi produttori di cervelli in fuga, a cominciare da Foschini e Signorini, che negli USA hanno fondato una azienda - ormai un colosso - incentrata sull'analisi di dati biomedici.
Quale è la sfida più importante che il mondo dei dati e algoritmi ha di fronte a sé oggi?
Portare le persone a capire che gli algoritmi e i dati vanno compresi in prima persona, non delegando le IA per noi. Al MIT hanno creato un linguaggio di programmazione visuale, Scratch, adatto anche a bambini delle elementari. L'inventore di questo linguaggio, Mitch Resnick, ha detto: "learn to code, code to learn", che sottoscrivo pienamente e ripeto spesso ai miei studenti: dobbiamo imparare a programmare non per diventare programmatori ma per poter imparare altre cose. D'altronde abbiamo imparato a scrivere non per diventare scrittori, no? E anche se non siamo dei cuochi provetti quasi tutti sappiamo cucinare, almeno pochi piatti.
Segnalaci il progetto o la risorsa nel mondo dei dati di cui non potresti fare a meno …
So che è una risposta molto gettonata, ma in primis direi sicuramente la tua newsletter, ed è per me un onore apparire qui. Poi probabilmente aggiungerei una piattaforma, Medium, dove si trovano articoli di qualità su tanti argomenti, compreso il mondo dei dati: ormai mi affido al loro "recommender system" per trovare articoli di mio interesse e ci riesce spesso. E concludo nominando Stephen Few, i cui libri non possono mancare nella libreria di chi si occupa di dati... su tutti cito Signal - "understanding what matters in a world of noise" - e Big Data, Big Dupe, una analisi critica sul mondo dei Big Data e sull'effettivo valore che spesso (non) hanno.
🖐️Tecnologia (data engineering). Si fa presto a dire “multi-cloud”!
“Per quelli di noi che stanno ancora imparando, sì, vogliamo imparare un provider cloud prima di imparare tutti i provider cloud, non prendiamoci in giro. Sceglietene uno, puntate tutto su di esso per il momento e non preoccupatevi di ciò che fa il resto del settore. Non stiamo cercando di raccoglierli tutti. Non esiste un Magic Quadrant di Gartner per i Pokemon e non credo che i cloud provider debbano essere tra questi.”
L’articolo che ti propongo oggi nella parte tecnologica tratta il tema del multi-cloud con molto sarcasmo ma anche tanto realismo. Sono decisamente d’accordo con buona parte dell’articolo, che in sostanza ci raccomanda di scegliere il cloud, quando lo riteniamo utile, con consapevolezza, abbracciando i vantaggi che ci porta e cercando di scegliere quello che oggi ci offre più benefici. E quando parliamo di dati e di intelligenza artificiale i vantaggi sono tanti, soprattutto in termini di velocità e innovazione.
Molto più difficile, invece, è parlare di reale multi-cloud perché ci sono, dal punto di vista architetturale, almeno tre situazioni (lo so, sto iper semplificando 🙂)
a) Workload che fluisce tra più cloud: in questo caso, un'unica applicazione viene distribuita su più provider cloud, con la possibilità di spostare il carico di lavoro tra di loro.
b) Workload differenti su provider cloud differenti: in questo scenario, diverse applicazioni o servizi vengono utilizzati su provider cloud differenti, a seconda delle loro specificità o dei requisiti aziendali.
c) SaaS su più cloud per esigenze di dati: un'applicazione SaaS viene utilizzata su un unico cloud, ma i dati vengono distribuiti su più provider in base alla posizione dei clienti.
A questo si aggiunge un tema, spesso troppo dimenticato, della conoscenza dei diversi cloud da parte dei team che li usano. Non è facile ed è anche costoso in termini di tempo gestire questa conoscenza su più cloud. Per non parlare del fatto che i vari strumenti presenti sui diversi public cloud non sono esattamente interoperabili come ci viene raccontato.
Per questo, quando si parla di multi-cloud, cerchiamo di farlo con consapevolezza, serenità e realismo, distinguendo il fatto che usiamo più cloud dall’essere riusciti a mettere in campo una reale strategia “multi-cloud”. 🙂
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Navigare nel Mondo dei Dati e dell’AI: corsi e consigli per la formazione e informazione
Dal momento che mi scrivete sempre in molti su questo tema, e mi fa molto piacere visto che è anche una mia passione personale, dedico questa sezione della newsletter alla formazione su tematiche di AI e dati. Sì, perché quando si parla di cultura dei dati e algoritmi all’interno delle organizzazioni, non si può fare a meno di parlare di formazione, che è uno dei quattro pilastri della cultura del dato. Prima di fornirti l’approfondimento di oggi, faccio tre osservazioni sullo scenario attuale in cui si muove la formazione, integrandole con qualche consiglio personale:
1. Esiste una grandissima offerta sul mercato di corsi molto tecnici, orientati dai vendor, soprattutto dei più importanti cloud provider, ma non solo. La cosa è positiva, ma tende a limitare la formazione più al come che al cosa (serve fare).
2. Esiste una grandissima offerta anche di webinar e momenti in cui vengono presentati dati e informazioni dalla prospettiva business, ma con pochi collegamenti alla parte più concreta e pratica.
3. I due approcci che preferisco sono quelli utilizzati da Andrew Ng e Ethan Mollick, che cito spesso in questa newsletter. Il primo, che è stato anche co-founder di Coursera, ha dedicato alla formazione e informazione una parte della sua attuale vita professionale creando un’iniziativa molto interessante. Il secondo, Ethan Mollick, ha una prospettiva più legata al business e all’innovazione, e attraverso i suoi frequenti post e il suo recente libro, che ti consiglio, fornisce aspetti di formazione molto pratica per chi lavora in azienda. Non esiste, per mia visibilità, il mix dei due approcci, altrimenti te lo consiglierei assolutamente.
Fatta questa lunga premessa, ti condivido l’approfondimento di oggi, che è un breve ma utile post di Bernard Marr sui migliori corsi a pagamento sulla generative AI. All’interno del post trovi il link a un post simile riservato anche ai corsi gratuiti.
Se ti ho ulteriormente confuso le idee o vuoi esprimere il tuo parere su questi temi, scrivimi o suggerisci nei commenti corsi o il tuo punto di vista sull’argomento.
👃Investimenti in ambito dati e algoritmi. Investimenti AI: scopri le nuove tendenze con Dealroom
Il 6 maggio a Parigi, durante un evento dedicato all’intelligenza artificiale, Dealroom, un’azienda che gestisce una delle migliori banche dati mondiali sugli investimenti innovativi, in particolare venture capital, ha presentato un documento che sintetizza l’attuale stato degli investimenti nel settore dell’intelligenza artificiale a livello globale, con un focus specifico sull’ecosistema europeo. Il documento è scorrevole e, nonostante le sue 32 pagine, offre indicazioni interessanti anche per chi non conosce bene questo settore. Puoi scaricarlo, dopo aver lasciato la tua email, da qui.
Ti condivido 4 immagini del report, le più significative a livello globale, lasciandoti ulteriori approfondimenti sui differenti domini di interesse specifico.

Partiamo da questa immagine che mostra come gli investimenti in start-up focalizzate sull’intelligenza artificiale siano stabili. Considerando il decremento del mercato totale nel 2023 e nel 2024, questi numeri rappresentano una crescita significativa in termini relativi, con una quota di investimenti, rispetto al totale investito, del 20% nel settore AI e dell’8% nel sotto-settore generative AI.

In questa seconda immagine puoi vedere come si dividono le start-up in ambito generative AI a seconda del livello tecnologico. L’application layer domina in termini numerici ma non per i profitti (vedi immagine sotto) né per gli investimenti, dove prevalgono gli strati più bassi legati alla parte infrastrutturale. Probabilmente, come si vede dall’immagine che confronta la generative AI con il cloud, è soprattutto una questione di maturità.

Ti lascio con la quarta immagine che rappresenta, anche in termini di grandezza di mercato, i nove ambiti dove, secondo DeelRoom, si gioca la partita più interessante per quanto riguarda gli ambiti applicativi dell’AI.

Se poi vuoi vedere un’analisi più dettagliata di queste aree e la distribuzione geografica degli investimenti e degli ecosistemi, la parte finale del report è decisamente analitica e molto interessante.
👅Etica & regolamentazione & impatto sulla società. Scopri il BES Istat: Il rapporto che tutti dovremmo leggere (anche se non prima di dormire 🙂)
Il rapporto realizzato ogni anno dall’Istat BES (Benessere Equo e Sostenibile in Italia) ha il potere di peggiorare la qualità del mio sonno almeno per un giorno all’anno 🙂. Ogni anno, infatti, comincio a leggerlo dopo cena pensando di cavarmela in qualche decina di minuti e poi mi ritrovo a scavallare la mezzanotte con un sacco di riflessioni in testa, e l’Oura ring implacabilmente, il giorno dopo, mi bacchetta con punteggi bassissimi relativi al sonno
Vicissitudini personali a parte, il BES è, o meglio dovrebbe essere, uno dei documenti più importanti per la nostra nazione, ai fini di capire il presente e le decisioni che dobbiamo prendere per migliorare la qualità di vita di tutti noi. Sfortunatamente, è ancora largamente sottoutilizzato. Con le sue 300 pagine, la sua divisione in 12 aree tematiche (Salute, Istruzione, Lavoro e conciliazione dei tempi di vita, Benessere economico, Relazioni sociali, Politica e istituzioni, Sicurezza, Benessere soggettivo, Ambiente, Qualità dei servizi) e i suoi 152 indicatori, è un documento veramente unico. Anche la presenza, della quasi totalità degli indicatori, del confronto con gli altri stati europei e la suddivisione di questi indicatori su base regionale e sul livello di istruzione lo rende molto utile anche come indicatore di direzione e di disomogeneità.
Veramente difficile fare sintesi o chiavi di lettura, ma ci provo comunque:
- A partire da pagina 9 trovi una trentina di pagine che ti forniscono una buona visione d’insieme.
- Tutti i capitoli sono interessanti e utili, ma se te ne devo consigliare uno: il primo sulla salute è il mio preferito.
Globalmente, i segnali sono positivi nel senso che la maggior parte degli indicatori sono in miglioramento sia rispetto al 2022 che al 2019, un benchmark importante perché è l’ultimo anno pre-pandemia. Ma non tutti sono in miglioramento.
Ho scelto anche due grafici molto significativi:
1. Il primo è relativo a un insieme di indicatori di benessere che confrontano il livello italiano rispetto alla media europea. Questo grafico è impietoso nel mostrare quanto siamo indietro su temi strategici quali equità di genere, digitale e produttività.

2. Il secondo mostra la differenza su base regionale relativamente a due indicatori fondamentali: la lunghezza della vita (LifeSpan) e la lunghezza della vita in buona salute (HealthSpan).
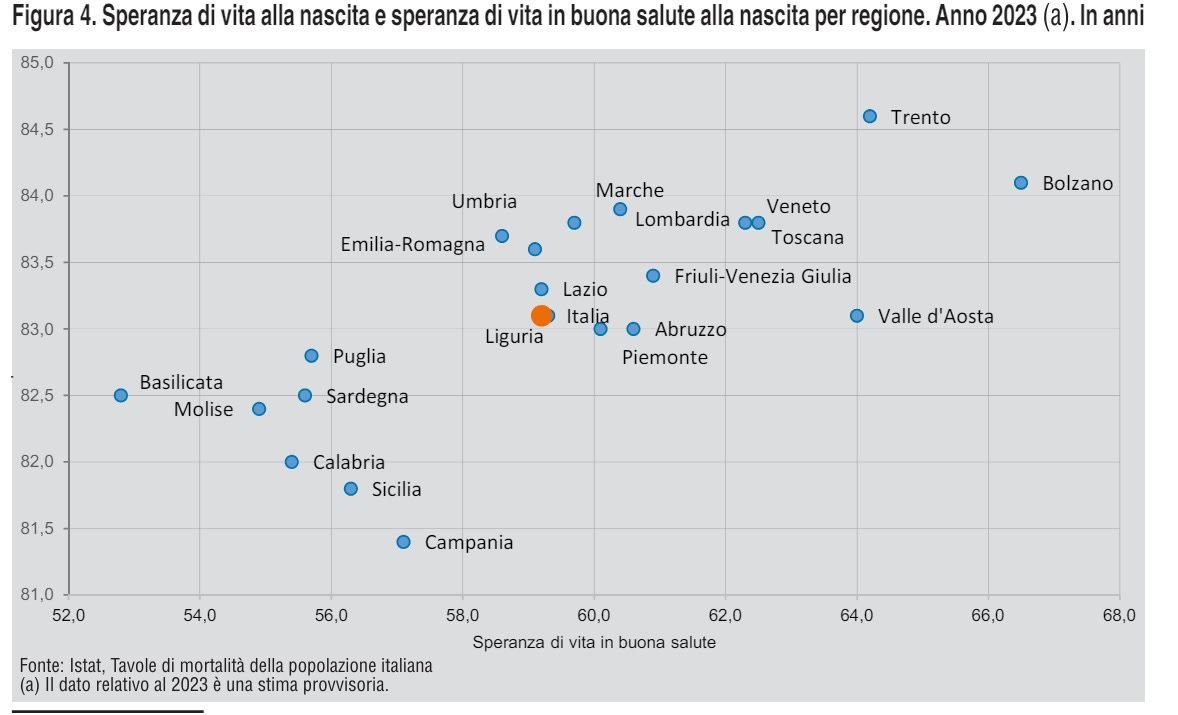
Ma c’è tantissimo altro nel BES: auguro anche a te (come data-lover) una notte con meno ore dormite, ma mi raccomando, non commettere l’errore che ho fatto io di vedere al mattino il punteggio della qualità del tuo sonno 🙂.
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!
Riguardo i suggerimenti per percorsi di auto formazione, ieri ho letto un articolo di KayDee su Medium che suggerisce un piano di apprendimento per acquisire da zero fondamenti di python, matematica e data science. Ho dato in pasto l'articolo a Perplexity, chiedendo un piano di apprendimento per un'ora al giorno, su risorse didattiche nei tre ambiti citati, il risultato è questo https://www.perplexity.ai/search/Crea-un-piano-_yIg9q5xQTmA0wDHlpzdZw