

LaCulturaDelDato #165
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il centosessantacinquesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del centosessantacinquesimo numero:
👃Investimenti in ambito dati e algoritmi. Abraham Thomas e il segreto per costruire un vantaggio competitivo con i dati
“Ogni volta che mi accingo a scrivere un saggio, mi riprometto che, questa volta, sarà breve e incisivo. Ma il processo stesso della scrittura apre nuove strade: emergono idee e intuizioni inaspettate, si svelano strutture e temi nascosti, affiorano dati, aneddoti, immagini ed esempi — e sento il bisogno di includerli, perché credo rendano i miei saggi più ricchi e completi. … La mia filosofia di scrittura è 'pochi, ma buoni'. Pubblico due o tre saggi l’anno. Ognuno di essi conta tra le 5.000 e le 7.000 parole, richiede da due a otto settimane di scrittura intensa e almeno cinque o sei mesi di riflessione a monte. Scrivo solo quando sento di avere qualcosa di significativo, originale e concreto da dire. Mi avvalgo di Claude come compagno di pensiero e assistente nella ricerca, ma ogni singola parola (e ogni singolo trattino lungo) è scritta da me.”
Credo che Abraham Thomas, con cui ho avuto il piacere di parlare e di intervistare nell’edizione inglese di “La Cultura del Dato”, sia una delle persone che conosce meglio il business dei dati e le sue dinamiche, grazie a una capacità rara di unire conoscenze ed esperienza tecnica con quella di aver creato un business basato sui dati e averlo venduto con successo al Nasdaq. Ed oggi continua a studiare, approfondire ed investire nel mondo dei dati e della AI.
Per questo, quando pubblica un nuovo saggio, mi prendo qualche ora per leggerlo almeno due volte. Sì, perché per essere capito a fondo vanno lette anche le note — e in alcuni casi approfondite. Nel saggio che ti consiglio oggi ce ne sono ben 45.
Ma non ti voglio intimorire: le note, come il testo del saggio, scorrono in maniera molto fluida.
E poi oggi
Il tema è il vantaggio competitivo dei dati, che in inglese Thomas definisce “data moat”. Trovo questo argomento particolarmente importante perché proprio i dati, quando si valuta un investimento, possono rappresentare l’ultimo e reale vantaggio competitivo duraturo per una start-up o una scale-up.
Non si può assolutamente sintetizzare “Data and Defensibility” in poche righe. Ti lascio però qui le due bellissime mappe che Abraham Thomas ha costruito per descrivere le due categorie di data moat:
Data Control

Data Loops



E ora è tempo di godertelo: rilassati, silenzia lo smartphone e dedica almeno 45 minuti all'ultimo capolavoro di Abraham Thomas. 🚀
🖐️Tecnologia (data engineering). Farsi trovare dagli LLM: la sfida spiegata da Andrew Ng
È molto difficile avere una stima di quanto stia cambiando la ricerca online attraverso i motori di ricerca tradizionali (come Google, che ha circa il 90% del mercato attuale) nei confronti della ricerca attraverso strumenti di intelligenza artificiale generativa come ChatGPT.
Stime, a mio giudizio prudenziali, dicono che nel 2025 raggiungerà l’1%. È anche molto difficile misurare questo valore, sia perché è complicato definire quando un'interazione con un LLM sia effettivamente una ricerca, sia perché i sistemi generativi più diffusi sono chiusi e non forniscono pubblicamente queste informazioni. Detto questo, il processo è in corso, e la stessa mossa di Google di lanciare il servizio AI Overview è una testimonianza che questa migrazione è in atto.
Proprio per questo, farsi trovare da un LLM – o meglio, comparire all’interno di una risposta generata da un’intelligenza artificiale – sarà sempre più importante, andando probabilmente a modificare anche il mondo dell’e-commerce.
Chi si occupa di tecnologia dovrebbe quindi prepararsi ai cambiamenti (tecnologici) necessari per farsi trovare più facilmente.
È questo il senso di un interessante editoriale di Andrew Ng, sulla sua newsletter online The Batch, che fa esempi concreti di questa nuova esigenza, delineando due possibili scenari:
Le intelligenze artificiali diventeranno così brave a fare quello che viene chiamato web crawling da riuscire a estrarre contenuti e classificarli anche da siti web complessi, bravi come un essere umano (ma su larga scala).
Sarà necessario, per rendere più visibili e facilmente accessibili agli LLM i contenuti, sviluppare uno standard simile al robot.txt del web 2.0.
Tra chi pensa che questo secondo scenario sia più probabile, c’è chi sta proponendo uno specifico standard, LLMS.txt, che ha visto la luce verso la fine dello scorso anno.
Iniziare a darci un’occhiata potrebbe essere utile, visto che da allora il dibattito e alcuni primi casi di utilizzo sembrano prendere piede… 🚀
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Come assumere i leader giusti: i consigli (super pratici) di Vinod Khosla
Vinod Khosla è un imprenditore e venture capitalist di origini indiane, fondatore di Khosla Ventures, una delle azinede di venture capital più rispettate della Silicon Valley. Nato in India nel 1955, dopo aver studiato in prestigiose università indiane e americane, è stato uno dei co-fondatori di Sun Microsystems nel 1982, azienda pioniera nello sviluppo di tecnologie (Java è nato lì). Nel 2004 ha fondato Khosla Ventures, fondo che investe in startup tecnologiche, cleantech, healthcare e innovazioni "high risk, high reward".
Tutti gli articoli che ho letto a sua firma mi hanno fatto profondamente riflettere, perché contengono un sano pragmatismo che arriva dalla lunga frequentazione del mondo americano della Silicon Valley, contaminato da una cultura che arriva da Est (del mondo). E questo si percepisce anche nell’articolo che ti propongo oggi, che ha un obiettivo molto ambizioso: “How to hire”. In realtà si focalizza sul processo di selezione di risorse executive lungo tutto il ciclo di vita di una start-up (dalla creazione fino all’IPO). Penso però che si adatti bene anche all’approccio da tenere nella selezione di figure di leadership anche in aziende più tradizionali.
I concetti che più condivido, e che non sono ancora così mainstream in Europa (almeno per il momento), sono tre:
La valutazione dell’obiettivo prioritario affidato al leader da selezionare
Quando si assume un leader, bisogna prima capire se il ruolo serve a creare valore (esplorazione, innovazione) o a proteggere valore (gestione, ottimizzazione). La modalità di selezione cambia radicalmente in base a questo.La ricerca di creatività e capacità di costruzione di team più dell’esperienza diretta nel settore e nel ruolo
Nel recruiting, soprattutto per ruoli di value creation, la capacità di pensare con logica, di imparare velocemente e di costruire team supera l'importanza dell'aver ricoperto un ruolo simile in passato.La definizione del candidato ideale che si basi su esempi reali, non su job description generiche
Piuttosto che creare specifiche irrealistiche, è meglio analizzare e commentare veri CV di candidati per identificare tratti positivi e negativi in modo concreto e realistico.
Ci sono anche molti altri concetti espressi nell’articolo, ma sono più specifici per aziende in fase di sviluppo piuttosto che per organizzazioni più stabili.
Se devo indicare qualcosa che manca nell’articolo — e che nella modernità avrà sempre maggiore impatto — è la capacità del leader di capire, lavorare e selezionare intelligenze artificiali adatte allo sviluppo dell'organizzazione. Senza esprimere concetti troppo forti come quelli del CEO di Shopify, credo che quella dell’AI recruiting sia una competenza che deve entrare nel CV di ogni leader 📈.
Se hai esperienze di selezione diretta o indiretta — in un senso (hai selezionato) o nell’altro (sei stato selezionato) — mi interessa molto sapere i tuoi commenti, le tue esperienze e il tuo punto di vista. Anche sull’AI recruiting 🙂!
👀 Data Science. PyCaret: il coltellino svizzero del machine learning (low-code)
PyCaret è una libreria open-source di machine learning in Python, progettata per semplificare e accelerare i flussi di lavoro attraverso un approccio low-code. Ti permette di condurre esperimenti end-to-end in modo rapido ed efficiente, riducendo drasticamente il tempo necessario per passare dall'ipotesi all'insight. È stata sviluppata da Moez Ali, un data scientist che ha avviato il progetto nell’estate del 2019. L’ispirazione per PyCaret arriva dal pacchetto caret del linguaggio R, creato da Max Kuhn, pensato per automatizzare i principali passaggi nella valutazione e comparazione di algoritmi di machine learning. Il nome "PyCaret" riflette proprio questa ispirazione, unendo “Python” e “caret”.
Era stato l’approfondimento più apprezzato nella puntata 45 della newsletter e ancora oggi è uno strumento molto utile, sia per chi si avvicina al mondo dei dati sia per data scientist più esperti. Tra le sue funzionalità più interessanti c’è la possibilità di confrontare rapidamente l’efficacia di diversi algoritmi su cinque delle categorie di problemi più comuni nella data science: classificazione, regressione, clustering, anomaly detection e time series.
Lo utilizzo con grande efficacia nel corso che tengo all’Università Cattolica, all’interno della laurea specialistica in Economia, la cui terza edizione è appena partita. PyCaret mi aiuta a mostrare velocemente agli studenti i diversi tipi di algoritmi disponibili, farli provare con mano e misurare le metriche di performance in modo immediato.
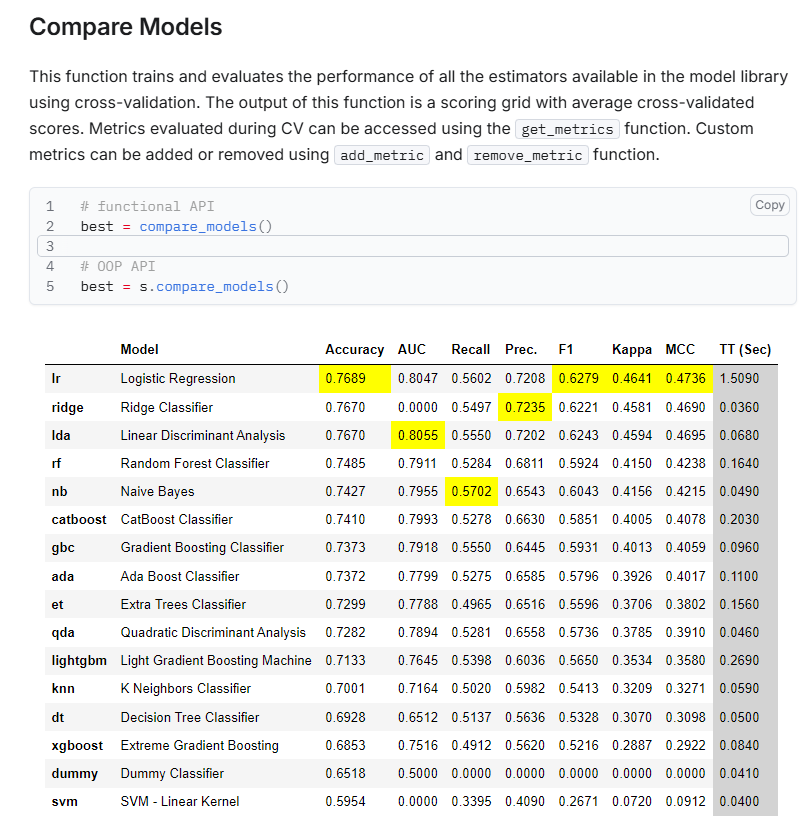
Se poi vuoi una recensione ancora più tecnica e dettagliata (oltre alla documentazione ufficiale, fatta molto bene), ti lascio questo articolo di Machine Learning Mastery che spiega proprio come usare PyCaret al meglio .
👅Etica & regolamentazione & impatto sulla società. Umberto Eco, Anne-Laure Le Cunff e l'arte immortale di fare liste
“Nell'Iliade appaiono due modi di rappresentazione. Il primo si ha quando Omero descrive lo scudo di Achille: è una forma compiuta e conchiusa, in cui Vulcano ha rappresentato tutto quello che egli sapeva – e che noi sappiamo – su una città: il suo contado, le sue guerre, i suoi riti pacifici. L'altro modo si manifesta quando il poeta non riesce a dire quanti e chi fossero tutti i guerrieri Achei: chiede aiuto alle muse, ma deve limitarsi al cosiddetto, e enorme, catalogo delle navi, che si conclude idealmente in un eccetera. Questo secondo modo di rappresentazione è la lista o elenco.”
Quella che ti ho appena trascritto è la sinossi di una delle opere che amo di più di Umberto Eco, e cioè il saggio Vertigine della lista, scritto a seguito di una serie di conferenze al Louvre nel 2009 proprio sull’argomento. Amo quest'opera perché, come scrive la voce di Wikipedia del libro, secondo Eco “La lista, o elenco, o catalogo, si usa quando di ciò che si vuole rappresentare non si conoscono i confini, quando le cose da rappresentare sono in numero molto grande o infinito, o quando qualcosa si riesce a definire solo elencandone le proprietà, che sono potenzialmente infinite.”
In questo senso, nella liquidità e dinamicità del mondo moderno, credo che la lista sia il modo migliore per descrivere la maggior parte dei fenomeni e delle cose.
Ho usato questa forma di raccolta – e, se vogliamo, anche di struttura – dei dati e delle informazioni in tanti momenti della mia vita, e la uso sempre più spesso per poter liberare la mente senza avere il timore di perdere per sempre informazioni.
Un modo più recente per chiamare le liste è quello di usare la parola inglese checklist: non è esattamente la stessa cosa, ma ci va molto vicino e incarna, a mio giudizio, lo stesso spirito. Ne ha scritto a proposito la mia “neuroscienziata preferita” Anne-Laure Le Cunff, che esprime in un'immagine la sua checklist ideale.

Toglietemi tutto ma non la possibilità di fare liste e di monitorarle 😄. Ah, dimenticavo: sono un boomer e quasi sempre sono rimasto fedele a carta e penna, che accentuano il piacere liberatorio della progressione nel completamento della lista stessa, o della checklist, nel caso serva appunto come strumento di avanzamento per prendere una decisione o completare un’attività.
Sei anche tu un list-lover?
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!
..complimenti Stefano, qui si mostra la tua versatilità da librerie python di valutazione a Umberto Eco! Chapeaux!
Due commenti oggi. (1) AI e hiring: segnalo una delle portfolio companies di Eden Ventures, https://anthropos.work/, simulazioni AI-based per rendere le situazioni di hiring e training il più possibile realistiche. Fondatore italiano a Silicon Valley; (2) una checklist è più di una lista: in molti ambiti è un indispensabile requisito di sicurezza: nel decollo di un aereo, nelle immersioni subacquee, nella preparazione di un’operazione chirurgica ecc.