

LaCulturaDelDato #166
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il centosessantaseiesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del centosessantaseiesimo numero:
🖐️Tecnologia (data engineering). Stefano Maestri: dal nerd al vibe coder, tra AI, open source e architetture del futuro
Presentati: Stefano Maestri. Senior Manager con oltre 25 anni di esperienza nello sviluppo software. Ho iniziato come sviluppatore, poi architetto e ora manager. Guido team globali che lavorano su middleware enterprise, servizi cloud e integrazione di AI.
Ma prima di tutto questo, nerd sempre innamorato dell’ultima tecnologia.
La mia esperienza copre sistemi operativi open source, server applicativi JEE, framework AI e sistemi multi-agente. Recentemente mi sono focalizzato su agentic-RAG multi agents framework e sto contribuendo a strategie tecniche per l'integrazione dell'AI nei runtime middleware attraverso MCP.
Il mio attuale focus è sulle potenzialità del vibe coding e su come il suo utilizzo da parte di team di sviluppatori senior possa rivoluzionare il modo di lavorare del gruppo e potenziarne i risultati. In questo contesto di trasformazione guidata dall’AI ritengo fondamentale l'open source per creare un ecosistema dove innovazione, collaborazione e tecnologie AI si alimentano reciprocamente.
Da poco ho iniziato a scrivere artifcialcode e codiceartificiale, due newsletter gemelle in lingua inglese e italiana, dove cerco di delineare i trends dell’AI. Digerisco news e informazioni, provo framework e modelli tutta la settimana e nel weekend provo a connettere i puntini e leggere tra le righe delle notizie, per cercare di individuare le tendenze, o meglio le tensioni che sono emerse nella settimana. Poi come tutti i fiumi in piena, non è detto che l’onda non cambi la settimana successiva, ma forse è anche il fascino di questo viaggio...almeno per un nerd sempre innamorato dell’ultima tecnologia.

Il mio ruolo tra 10 anni sarà ... (continua la frase come fossi GPT-10)
Il mio ruolo tra 10 anni sarà quello di un nerd sempre innamorato dell'ultima tecnologia :) ... con la non banale responsabilità di tenere insieme architetture complesse create da vibe coder con diverse sensibilità e da agenti intelligenti autonomi.
Le architetture software ed i team che gestirò saranno profondamente influenzate dall'AI e dagli agenti intelligenti, probabilmente molto più di quanto possiamo immaginare oggi. La sfida sarà integrare il meglio della creatività umana potenziata dal vibe coding con l'efficienza e le capacità degli agenti AI, creando sistemi che siano più della somma delle loro parti.
Mi aspetto di lavorare sempre più con tecnologie robotiche e di assistere a trasformazioni radicali della nostra società e del modo di lavorare. Sarò un ponte tra mondi: quello umano della visione e dell'intuizione, e quello algoritmico della precisione e dell'automazione, guidando questa evoluzione con la stessa passione che mi ha accompagnato per tutta la carriera.
Quale è la sfida più importante che il mondo dei dati e algoritmi ha di fronte a sé oggi?
La sfida più importante nel mondo dei dati e algoritmi oggi è la capacità di evolvere i lavori da colletti bianchi, a partire dal coding, creando nuove opportunità invece di limitarsi a mimare l'esistente con focus solo su efficienza e riduzione costi.
Il vibe coding può democratizzare la scrittura del codice come la fotografia digitale ha fatto con le immagini. Far uscire la scrittura del codice dalla "camera oscura" di noi nerd, permette a molte più persone di esprimere creatività, arricchendo l'intero panorama tecnologico e culturale.
Allargare la comunità open source di chi può produrre software crea maggiori opportunità e spessore intellettuale. Proprio la fondamentale sinergia con l’open source genera conoscenza condivisa e libera, trasformando la programmazione da disciplina tecnica riservata a pochi a strumento accessibile a molti, con potenziale per innovazioni che oggi non possiamo nemmeno immaginare.
Segnalaci il progetto o la risorsa nel mondo dei dati di cui non potresti fare a meno …
GitHub rappresenta per me la risorsa essenziale nel mondo dei dati di cui non potrei fare a meno. Il codice è una delle forme meglio strutturate di dati dinamici e di comportamento, un linguaggio che descrive non solo stati ma processi e relazioni.
GitHub va oltre il semplice repository: è un ecosistema vivente dove il codice evolve attraverso contributi collettivi e individuali. Per il mio lavoro, GitHub è fondamentale per tracciare l'evoluzione di progetti, analizzare pattern di cambiamento e integrare soluzioni innovative.
Ogni commit racconta una storia, ogni pull request rappresenta un dialogo. L'interazione tra sviluppatori crea metadati preziosi che, analizzati con strumenti AI, rivelano insight sulla qualità del codice e sulle dinamiche collaborative, elementi cruciali per il vibe coding moderno.
👃Investimenti in ambito dati e algoritmi. Addio Venture Capital (tradizionale)? Il futuro secondo Henry Shi è seed-strapped
“Benvenuti nell’era del seed-strapping.”
È così che la pensa Henry Shi, cofondatore della scale-up di successo Super.com, oggi investitore in diverse iniziative AI-native. La sua riflessione, secondo me, è davvero interessante: parte da una modellizzazione di quattro pattern di crescita possibili per le start-up in questo momento storico.

Come tutti i modelli, anche questi sono imprecisi e spesso approssimativi, ma restano strumenti molto utili per discutere e riflettere su scenari futuri.
Accanto ai più tradizionali modelli storici – come Venture Capital e Boot-strapping –
Nel Boot-scaling, come scrive lui stesso nell’articolo che ti consiglio di leggere:
“... ci si autofinanzia fino a quando non si dimostra una trazione significativa, quindi si ricorre a un massiccio giro di finanziamenti (spesso da parte di private equity).”
Mentre nel Seed-strapping:
“... Raccogliete un modesto seed round ($100K-$1M) da investitori che capiscono che i fondatori più intelligenti vogliono il controllo e la proprietà. Vi concentrate sui ricavi e sulla redditività fin dal primo giorno. Non vi interessano le metriche che impressionano i VC. La crescita dei ricavi è realizzata senza ulteriori diluizioni. Questo vi permette di concentrarvi al 100% sulla vostra attività senza preoccuparvi di esaurire i fondi o di inseguire i VC.”
Personalmente, credo che il seed-strapping sia uno dei pattern più interessanti e ad alto impatto per il futuro. Le argomentazioni puntuali di Shi nell’articolo mi trovano pienamente d’accordo — impatto dell’intelligenza artificiale incluso 🤖
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Delegare agli umani, agli algoritmi… o a entrambi?
Periodicamente cerco di rivedere il modo in cui organizzo il mio lavoro, sia per attività personali sia per quelle che coinvolgono i team con cui collaboro. Diventando diversamente giovane 😉 e lavorando con un numero crescente di team, questa attività diventa sempre più complessa. Per questo, almeno una volta all’anno, mi prendo del tempo per ripassare o studiare le tecniche che altri usano per essere più efficaci.
Il concetto di delega è, secondo me, uno dei più complessi da ottimizzare. Il tutto si è complicato ulteriormente con l’avvento delle intelligenze artificiali generaliste, che ampliano lo spazio disponibile per la delega – o perlomeno per il supporto – ma introducono anche dei trade-off tra vantaggi e svantaggi non sempre noti a priori. Come dice Ethan Mollick, "siamo sempre più nella frontiera frastagliata dell’AI."
Il suggerimento di lettura di oggi arriva da un contributo molto bello scritto da
, che parla proprio della difficoltà di delegare e ci consente di “ripassare” la matrice di Eisenhower, arricchita da alcuni saggi consigli (in viola e in rosso!) nell’immagine che trovi qui sotto e che ho imparato ad apprezzare con l’età.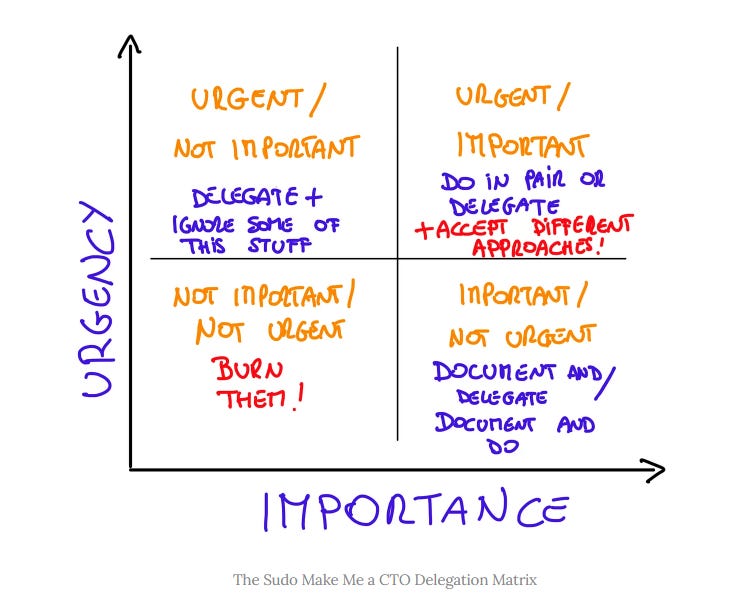
L’articolo è davvero utile e ricco di spunti interessanti, a partire dal consiglio che “per delegare in modo efficace, bisogna accettare che le cose non saranno sempre fatte secondo i propri gusti.”
A tutto quello scritto nell’articolo, mi sento di aggiungere una domanda che ho imparato a farmi negli ultimi tre anni per essere più efficace:
👉 “Posso delegare o farmi efficacemente aiutare da un’intelligenza artificiale per aumentare la qualità o essere più veloce in un’attività che devo fare?”
Questa domanda mi ha portato a creare più di 20 GPTs personalizzati per attività ricorrenti, e a usare – a seconda dei task – cinque AI generaliste e altrettanti software SaaS per compiti specifici: creare presentazioni, grafici o scrivere codice.
Il bilancio sull’efficienza è sicuramente positivo.
Mi rimane però un dubbio: aumentare l’efficienza su tutto porta davvero a essere più efficaci su ciò che conta davvero? E su questo sto cercando di lavorare… senza intelligenze artificiali 🙂.
Ah, dimenticavo… Se ti è piaciuto l’articolo di Sergio Visinoni sulla delega e vuoi fare un ripasso sui principi eterni 🙂 del time management, questo altro articolo sempre di Visinoni merita assolutamente la tua attenzione!
👀 Data Science. Machine Learning in versione illustrata: quando i concetti ti parlano con le immagini
Era stato, di gran lunga, l’approfondimento più apprezzato nella newsletter 46 a inizio 2023, e devo dire che è ancora oggi uno dei migliori esempi a livello mondiale di come, attraverso illustrazioni chiare e concise, si riescano a spiegare o a ripassare alcuni dei concetti chiave del mondo della data science e del machine learning. Sto parlando del progetto “The Illustrated Machine Learning Website”.
Mi è capitato più volte, in questi ultimi tre anni, di usarlo per rivedere alcuni concetti o per spiegarli anche a un’audience non tecnica o comunque alle prime armi. Il tutto è diviso in tre aree principali. La prima è dedicata al machine learning e descrive – usando, come le altre parti del sito, Excalidraw come strumento grafico – tutti i concetti base: le categorizzazioni, i tipi di campionamento, i bias, i modelli supervisionati e non supervisionati e, infine, tutte le sofisticazioni dell’“hyper-parameters tuning”. La seconda parte è dedicata al machine learning engineering e alla fase di setup del team in un progetto di dati e algoritmi. La terza parte, fatta egualmente bene, è tutta dedicata alla computer vision.
Ve ne è anche una quarta – per ora più limitata – dedicata al deep learning.
Il progetto, un altro esempio di ottima Open Science, è stato realizzato da un team di giovani italiani: Francesco Di Salvo, Simone Raponi e Matteo Bernabito, che hanno lavorato anche su diversi altri progetti interessanti (ti consiglio di curiosare tramite i link presenti nell’area credits sui loro profili GitHub e i loro siti web).
Per finire, ti consiglio di dare anche un’occhiata alla pagina references del sito: potresti proseguire a imparare e ad approfondire passando dalla modalità visuale a quella testuale, scoprendo risorse di grande qualità.
👅Etica & regolamentazione & impatto sulla società. Come cambia l’apprendimento con l’AI (secondo Potkalitsky, Jaokar, Roversi e una prof molto speciale)
In aprile e maggio, periodo dell’anno in cui tengo il corso in Cattolica su come si prendono – e si dovrebbero prendere – le decisioni in azienda anche grazie all’uso dei dati e dell’AI, mi sento ancora più vicino alle profonde trasformazioni che stanno attraversando i sistemi educativi, soprattutto dopo l'esplosione cambriana dei nuovi strumenti di intelligenza artificiale generativa.
Per questo, dopo averti parlato le scorse settimane di quello che dovrebbe essere l’obiettivo presente e futuro della scuola – abilitare il pensiero generativo – ti suggerisco alcune letture più concrete su come il sistema educativo sta cambiando… o meglio, su come sta cercando di cambiare.
Per cominciare, ti consiglio questo articolo di Nick Potkalitsky che propone un sistema di valutazione dei vari tool basati su intelligenze artificiali pensati per supportare l’apprendimento degli studenti. Il sistema si articola su quattro assi di valutazione: la capacità dello strumento di aiutare gli studenti a connettere le idee (Knowledge Integration), di stimolare il pensiero (Active Processing), di favorire la riflessione su ciò che stanno studiando (Metacognitive Support) e, infine, lo stimolo a creare ed esplorare nuovi contenuti (Generative Features). Nell’articolo
fornisce anche esempi pratici di utilizzo di questo sistema di valutazione con tool che ha sperimentato nelle sue attività.Se invece sei curioso di scoprire come una persona con neurodiversità sta esplorando metodologie di apprendimento con knowledge graph e intelligenze artificiali per persone con neurodiversità, ti consiglio di partire da questo post di Ajit Jaokar.
E se vuoi muoverti verso futuri preferibili, passando da una scuola (o qualsiasi forma di apprendimento) in cui si “studia” a una che ti prepara alla vita, non puoi perderti questo post di
e . Raccontano questo passaggio attraverso una serie di spostamenti: dalle risposte alle domande, dai programmi ai problemi, dalle materie all’immaginazione, da una sola intelligenza a tutte le intelligenze, dalla classe alla comunità, dall’isolamento all’apertura, dalla tecnofobia alla tecno-alleanza, da “cosa studi” a “chi vuoi diventare”…Ma il cammino è lungo. E se sei curioso di leggere le riflessioni sul campo di un’insegnante che lavora in un liceo statale italiano e sta sperimentando su sé stessa, con le colleghe e con le classi, puoi farlo leggendo le riflessioni che scrive
(ndr: che è anche mia moglie) sul suo Substack.Buone letture! 😊
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!