sono Stefano Gatti e questo è il centosettantunesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del centosettantunesimo numero:
👃Investimenti in ambito dati e algoritmi. Raffaele Mauro: spazio, neurotecnologie, il futuro dei dati e tanto altro …
Presentati Raffaele Mauro. Sono appassionato di finanza, tecnologia, geopolitica e neuroscienze. Attualmente sono General Partner in Primo Space, un fondo di venture capital specializzato nel deep tech e nella space economy. In passato sono stato Managing Director di Endeavor Italia, un’organizzazione che supporta le imprese ad alta crescita su scala internazionale, precedentemente mi sono occupato di investimenti high-tech e sviluppo di iniziative per l’imprenditorialità innovativa presso il gruppo Intesa Sanpaolo e in fondi di venture capital come United Ventures e P101. Sono membro della Kauffman Society of Fellows e dei Karman Fellows, ho ottenuto l’MPA ad Harvard con specializzazione in finanza internazionale, il Ph.D. in Bocconi ed il GSP presso la Singularity University nel campus NASA Ames. Ho fatto parte dei Junior Fellow dell’Aspen Institute, sono stato membro degli Young Leaders presso lo US-Italy Council, del gruppo “Young European Leaders – 40under40” e dei Future Leaders dell’ISPI. Faccio parte attualmente parte di quattro consigli di amministrazione, sono stato angel investor in società come Serenis Health, ho scritto in passato per Harvard Business Review – Italia, Limes, Aspenia, ENEA Magazine e Pandora Rivista e sono stato autore dei libri “Hacking Finance”, “Quantum Computing” e “I cancelli del cielo: Economia e politica della grande corsa allo spazio”.
Credo che il mio ruolo sarà quello di creare impatto per le persone facendo leva su una combinazione di creatività, empatia e tecnologia. Il mio cappello professionale attuale è quello di investitore, condizione che fornisce un buon livello di esposizione a persone interessanti, innovazioni e mercati di frontiera. Mi piace trovarmi in contesti dove sia possibile costruire un arricchimento umano e culturale reciproco. Inoltre, nella mia scala di valori, la ricerca della conoscenza scientifica ha un posto elevatissimo e credo faccia parte di ciò che conta veramente, profondamente, nella storia umana e nel lungo termine. Tuttavia tra dieci anni, viste le onde di trasformazione radicale che stiamo vivendo, tutto può accadere. Mi sento curioso e aperto rispetto alle opportunità e alle sfide del futuro. In questo momento sono profondamente affascinato e sto studiando estesamente tutto ciò che riguarda neurotecnologie, neuroscienze, psicotecnologie, nuovi tipi di terapie e modelli di servizio, applicazione dell’intelligenza artificiale in ambito biomedico e psicofarmacologico.
Quale è la sfida più importante che il mondo dei dati e algoritmi ha di fronte a sé oggi?
Si parla spesso e giustamente dei vincoli fisici e informazionali come l’approvvigionamento energetico dei data center, la capacità computazionale e la disponibilità di dataset per il training degli algoritmi. Se pensiamo al contesto Europeo, un vincolo essenziale è la creazione, l’attrazione e la valorizzazione del talento. E’ necessario sia offrire maggiori opportunità alle nuove classi di neolaureati, dottorandi, post doc prodotti dal sistema attuale, sia attrarre persone dall’estero. Nella storia delle società e delle civiltà umane la prosperità è sempre stata generata tramite un'elevata combinazione di tolleranza, attrazione del talento e apertura nei confronti dell’innovazione tecnologica. Oggi l’Europa vive un’opportunità storica dato che negli Stati Uniti, almeno nel breve termine, sono state imposte politiche folli e autolesioniste a riguardo. Se siamo intelligenti e lungimiranti, gli equivalenti attuali di Einstein, Fermi, von Neumann, Teller potrebbero potenzialmente fare il percorso geografico inverso. E' difficile ma qualche passo in questa direzione si può fare. Speriamo !
Segnalaci il progetto o la risorsa nel mondo dei dati di cui non potresti fare a meno …
Non ho una singola risorsa da segnarle, tuttavia posso raccontare strumenti con cui sto giocando in questi giorni: ad esempio Pinal, un tool che permette di progettare nuove proteine che possano rispondere a esigenze specifiche, ad esempio in ambito biomedico. Il sistema è addestrato su 1,7 miliardi di coppie proteina-testo e consente la progettazione proteica partendo dal linguaggio naturale, qui un breve paper a riguardo. A differenza dei metodi tradizionali, Pinal genera prima una struttura 3D basata su istruzioni testuali (ad esempio "proteina che neutralizza tossine nell'ambito X nel modo Y") e poi progetta la sequenza amminoacidica ottimale, combinando la struttura creata con il contesto linguistico iniziale. Si tratta ancora di strumenti che hanno molti limiti ma la direzione in cui puntano è interessantissima e credo che l’impatto sarà molto elevato.
Un secondo esempio, con cui però non posso sperimentare direttamente, è quello di società come Mindstate Design Labs. L’azienda si dedica allo studio di varianti molecolari di psichedelici tradizionali, un ambito di grande attualità che alimenta una nuova fase di ricerca per il trattamento di patologie come depressione e disturbo da stress post-traumatico, procedendo grazie al supporto di modelli generativi capaci di prevedere gli effetti cognitivi e psicotropi delle nuove molecole. In questo contesto, la startup ha adottato approcci originali in parte basati sulla data science, analizzando la “storia naturale” delle esperienze soggettive e utilizzando sistemi di analisi del linguaggio applicati a circa 70.000 trip report, ossia resoconti delle esperienze vissute con queste sostanze, reperiti su piattaforme come Erowid e Reddit. Il tutto è fatto con l’intento di trovare potenziali collegamenti tra le descrizioni degli effetti e le strutture molecolari note. Anche in questo caso, oggi si può fare leva sulla miniera di informazioni raccolte nel passato grazie a nuovi metodi e approcci di tipo ibrido e interdisciplinare.
🖐️Tecnologia (data engineering). Deep-ML: allenarsi con le sfide giuste, nel modo giusto
In un mondo dinamico come quello del machine learning e, più in generale, dell’intelligenza artificiale è facile perdersi tra video tutorial, corsi online e librerie che cambiano ogni sei mesi. Inoltre, soprattutto per chi è alle prime armi o non ha mai scritto codice specifico per il mondo dei dati e dell’AI, non è così immediato capire le basi matematiche e come queste si traducano in codice ottimizzato. Avere delle buone basi è un grande vantaggio, anche quando si usano strumenti low-code o no-code. Anzi, diventa uno strumento chiave per andare più veloci, sfruttare meglio queste tecnologie e comprendere eventuali errori generati dagli strumenti stessi, intelligenze artificiali incluse.
È per questo che oggi voglio segnalarti una piattaforma interessante se vuoi imparare (o anche ripassare) queste basi attraverso sfide mirate e un pizzico di gamification. Deep-ML funziona un po’ come LeetCode, di cui ti ho già parlato, ma al posto di esercizi di programmazione generici, propone attività focalizzate su ciò che davvero conta per chi lavora con i dati: algebra lineare, regressione, reti neurali, computer vision. Ogni sfida è curata da ricercatori e ingegneri del settore, e riflette problemi realistici che potresti incontrare in un laboratorio R&D, in un hackathon o durante un colloquio tecnico. La piattaforma è in gran parte gratuita e accessibile a tutti. Esiste anche una versione a pagamento con funzionalità aggiuntive, come l’interazione con una AI generativa, ma non sono elementi fondamentali. Le metriche di progresso, i grafici, i badge e le leaderboard aggiungono un tocco di sana competizione e aiutano a mantenere alta la motivazione nel tempo 💪 Ma il vero cuore del progetto è la community. Deep-ML è infatti anche un repository GitHub dove chiunque può contribuire con nuove sfide, migliorare quelle già presenti o proporre correzioni. È un laboratorio aperto, dove si costruisce insieme una conoscenza operativa. In un’epoca in cui l’accesso alla conoscenza è vasto ma dispersivo, progetti come Deep-ML aiutano a concentrarsi sulle competenze che contano davvero, in un formato aperto, concreto e ben strutturato.
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Organizzazioni sotto stress? La bussola di Schein e le dritte di Mollick e Ng
Stiamo vivendo un momento di cambiamento molto forte a livello organizzativo all’interno delle nostre aziende. E l’AI generativa è sicuramente uno, forse sta per diventare il principale, motore di questo cambiamento. Per questo credo sia interessante recuperare quella che, secondo me, è la miglior definizione di cultura organizzativa: quella di Edgar Schein, uno dei massimi studiosi in materia. Schein definisce la cultura come:
"Un modello di presupposti condivisi che un gruppo ha appreso mentre risolveva i problemi di adattamento esterno e di integrazione interna, e che ha funzionato abbastanza bene da essere considerato valido e da essere insegnato ai nuovi membri come il modo corretto di percepire, pensare e sentire rispetto a quei problemi."
È una definizione molto concreta e pratica, che, come dettaglierà in seguito lo stesso Schein, si basa su tre livelli:
Artefatti Sono gli elementi visibili e tangibili della cultura, ma spesso difficili da interpretare. Includono, ad esempio, l’ambiente fisico e il layout degli uffici, l’abbigliamento, le tecnologie usate, i riti, le cerimonie, il linguaggio e i comportamenti osservabili. Sono ciò che si vede, ma non sempre si comprende senza conoscere il contesto. Per esperienza personale, sono aspetti spesso sottovalutati ma fondamentali per come la cultura è percepita, soprattutto da chi arriva da fuori o sta decidendo se unirsi o meno al team.
Valori dichiarati o espliciti Sono i principi, le strategie e gli obiettivi dichiarati dall’organizzazione, spesso presenti in mission, vision, codici etici e regolamenti. Rappresentano ciò che l’organizzazione dice di credere, anche se non sempre questi valori si traducono in comportamenti reali. Proprio perché spesso non sono vissuti in modo coerente in ogni momento e da tutti, sono anche gli aspetti più rischiosi su cui esporsi. E, per certi versi, anche i più sopravvalutati.
Assunti di base Sono le credenze profonde, inconsce e date per scontate che guidano i comportamenti delle persone. Ad esempio: idee implicite su cosa significhi “successo”, convinzioni sulla natura umana (fiducia o sfiducia), modalità implicite su come si prendono decisioni (con o senza dati… per stare nel nostro ambito). Sono invisibili ma potentissimi, e spesso nemmeno i membri dell’organizzazione ne sono consapevoli. È la componente più complessa e lenta da modificare, ma probabilmente anche la più importante.
Per approfondire questi temi (e quelli della leadership) in questo momento storico, ti consiglio tre punti di vista per molti versi complementari:
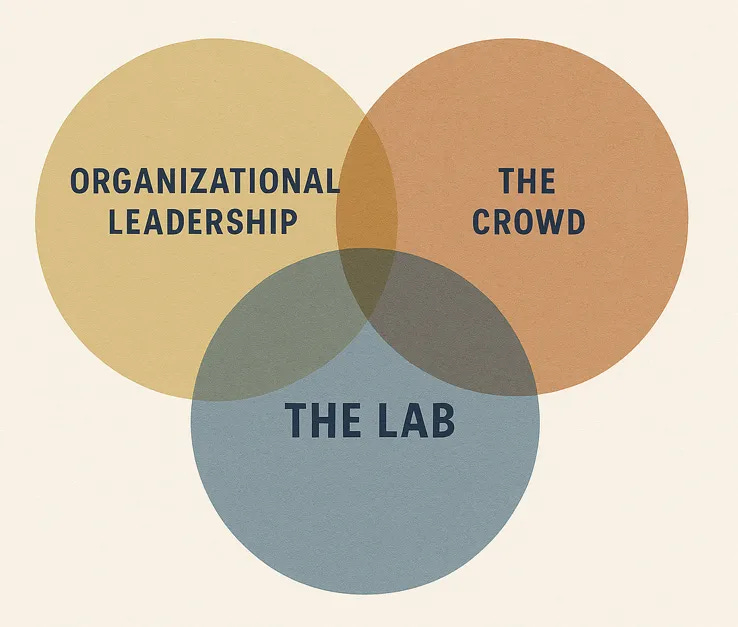
📌 Un articolo di Ethan Mollick che ha tutte le carte in regola per diventare iconico e invecchiare bene: “Making AI Work: Leadership, Lab, and Crowd”. Il titolo è già molto esplicativo, e l’articolo è ben sintetizzato da un’immagine… ma mi raccomando: leggilo tutto, non fartelo sintetizzare da Claude 😉
📌 Questo contributo di Andrew Ng, che si concentra sull’importanza, anche per le grandi aziende, di muoversi in fretta grazie all’AI e alla sua implementazione strategica.
📌 Un post di Jan Bosch che approfondisce il tema della cultura organizzativa, riprende e smonta la definizione di Schein da cui eravamo partiti, offrendo un punto di vista per certi versi molto “radicale”.
✅ Memo
Per chi si fosse perso la news, è uscito Intelligenza Artificiale in 4D! Un libro pratico sull'AI, scritto a quattro mani da me e
👀 Data Science. A volte le previsioni non bastano: esplorare le serie temporali con STUMPY
Le serie temporali sono un tipo di dato molto presente in azienda e possono aiutare tantissimo le strategie e le decisioni che si prendono. Ma sono anche dati molto difficili da usare, perché per loro natura fotografano un processo (o un suo attributo) in un mondo (esterno) che è cambiato e sta cambiando. Senza fare dissertazioni filosofiche sul concetto di tempo, per quelle ti rimando al grande Carlo Rovelli, devo dire che lavorare con questo tipo di dataset mi ha sempre dato grandi grattacapi. Anche per via delle aspettative che tutti gli stakeholder dei progetti su cui ho lavorato, CEO compresi, hanno avuto sui risultati della data science applicata a questi dati. Sì, perché quando si parla di time series, il primo istinto è spesso “fare previsioni”. È il regno di Prophet, ARIMA e altre librerie super collaudate. Tutti strumenti focalizzati su capire cosa succederà domani, dato quello che è successo oggi. Ma cosa succede se vogliamo rispondere a domande diverse, tipo: "Quando si è verificato un comportamento simile a questo?", "Ci sono pattern ripetitivi o anomalie nel tempo?", "Come faccio a segmentare una serie senza ipotesi di stagionalità?".
Qui entra in gioco (anche) un altro tipo di approccio, ben rappresentato dall’approfondimento che ti suggerisco oggi: STUMPY, una libreria Python pensata per l'analisi esplorativa delle serie temporali tramite il concetto di matrix profile, una struttura dati che ti dice, per ogni finestra della serie, quanto somiglia al resto della serie.
Con STUMPY non fai previsioni, ma puoi:
Scoprire pattern ricorrenti
Trovare anomalie locali o globali
Segmentare automaticamente eventi simili (es. cicli, attività, comportamenti)
Un esempio pratico, preso dal mondo della medicina, potrebbe essere questo: hai una serie temporale con i battiti cardiaci registrati minuto per minuto. Con Prophet potresti stimare il battito previsto alle 10:00 di domani. Con STUMPY, invece, puoi dire: “Questo comportamento anomalo si è verificato anche alle 02:17 e alle 14:23” oppure “Tra le 03:00 e le 04:00 è successo qualcosa di mai visto prima”.
Il tutto senza modelli. Senza assunzioni di stagionalità. Solo pura similarità. In sintesi: forecasting ≠ pattern discovery. STUMPY non rimpiazza Prophet, lo completa. Serve quando vuoi esplorare, non prevedere. E se ti stai chiedendo se è scalabile: sì, STUMPY usa Numba per compilare il codice numerico in linguaggio macchina e lavora tranquillamente su serie da milioni di punti. E se sei curioso di approfondire, dal punto di vista tecnico e matematico, l’algoritmo di matrix profile, ti consiglio vivamente questo tutorial (e la sua prosecuzione) del Department of Computer Science and Engineering (CSE) dell'University of California, Riverside, che è stato tra gli artefici di questo tipo di algoritmo da cui è nata proprio la libreria STUMPY.
👅Etica & regolamentazione & impatto sulla società. AI e umani: non siamo poi così diversi
Era stato l’approfondimento più apprezzato di febbraio 2023, più di 120 numeri fa. E la nostra percezione delle intelligenze artificiali generative era, mediamente, molto diversa da quella che abbiamo oggi. All’epoca andava per la maggiore considerarli pappagalli stocastici e sottovalutarne il valore e il potenziale di miglioramento. Gli LLM con sistemi di reasoning (chain of thoughts, per intenderci) erano ancora allo stadio di pura ricerca.
, che mi e ci aveva aiutato a capire il Web, le sue potenzialità e i suoi pericoli ben prima che ce ne accorgessimo, scriveva, appunto nel febbraio 2023, di quanto fosse necessario lavorare con queste intelligenze, anche solo per rendersi conto che non erano poi così diverse da noi. Ma Mafe andava oltre: intuiva la loro diversità e, per certi versi, la complementarietà rispetto ai motori di ricerca. E sottolineava come, in fondo, “anche noi umani generiamo testi a partire dalla probabilità di distribuzione di parole o sequenze di parole, applicando regole grammaticali, sintattiche, stilistiche, semantiche”. Gradualmente, lo abbiamo capito (quasi) tutti. Mafe, che è anche una persona che stimo molto e che mi ha aiutato a progettare questa newsletter (almeno nelle sue fasi meno logorroiche 😅), ha una rara capacità: capire la tecnologia non per se stessa, ma inserita nel mondo, indicandoci futuri preferibili verso cui provare a indirizzarla e a indirizzarci.
Per questo, oltre a consigliarti questa piacevole lettura (o rilettura) che è invecchiata benissimo, ti suggerisco anche di ascoltare questo recente suo intervento con
, dove racconta la sua visione della co-evoluzione con queste intelligenze. Una visione che, ovviamente, si è affinata nel tempo.
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!
Se ti è piaciuto questo numero di LaCulturaDelDato e non sei ancora iscritto fallo subito!





Miao 😊