

LaCulturaDelDato #172
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il centosettanduesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del centosettanduesimo numero:
👃Investimenti in ambito dati e algoritmi. Milano spinge sull’innovazione: crescita, cluster e capitali secondo Dealroom
Ci sono due segnali che emergono in maniera molto chiara dall’approfondimento che ti consiglio oggi, realizzato da Dealroom, e che ha al centro l’ecosistema degli investimenti di Milano.
Il primo è la notevole crescita del valore dell’ecosistema, misurato come enterprise value combinato negli ultimi 10 anni.
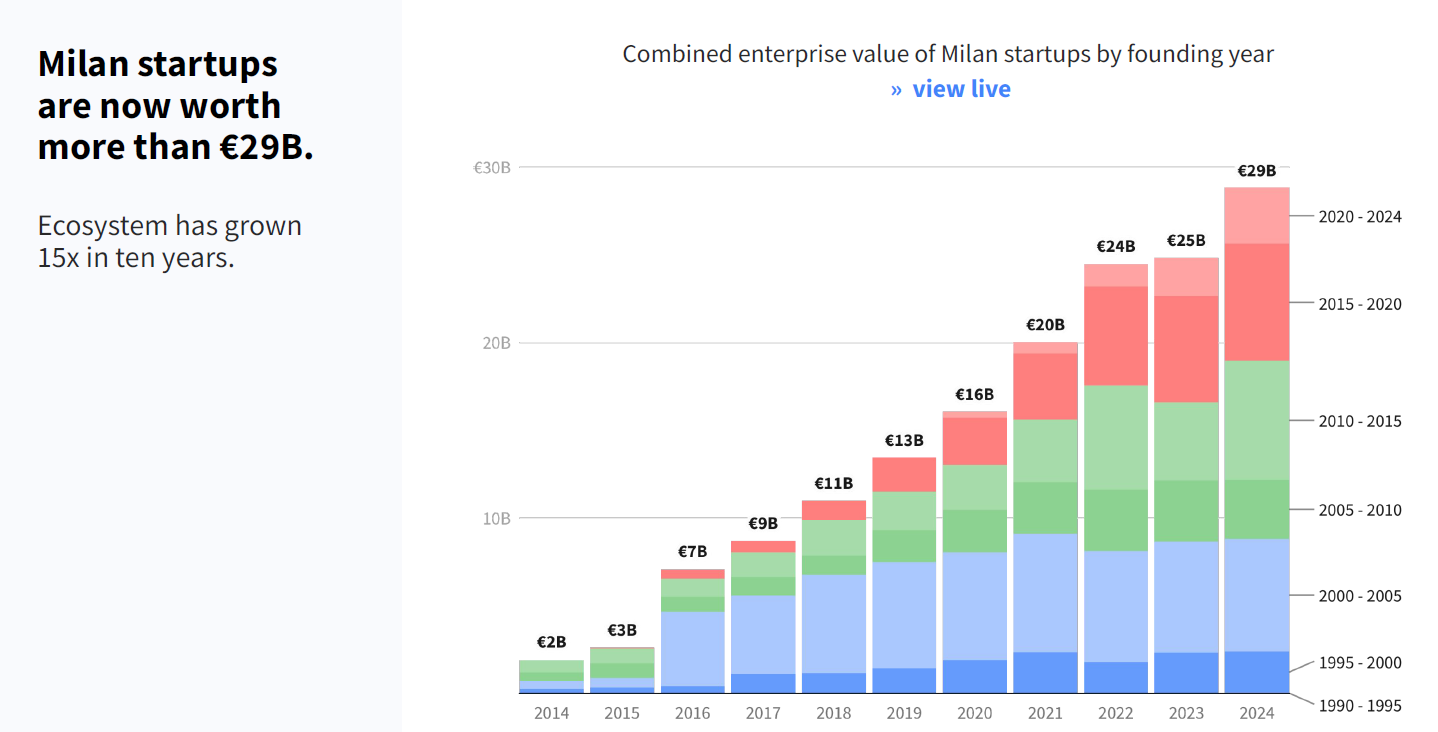
Il secondo è che l’ecosistema milanese, da solo, vale quasi il 50% dell’intero ecosistema italiano.

Ma ci sono tante altre cose interessanti che emergono dalle 38 pagine dello studio e che secondo me meritano attenzione:
i cluster molto forti di fintech e life science che si stanno formando a Milano.
la crescita e il consolidamento degli investitori, anche stranieri.
il funnel sempre più ricco di scale-up e il relativo network di founder “vincenti” che si sta costruendo.
Se poi vuoi andare ancora più nel dettaglio, ti consiglio di dare un’occhiata anche al sito Yes Milano Innovation Map, realizzato da Milano&Partners, l'agenzia ufficiale per la promozione della città, creata dal Comune di Milano e dalla Camera di Commercio di Milano Monza Brianza Lodi.
La realizzazione tecnica della piattaforma è stata curata in collaborazione con Dealroom.co stessa. La YesMilano Innovation Map ti permette di esplorare l’ecosistema dell’innovazione milanese, offrendo dati aggiornati su startup, investitori, round di finanziamento e altri attori chiave. L’obiettivo è rendere Milano e il suo hinterland sempre più attrattivi per investitori esteri e talenti internazionali 💡
🖐️Tecnologia (data engineering). Debito tecnico & AI: servono più architetti e meno sviluppatori di codice?
In un mondo dello sviluppo software in cui il codice è sempre più scritto da intelligenze artificiali, e i dati che arrivano da fonti diverse confermano questa tendenza, credo che l’approfondimento che avevi apprezzato di più nel numero 51 della newsletter sia diventato ancora più centrale.
Refactoring.Guru è un portale didattico che raccoglie articoli, illustrazioni, esempi di codice, un corso interattivo (“Dive Into Refactoring”) e un e-book (“Dive Into Design Patterns”). L’obiettivo è spiegare refactoring, design pattern, principi SOLID e buone pratiche con un linguaggio accessibile e tantissimi esempi multi-linguaggio (da C# a Rust).
Come scrivevo tre anni fa: “Anche il mondo dei dati e degli algoritmi non è affatto immune dal problema del debito tecnico, termine introdotto nel 1992 da Ward Cunningham, programmatore e coautore del Manifesto per lo sviluppo agile del software. Con debito tecnico, cito la voce italiana di Wikipedia, “si intende un insieme di possibili complicazioni che subentrano in un progetto, tipicamente di sviluppo software, qualora non venissero adottate adeguate azioni volte a mantenerne bassa la complessità.” E questo succede, nei progetti, per i motivi più svariati: dalla necessità di andare rapidamente sul mercato, alla mancanza di conoscenza di chi sviluppa, o semplicemente alla carenza di collaborazione all’interno del team.”
Gli agenti AI che scrivono codice (ma anche gran parte degli strumenti low-code e no-code) tendono a produrre codice funzionante, sì, ma spesso con problemi strutturali, come:
Code smells nascosti: soluzioni funzionanti ma con duplicazioni, accoppiamenti stretti o logica dispersa;
Mancanza di visione architetturale: codice generato “localmente” senza considerare l’architettura complessiva;
Pattern inconsistenti: ogni generazione può seguire approcci diversi, creando incoerenza nel codebase.
In quest’ottica, il refactoring diventa un fattore sempre più strategico: serve a trasformare il “codice grezzo ma funzionante” in codice mantenibile e scalabile, e migliora l’integrazione con i pattern architetturali presenti in azienda.
Tutto questo in un contesto in cui lo sviluppatore scrive sempre meno codice da zero, ma assume sempre più il ruolo di architetto, reviewer (del codice) e, soprattutto, refactorer e quality guardian del codice scritto insieme ad altre intelligenze 🤖
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. I grafici raccontano (se sai come): due chicche da Storytelling with Data
Se devo indicarti una risorsa che, negli ultimi 10 anni, mi ha aiutato più di tutte a capire quanto sia potente la combinazione tra una buona data visualization e una presentazione efficace di una storia in qualunque contesto, allora non ho dubbi: ti parlo del sito/progetto Storytelling with Data. Nato grazie alla bravissima Cole Nussbaumer, questo progetto è cresciuto nel tempo grazie a un team e a una community super attiva.
Ho letto e cercato di “praticare” quasi tutti i libri di Nussbaumer, e non me ne sono mai pentito! Gli approfondimenti che ti consiglio oggi arrivano proprio da lì.
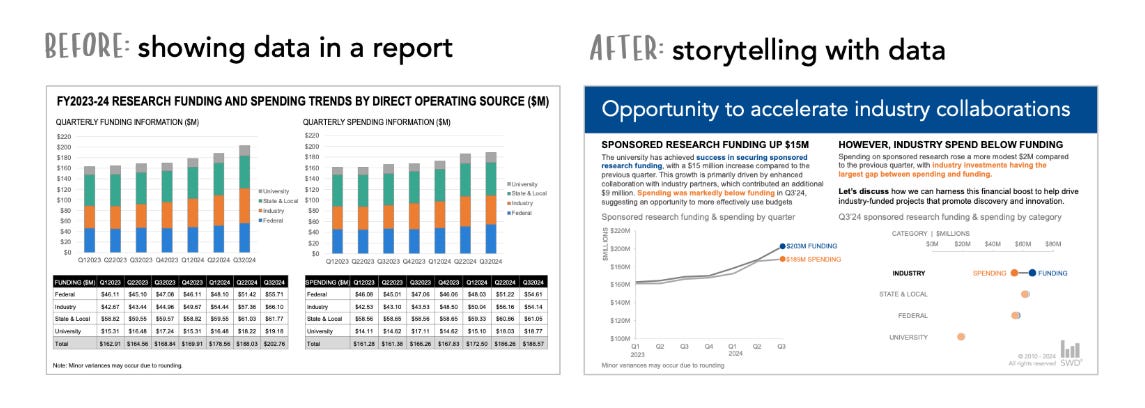
Il primo parte con una domanda che definirei quasi retorica: “Do you need a data story?”. L’articolo mostra in modo super pratico, con un esempio concreto, come trasformare un bel report in una storia che funziona per la tua audience specifica, supportando in modo efficace il processo decisionale.
Il secondo approfondimento, sempre da Storytelling with Data, fa parte di una serie di post che spiegano in maniera non convenzionale i vari tipi di grafici. Questa volta si parla del diagramma di Gantt. Confesso: è un tipo di grafico che non amo 😅. Lo trovo spesso sopravvalutato, e secondo me induce a pensare in modo troppo semplificato quando si pianificano progetti complessi. Detto ciò, resta utile in certi contesti, e il post suggerisce usi poco scontati che, devo dire, ho visto usare raramente.
👀 Data Science. Burkov colpisce ancora: un libro pratico (e senza hype) sui modelli linguistici
Andriy Burkov è un esperto canadese di intelligenza artificiale, originario dell'Ucraina, con un dottorato in AI e oltre 20 anni di esperienza in machine learning e NLP. Oltre ad aver guidato, e continuare a farlo, team di machine learning in diversi contesti aziendali, come Fujitsu, Gartner e ora l’interessante TalentNeuron, ha scelto di dedicarsi anche alla divulgazione tecnica indipendente. È diventato così un autore di riferimento per chi lavora con i dati e con l’AI.
È noto per la serie "The Hundred-Page Book", che include il bestseller "The Hundred-Page Machine Learning Book", di cui ti ho già parlato in passato, e il più recente "The Hundred-Page Language Models Book", pubblicato nel 2025, che è proprio l’oggetto del consiglio e dell’approfondimento di oggi.
Tra l’altro, Andriy Burkov era entrato nella short-list delle persone da seguire nella sezione che abbiamo scritto nell’ultimo libro che ho pubblicato con
Quest'ultimo libro offre un percorso pratico e conciso attraverso i modelli linguistici, partendo dai fondamenti fino ai Transformer moderni, con esempi in PyTorch e codice eseguibile su Google Colab. Burkov è apprezzato per la sua capacità di spiegare concetti complessi in modo chiaro e accessibile, mantenendo un approccio rigoroso e privo di hype.
E anche questa volta, non tradisce le attese.
Per renderti conto della qualità e quantità di lavoro che c’è dietro il libro, prima di acquistarlo dai un’occhiata al wiki del libro stesso, che Burkov ha lasciato aperto a tutti. Vale da solo la tua attenzione 😉
👅Etica & regolamentazione & impatto sulla società. Sette fluidi, mille dati: come il tuo corpo parla in tempo reale
I fluidi presenti nel nostro corpo hanno acquisito, nel corso dei secoli, un'importanza crescente per capire il nostro stato di salute e per monitorare l’efficacia delle cure somministrate dai medici. Questa rilevanza è cresciuta parallelamente all’evoluzione della scienza medica. Ma è solo negli ultimi 100 anni che i fluidi corporei sono diventati una fonte incredibilmente ricca di dati sulla nostra salute, soprattutto per monitorare le principali malattie e la loro evoluzione.
Negli ultimi 10 anni, però, abbiamo assistito a un’ulteriore accelerazione di questo fenomeno in due direzioni:
l’aumento delle informazioni che si possono estrarre da questi fluidi;
l’aumento della velocità con cui queste informazioni possono essere ottenute, arrivando in alcuni casi al monitoraggio in tempo reale (come per il glucosio nel sangue) e alla “decentralizzazione della misurazione” al paziente stesso.
L’approfondimento che ti consiglio oggi, utile anche per poterli sfruttare al meglio nella gestione della tua salute, parla proprio di sette tra i liquidi più importanti: sangue, feci, urina, sudore, seme, saliva e lacrime. Il Dr. Bertalan Mesko, autore di questo approfondimento, è uno dei massimi esperti e divulgatori a livello mondiale sulle innovazioni data-driven in medicina. Per ciascuno di questi fluidi, Mesko fornisce un sintetico punto della situazione sulle innovazioni già disponibili sul mercato o in fase di sviluppo come il laboratorio per l’analisi delle urine della Withings, già integrabile nel tuo water 🙂.
Avere tutti questi dati è sicuramente interessante e importante, ma anche qui vale un’equazione, non corretta dal punto di vista matematico ma molto realistica: 1+1=3. Anche in questo caso, infatti, l’integrazione e l’analisi dei dati in chiave temporale sono fondamentali.
Vivendo in una nazione dove non abbiamo ancora una decente integrazione dei dati delle analisi svolte nei vari centri medici del Servizio Sanitario Nazionale, parlare di analisi dei dati in tempo reale sembra come guardare un razzo diretto su Marte da una caverna della preistoria. E lo scrivo avendo vissuto, recentemente, in prima persona, con un mio familiare, esempi clamorosi e pericolosissimi di mala (o assente) integrazione dei dati sanitari che avrebbero potuto avere un impatto grave sulla sua vita.
Ma il mondo va comunque più veloce del nostro fascicolo sanitario regionale. Per fortuna!
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!