

LaCulturaDelDato #173
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il centosettantatresimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del centosettantatresimo numero:
🖐️Tecnologia (data engineering). Oltre l’efficienza: come Filippo Capriotti (e GiONA) usa(no) i dati per capire e migliorare le organizzazioni
Presentati
Filippo Capriotti. Alle elementari organizzavo i giochi durante la ricreazione, e forse già allora cercavo ordine nel caos. Ho studiato informatica e management per creare un algoritmo che mi liberasse dall’ossessione dell’efficienza, ma non ci sono riuscito… così ne ho fatto un lavoro. In Eni ho lavorato nell’R&D su sistemi di knowledge e innovation management, introducendo social media e crowdsourcing quando erano ancora sperimentali, con approcci pionieristici di network science. Da lì è nato l’Eni Datalab, laboratorio di data science, analytics e AI applicato alla comunicazione e alla gestione della reputazione aziendale. Dopo un’esperienza come COO in Chora Media, mi sono unito a Kopernicana dove con Alberto Gangemi e Alessandro Chessa abbiamo dato vita a GiONA, un prodotto di Organizational Network Analysis (ONA) per aiutare le aziende a leggere le dinamiche informali, valorizzare le connessioni nascoste e trasformare i dati in leva di trasformazione organizzativa.

Il mio ruolo tra 10 anni sarà ... (continua la frase come fossi GPT-10)
Tra dieci anni mi immagino a usare la comprensione dei sistemi complessi: la network science, i dati, l’AI non solo per trasformare le organizzazioni, ma per contribuire a una società più giusta. Lavorerò dove c’è bisogno di cura sistemica, aiutando comunità e istituzioni a diventare più consapevoli, inclusive e connesse con l’ecosistema esterno. Userò la tecnologia per facilitare collaborazione, fiducia e scambio tra realtà che oggi non riescono a parlarsi.
Quale è la sfida più importante che il mondo dei dati e algoritmi ha di fronte a sé oggi?
La sfida più importante oggi è usare dati e algoritmi per rafforzare la democrazia, la divergenza di pensiero e l’accesso alle risorse conoscitive. Colmare il divario che la rivoluzione digitale e il capitalismo hanno ampliato, restituendo voce e potere a chi ne è stato escluso: minoranze, comunità marginali, soggettività invisibili ai modelli dominanti. È tempo che il digitale smetta di replicare paradigmi di produzione industriale e diventi uno strumento per ascoltare meglio, includere punti di vista diversi e prendere decisioni più giuste.
Più che generare efficienza, oggi la vera posta in gioco è generare consapevolezza e proteggere la varietà cognitiva e dunque la libertà degli esseri umani.
Segnalaci il progetto o la risorsa nel mondo dei dati di cui non potresti fare a meno …
Che domande?! Ovviamente non potrei più fare a meno di GiONA! Questo perché ha colmato una mancanza storica dell’Organizational Network Analysis, che sta nella parola “organizational”. Finora l’ONA è stata una metodologia potente sul piano descrittivo, ma spesso sterile sul piano trasformativo. GiONA l’ha resa finalmente operativa, distillando dalla complessità delle reti dei set di insight azionabili, a servizio dell’Org Design. Non ti dice solo dove guardare, ma ti aiuta a capire da dove partire per cambiare davvero.
👃Investimenti in ambito dati e algoritmi. Start-up of the month Maggio 2025: Hex
L’incertezza resta la parola d’ordine, e così maggio 2025 si è chiuso con 21,8 miliardi di dollari di investimenti VC globali: -13 % sul trimestre precedente e circa -33 % anno su anno. Gli USA continuano a pesare per oltre la metà (56 %) dei capitali, mentre il mercato IPO rimane tiepido e l’M&A, 24,7 miliardi di exit annunciate, si riscalda grazie soprattutto agli acquisti fatti da Open AI (in particolare di Io e Windsurf).
Tutto questo emerge dal puntuale report riassuntivo mensile di Crunchbase dove si trovano altri segnali interessanti quali: la dominanza, negli investimenti, dell’ambito AI che guida con 5,9 miliardi di dollari, poco più di un quarto del totale, seguito da Healthcare & biotech con 5,4 miliardi.
Nel mio database osservo una fotografia leggermente più ottimistica, con una stabilità quasi chirurgica: 286 startup su 486 (59 %) classificate come Data & AI, quota pressoché identica ad aprile, e volumi economici in linea con quelli del mese precedente. La fame di modelli e piattaforme intelligenti resta quindi alta, ma senza gli eccessi visti nel 2023-24.
La start-up che ho scelto questo mese è Hex, un workspace AI-native per data science e analytics che mira a saldare il divario fra notebook, BI self-service e lavoro in team. Niente silos: SQL e Python convivono con “Hex Magic”, l’assistente generativo che suggerisce query, visualizzazioni e documentazione in tempo reale; i risultati si trasformano in app interattive condivisibili con utilizzatori non tecnici, un po’ Jupyter, un po’ Retool, ma con la cura di prodotto di Figma.
A fine maggio la società ha annunciato 70 milioni di dollari di Serie C (lead investor Avra; follow-on da a16z, Amplify, Box Group, Redpoint, Sequoia, Snowflake Ventures), portando il funding complessivo oltre i 160 milioni. Il round finanzierà l’espansione della piattaforma e del go-to-market. Tra i clienti spiccano Reddit, StubHub, HubSpot, Cisco, Figma, Anthropic, Rivian e perfino la NBA: organizzazioni che usano Hex per modellare dati, costruire dashboard dinamiche e generare insight in poche righe di codice o di prompt.
Le tre cose più interessanti del prodotto sembrano essere
Product-led growth: onboarding self-service, community forte, tantissime estensioni open-source.
AI embedded by design: l’assistente non è un layer aggiuntivo, ma l’architrave dell’esperienza utente.
Ecosistema cloud-data: integrazioni deep con Snowflake, Databricks e i principali warehouse.
Se il 2024 è stato l’anno delle mega-GPU e dei fondi monstre per i modelli fondamentali, maggio 2025 racconta un VC più sobrio che premia tool capaci di democratizzare l’AI. Hex incarna questa tendenza: trasformare complessità algoritmica in semplicità operativa.
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Come migliorare l’AI partendo (anche) dai dati (parola del MIT)
“I corsi di machine learning tradizionali insegnano tecniche per costruire modelli efficaci a partire da un dataset dato. Tuttavia, nelle applicazioni reali i dati sono spesso disordinati, e migliorare i modelli non è l’unico modo per ottenere migliori prestazioni. È possibile anche migliorare direttamente il dataset, anziché considerarlo come qualcosa di fisso.
La Data-Centric AI (DCAI) è una scienza emergente che studia le tecniche per migliorare la qualità dei dataset: spesso è il metodo più efficace per aumentare le performance nei contesti pratici del machine learning. Sebbene i bravi data scientist abbiano sempre fatto questo tipo di lavoro in modo manuale, tra tentativi, errori e intuizione, la DCAI propone un approccio sistematico e ingegneristico al miglioramento dei dati.”
Questa è la presentazione di quello che, tre anni fa, nel numero 52 di questa newsletter, è stato l’approfondimento più apprezzato e usato… e che ha aumentato, se possibile, la sua rilevanza nel presente.
Il corso erogato dal MIT Open Learning group “Introduction to data-centric AI” sembra essere il primo in assoluto dedicato alla DCAI. Il programma copre algoritmi per individuare e correggere problemi comuni nei dati usati nel machine learning, nonché per costruire dataset migliori, con un focus specifico sui compiti di apprendimento supervisionato come la classificazione. La documentazione disponibile online è davvero abbondante: dalle lezioni (questa è la mia preferita 👇) a strumenti concreti per mettere in pratica quanto insegnato.

📊 E proprio l’importanza crescente, anche nel panorama italiano, di saper gestire bene i dati e analizzarli con un approccio statistico rigoroso, emerge chiaramente da un report unico per il contesto italiano, realizzato da Datamasters. L’AI & Data Skill Report 2025 analizza, con un lavoro certosino fatto sui dati stessi (ben documentato nel report), il panorama delle professioni che ruotano attorno ai dati e all’AI. E il quadro non è affatto scontato: vale la pena leggerlo tutto.
👀 Data Science. Advent of Code: la palestra nerd che funziona tutto l’anno!
Imparare, reimparare e ripassare giocando è una delle migliori strategie da mettere in pratica, anche quando gli anni passano e i tempi della scuola sembrano un lontano ricordo. Nel mondo della programmazione, poi, capita spesso che l’evoluzione professionale porti verso ruoli più orientati al coordinamento o alla leadership, allontanandoci dalla pratica quotidiana. È un problema che ho vissuto in prima persona, e non è semplice trovare un modo efficace per colmare questo gap.
Personalmente, ho trovato le sfide "a colpi di codice" il modo più stimolante per rimettere in gioco le mie competenze. E uno degli strumenti che uso ogni anno per farlo è Advent of Code.
Advent of Code è una competizione di programmazione che si tiene ogni anno, dal 1° al 25 dicembre. Ogni giorno viene pubblicato un nuovo rompicapo da risolvere scrivendo codice. I problemi, ispirati a un racconto natalizio che si sviluppa giorno per giorno, spaziano tra algoritmi, logica e ottimizzazione. È un modo divertente e stimolante per allenare le proprie abilità, migliorare nel proprio linguaggio preferito o esplorarne di nuovi. Non ci sono premi, se non la soddisfazione personale e il confronto con una community globale super attiva. Molti partecipano individualmente, altri in gruppo, oppure lo usano come warm-up per le coding interview. Gli approfondimenti che ti consiglio oggi ti aiuteranno a capire quanto questa competizione stia diventando virale e quanto possa essere utile per tenersi allenati. Inoltre, offrono prospettive molto diverse su come utilizzarla con scopi e linguaggi anche molto eterogenei.
Nel primo contributo, Marco DelMastro, un fisico del CERN con un blog molto bello e talento e passione per la programmazione, racconta la sua esperienza con Advent of Code e quanto sia virale all’interno delle community nerd.
Nel secondo contributo, Thomas Neumann, database architect, ci mostra come tutte le sfide possano essere risolte con SQL, usando diverse tipologie di database. Un esercizio unico anche per chi vuole rispolverare un po’ di SQL, ad alti livelli di complessità.
Buone sfide! 🚀
👅Etica & regolamentazione & impatto sulla società. Personal Science: dati, esperienze e miglioramenti
“La scienza personale (ndr pessima personale traduzione di personal science) non consiste solo nel raccogliere numeri, ma nel comprendere le nostre esperienze individuali e apportare miglioramenti significativi alle nostre vite”.
È questa una buona sintesi dell’approfondimento di oggi, scritto dalla “mia neuroscienziata preferita” Anne-Laure LeCunff, che ci racconta come usare bene, su se stessi, i dati senza diventarne schiavi.
Devo confessarti che, nel corso della mia vita, mi sono sempre posizionato più nella parte sinistra del diagramma di Venn che sintetizza l’articolo, quella del quantified self, piuttosto che nella parte centrale, dove si incontrano misurazione e consapevolezza.
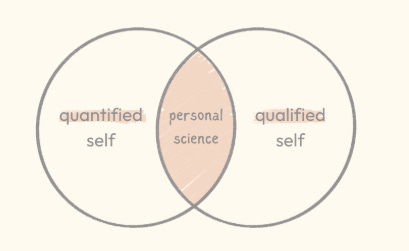
Ho, e mantengo tuttora, un piacere personale nel raccogliere dati su quasi ogni attività della mia vita: da quello che mangio, a quanto e come corro, fino a peso, massa corporea e glicemia, giusto per farti qualche esempio dai campi più disparati. E queste serie storiche, in alcuni casi, sono lunghe decenni.
Devo anche confessarti che non sempre queste serie, seppur analizzate con continuità, hanno avuto un impatto diretto e migliorativo sulla mia vita. A volte ho tratto informazioni utilissime, in altri casi poco più che rumore di fondo. Ma di sicuro, tutte mi sono state utili per via dell’effetto Hawthorne. È un fenomeno psicologico secondo cui le persone tendono a modificare (e spesso migliorare) il loro comportamento quando sanno di essere osservate. Prende il nome da una serie di studi condotti negli anni '20 e '30 presso gli stabilimenti della Western Electric nel complesso industriale Hawthorne (Illinois), dove si cercava di capire se variabili come l’illuminazione migliorassero la produttività. I ricercatori scoprirono che il semplice fatto di essere osservati e coinvolti aumentava le prestazioni dei lavoratori, indipendentemente dalle modifiche ambientali.
Nel post di Anne-Laure LeCunff non si parla specificatamente di questo effetto, ma della storia della personal science e della sua evoluzione nel tempo. Come fa sempre, la LeCunff non si perde in chiacchiere: ti suggerisce strumenti utili se vuoi cominciare (o migliorare) la tua pratica della personal science!
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!