

LaCulturaDelDato #175
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il centosettanciquesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del centosettanciquesimo numero:
👅Etica & regolamentazione & impatto sulla società. Dall’introspezione all’arte computazionale: la sfida creativa di Valentina Calore
Presentati
Valentina Calore. Sono un’artista transdisciplinare con base a San Francisco. Dopo una laurea in farmacia e un anno di ricerca pre-clinica in Italia, ho vissuto a Berlino come monitor clinico. Un sabbatico a New York City mi ha permesso di decostruire un’identità professionale che non sentivo autentica e far emergere la mia vocazione. Oggi creo arte computazionale intrecciando intelligenza artificiale, poesia, neuroscienze, e materiali tattili in opere fisiche. Con modelli di deep learning trasformo i miei versi in “firme” alfanumeriche che ne distillano l’essenza. Ne nasce un linguaggio di co-creazione fra AI e interiorità con cui esploro lo spazio fluido tra fisico e digitale, personale e collettivo.

Il mio ruolo tra 10 anni sarà ... (continua la frase come fossi GPT-10) … curare installazioni immersive nate dalla mia curiosità: pretesti di bellezza che, grazie all’AI, la stessa tecnologia che spesso ci isola, faranno incontrare persone e culture diverse, unite da affinità invisibili. Voglio essere un compasso empatico: usare la mia introversione per progettare spazi che invitano a fermarsi, riconoscersi e sentirsi parte di un tutto.
Quale è la sfida più importante che il mondo dei dati e algoritmi ha di fronte a sé oggi?
La sfida è cognitiva: evitare che l’abuso di social e AI atrofizzi la creatività umana. Se deleghiamo giudizio e immaginazione, rischiamo una società polarizzata: pochi con elevata capacità di agire che progettano i modelli, e molti che li subiscono, fra manipolazioni, bias e stasi culturale. Serve un’educazione che restituisca autonomia e pensiero critico, e insegni ad usare l’AI come partner creativo, moltiplicando valore collettivo invece che disuguaglianze.
Segnalaci il progetto o la risorsa nel mondo dei dati di cui non potresti fare a meno …
Dei modelli AI, sia open source che closed source. Non potrei fare a meno di modelli di frontiera chiusi come o3 e Midjourney, perché nonostante la loro inflessibilità rappresentano lo stato dell’arte. Non potrei fare altrettanto a meno di modelli aperti come Stable Diffusion e embeddings su Hugging Face perché danno la possibilità e flessibilità di esplorare. Questo loop esplorativo tra uomo e macchina, la quale considero un “inconscio collettivo” condiviso, è alla base di ogni mia co-creazione.
👃Investimenti in ambito dati e algoritmi. Crisi del gaming o semplice pausa? Matthew Ball e Konvoy raccontano presente, passato … e futuro!
“L’esaurimento dei motori di crescita che per oltre un decennio hanno sostenuto l’espansione di utenti, tempo di gioco e spesa… è coinciso con l’evoluzione dei comportamenti degli utenti, modelli di monetizzazione in cambiamento e crescenti effetti di “blocco”… ed è avvenuta in concomitanza con eventi macroeconomici e finanziari acuti e pandemie…”
Questa è la sintesi della sintesi di uno dei report più interessanti che fotografano molto bene lo stato e i trend dell’industria dei videogiochi, firmato da uno dei più importanti esperti e investitori del settore della tecnologia e dell’intrattenimento: Matthew Ball.
Per certi versi, l’industria dei videogame ha vissuto una dinamica di crisi e stagnazione post-Covid simile a quella dell’EdTech, anche se il trend di crescita e i margini erano stati ben più sostenuti negli ultimi vent’anni.
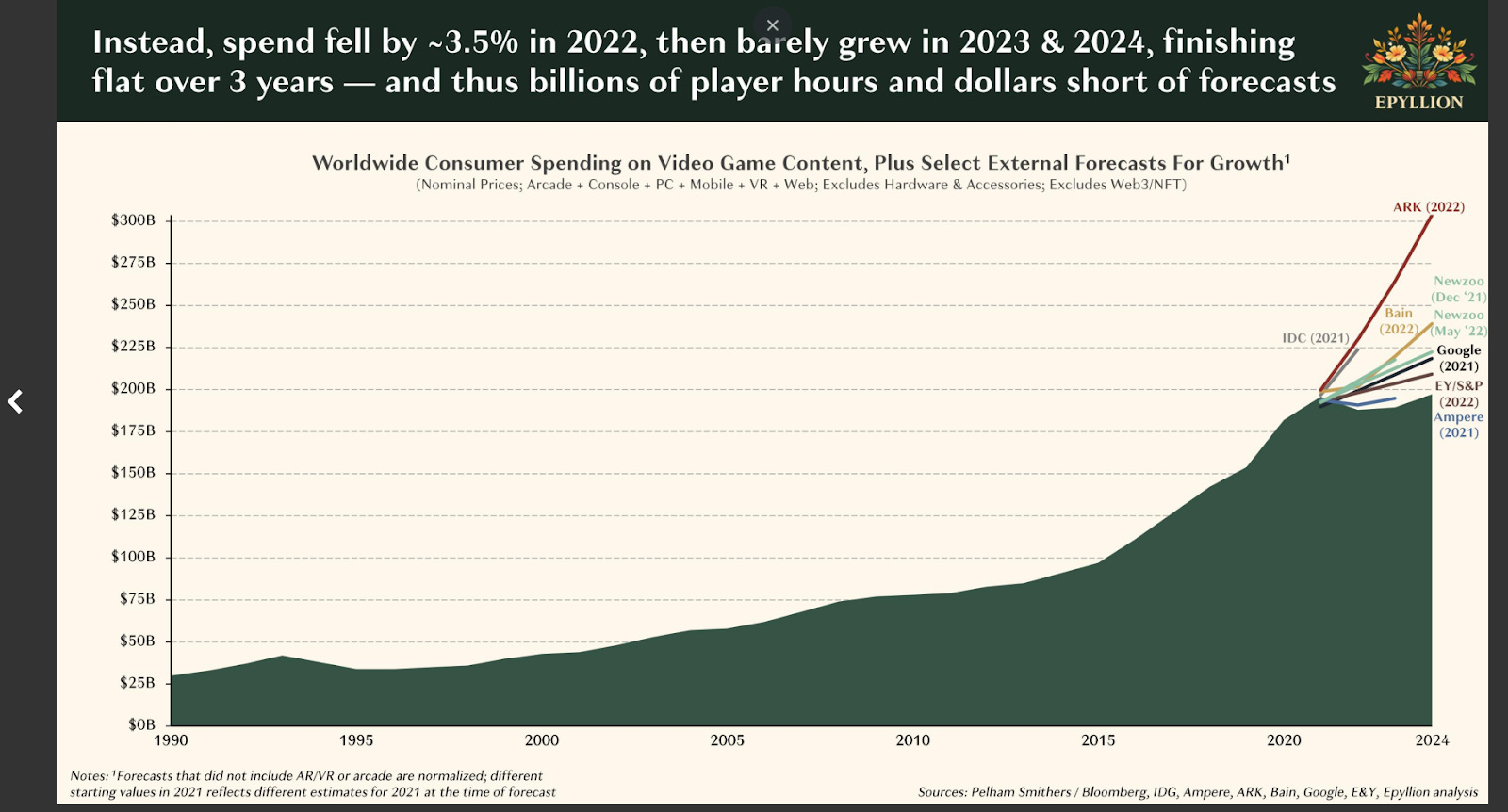
Le motivazioni di questo brusco stop, visibile anche nella forte decrescita degli investimenti VC, sono molteplici e in parte intrecciate. Si va dalla voglia di esperienze fisiche dopo la pandemia, all’erosione del tempo dedicato al gaming da parte di altri media (TikTok e YouTube in primis). Ma pesa anche la lentezza nella crescita di alcune tecnologie, come la realtà virtuale, su cui si erano riposte grandi speranze non ancora realizzate.
Sia che tu sia un appassionato di videogiochi, di dati e AI, o un investitore (e spesso questi insiemi si sovrappongono), non dovresti perderti questo report: nelle sue 231 pagine trovi un sacco di insight sulle dinamiche comportamentali dei consumatori e sui trend tecnologici che muovono il settore.
Anche perché i segnali per il 2025 sembrano positivi. E se vuoi approfondire, puoi abbinare la lettura del Gaming Industry Report 2025 del fondo di investimento specializzato Konvoy: il futuro, anche se forse non brillante come il passato, sembra comunque promettente.
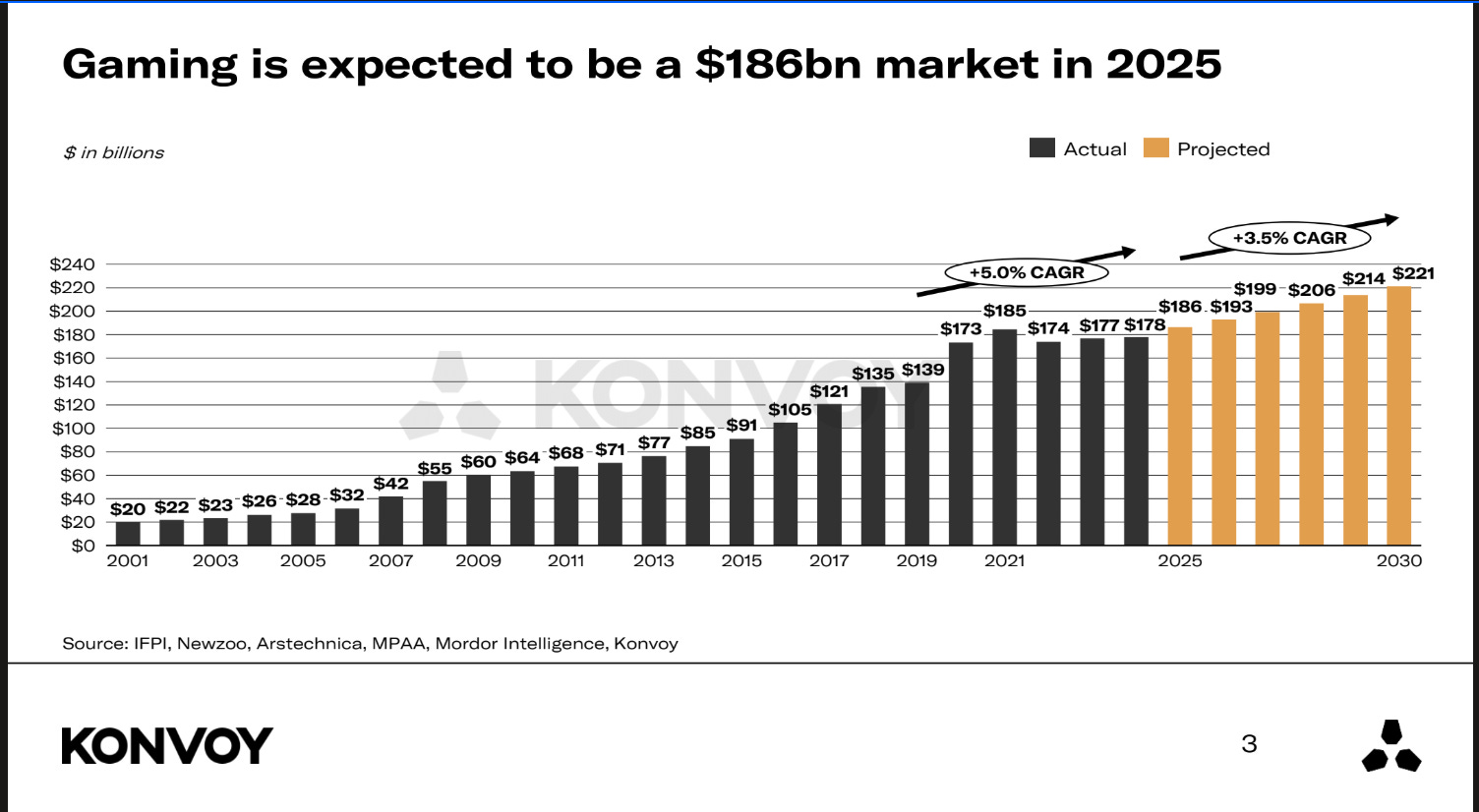
🎮 Last but not least, se sei uno sviluppatore di videogiochi, sempre da Konvoy è uscito anche il Game Developer Survey 2025: pieno di trend e dati interessanti su tecnologie e piattaforme che stanno alla base dell’industria del gaming.
🚀 Questa puntata è sponsorizzata da Athena il nuovo ecosistema EdTech per chi cerca e offre formazione
Quando abbiamo immaginato Athena, volevamo più di un semplice LMS: volevamo uno luogo d'incontro dove:
I formatori (singoli, enti, aziende) potessero progettare ed erogare corsi efficaci e di qualità, e misurare i risultati in modo preciso e continuo.
Gli studenti e le aziende potessero cercare corsi e percorsi formativi realmente utili e impattanti per il proprio business, facilmente e rapidamente.
Oggi tutto questo è realtà.
Athena integra Intelligenza Artificiale, assessment psicometrici, co-creazione, analisi di mercato, A/B testing e tracciamento delle performance per una gestione completa della formazione.
Athena è quindi una piattaforma dove ogni formatore è guidato nella progettazione di percorsi su misura, e ogni studente o azienda è guidata nella ricerca del corso più adatto alle sue esigenze.
Inizia oggi, registrati gratuitamente qui.
🖐️Tecnologia (data engineering). Dagli LLM agli agenti: viaggio verso intelligenze artificiali ibride
Una delle definizioni più complesse nell’attuale scenario dell’intelligenza artificiale generativa è quella di agente. Ogni tanto te ne parlo perché, forse senza rendercene conto, stiamo passando, usando le varie versioni di ChatGPT, da sistemi che erano quasi “solo” LLM a intelligenze artificiali ibride che, oltre a ragionare in modo ricorsivo, oggi fanno autonomamente ricerche sul web e sfruttano diverse librerie software.
A mio parere è istruttivo, quando usi per esempio il modello o3 di OpenAI, seguire i suoi ragionamenti e gli strumenti che usa per risolvere il compito che gli affidi. Negli ultimi mesi ho visto o3 evolvere verso un impiego sempre più mirato dell’OCR per capire problemi in cui grafica e topologia sono rilevanti. Un caso che ho testato personalmente è la crescita di capacità nel leggere (e risolvere) circuiti elettronici, grazie a un’analisi topologica facilitata da chiamate ripetute a librerie OCR in Python.
Stiamo quindi intravedendo, appunto, sistemi che diventano via via più indipendenti nel risolvere le attività che gli affidiamo.
Ti propongo due aspetti da approfondire, utili sia per usarli con più efficacia e meno rischi sia per intuire dove stiamo andando.
Valutazione delle performance
Specifica sempre all’agente cosa e come deve controllare quando ha eseguito il compito: la verifica esplicita è cruciale. Per andare oltre, c’è una leaderboard open-source che valuta gli agenti con una metodologia simile alle leaderboard degli LLM.Collaborazione tra agenti
Più diventano autonomi, più gli agenti sanno interagire tra loro. Un esempio promettente viene dal progetto Agent Laboratory della Johns Hopkins University, che mostra come un gruppo di agenti possa accelerare la ricerca scientifica lavorando in squadra. E anche questo articolo di Scienze in Rete racconta molto bene lo stato dell’arte del loro utilizzo nella ricerca scientifica
Se invece vuoi definizioni e descrizioni di base, questo paper di Google offre una panoramica chiara dello stato dell’arte.
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Trascrivere meglio per curare meglio: Meskò spiega perché potrebbe essere una svolta per la sanità
Il tempo che si spende nelle organizzazioni moderne per trasformare dati e informazioni, da formato orale o scritto ma non strutturato, in un formato analizzabile, integrabile con altri dati e poi valorizzabile con algoritmi prescrittivi e predittivi è ancora altissimo.
Pensiamo, per esempio, ai processi per rilevare la soddisfazione dei clienti, che partono da vocali (come telefonate) o da feedback digitali più (es. NPS) o meno (testo libero) strutturati. In questi casi, l’AI generativa sta già portando grandi miglioramenti, sia in quantità che in qualità del risultato.
C’è però un tipo di interazione e di organizzazione che potrebbe beneficiarne enormemente ma si muove ancora troppo lentamente. Anche se, a dire il vero, i segnali che arrivano dagli investimenti nelle start-up che stanno innovando su questo fronte sono forti e chiari.
Sto parlando delle trascrizioni in ambito ospedaliero e medico, in generale. Come ti ripeto spesso, qui il problema non è solo trascrivere le conversazioni tra medici e pazienti in testo non strutturato. Il vero nodo è inserire quei dati nei database sanitari (i famosi Electronic Health Records o EHRs), per poi arricchirli con altri dati, serie temporali, e algoritmi evoluti.
Se lavori in questo settore, sei un investitore oppure semplicemente curioso di capire cosa sta succedendo per migliorare l’efficienza nel mondo sanitario, ti consiglio l’articolo del “solito” Bertalan Meskò, dal titolo esplicativo Medical AI Scribes In 2025: The Top 3 Practical Benefits. Sperando che i benefici delle start-up di cui parla Meskò arrivino presto anche al nostro Servizio Sanitario Regionale… 🤞
👀 Data Science. Carlo Occhiena e la statistica che serve a tutti (non solo ai data scientist)
Era stato l’approfondimento che vi era piaciuto di più nel numero 54 della newsletter, e oggi mi va di riproporlo con ancora più “forza”. In un momento di sicuro hype sulla generative AI, ribadire che la statistica è la scienza più importante che abbiamo per fare previsioni mi sembra fondamentale!
Il contributo che Carlo Occhiena ci ha regalato, perché lo ha rilasciato in modalità Open Source, è un ottimo manuale di statistica di base. Dentro ci trovi tutte quelle nozioni fondamentali che dovrebbero essere conosciute da chiunque lavori in azienda, e non solo dai data expert.
Infatti, come scrivevo già tre anni fa, il lavoro di Carlo è una super introduzione alla statistica: quella parte di statistica che dovrebbe far parte del bagaglio di chiunque lavori con i dati, non solo dei data scientist. Semplicità nell’esposizione e rigore nella trattazione formale sono i suoi principali punti di forza.
“Ogni decisione che prendiamo,” scrive Carlo nell’introduzione, “può essere ricondotta a fenomeni statistici, innati (come la paura del buio, perché al buio aumenta la probabilità di incontrare animali pericolosi) o coscienti (oggi penso che probabilmente pioverà, quindi prenderò l'ombrello). D'altra parte, avvicinarsi anche a calcoli statistici di base (per esempio, la famigerata probabilità di vincere alla lotteria) richiede competenze non banali per applicare concetti e formule non sempre complessi, ma che certamente hanno risultati diversi se usati in modo sconsiderato. Sostengo con certezza che peggio della mancanza di pensiero matematico è l'uso improprio del pensiero matematico. Questo mio lavoro vuole infatti combattere i miei limiti attraverso lo studio e le applicazioni.”
Buono studio e... buona applicazione! 🚀
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!
Come sai, se dici agente, tocchi immediatamanete una delle nicchie dell'AI che più mi appassiona e mi coinvolge. Ne parlo spesso sui miei canali, e non fa eccezione questa settimana in cui affronto il ruolo cruciale del design di software ed architetture nel modo degli agenti.
Rispetto alla valutazione degli agenti una delle metriche che più spesso si usa è la capacità di autonomia intesa come la lunghezza dei task che sono in grado di eseguire senza interazione umana. Credo sia una metrica interessante, che mesa su un grafico da lpidea dell'evoluzione che stiamo vivendo. Se pensiamo ad un anno fa, l'iterazione era di pochi secondi o meno, nel loop fomanda/risposta tipico di un chat bot. Anche senza scomodare esempi più di nicchia, i vari deep research of agenti di coding in backgroung oggi arrivano facilmente a minuti o decine di minuti.