LaCulturaDelDato #206
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il duecentoseiesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del duecentoseiesimo numero:
👀 Data Science. Valentino Zocca: l’IA non ci renderà intelligenti… a meno che non la usiamo bene
Presentati :
Valentino Zocca. Matematico, con un dottorato dall’Università del Maryland, ho vissuto in Italia, Francia, Inghilterra e Stati Uniti. Mi piace essere informato e sfogliare diversi giornali ogni giorno. Nel tempo libero non disdegno teatro, opera o musei, nonché leggere. Ritengo che la cultura sia come il cibo, necessaria ed una forma di soddisfazione edonistica come un buon pranzo che appaghi e reputo l’ignoranza la più grande nemica del progresso, sia collettivo che individuale. Nonostante abbia vissuto più di 30 anni negli Stati Uniti, spero che l’Europa si risvegli dal sonno comatoso in cui è caduta negli ultimi decenni: purtroppo, come tutte le persone di una certa età, non comparo il presente al passato recente in maniera favorevole. Professionalmente, al momento sono “Director of Global Payment and Deposit Data” a TD Bank Group, dopo aver lavorato a Citi, US Census Bureau e Boeing.

Il mio ruolo tra 10 anni sarà ... (continua la frase come fossi GPT-10)
Intanto, non credo che vedrò un modello di IA realmente intelligente entro quei dieci anni. Invece, io forse vorrò scrivere o insegnare. Ma, soprattutto, spero di continuare ad imparare. Credo che ciò dovrebbe valere per tutti: qualunque sia il ruolo che abbiamo ora, si cerchi di continuare ad imparare, ma non per conseguire qualcosa, ma per il piacere di farlo. Un piacere che, purtroppo, sembra ormai che le generazioni correnti abbiano perduto. Vuoi che ti dica come fare per riprenderlo? (Quest’ultima frase l’ha aggiunta GPT-10).
Quale è la sfida più importante che il mondo dei dati e degli algoritmi ha di fronte a sé oggi?
Una delle barzellette che più mi piacciono racconta di una persona che arriva dal passato e rimane stupita nell’apprendere quanto siano potenti i nostri telefonini, grazie ai quali abbiamo accesso illimitato, tramite internet, a tutto lo scibile umano in qualunque momento. Sorpresa, la persona chiede: “Ma è fantastico! E come lo usate?”
“Ma per lo più guardiamo video di gatti e litighiamo online con degli sconosciuti”.
La sfida più importante sarà saper usare le nuove tecnologie per migliorare l’umanità, non renderla più pigra e superficiale. Per esempio, usando l’intelligenza artificiale per stimolare quella biologica. Anche per questo ultimamente mi sono interessato a cercare di conoscere meglio il funzionamento del cervello, che forse andrebbe studiato di più anche a scuola. Il fatto che 10.000 anni di storia, e soprattutto gli ultimi 500, abbiano creato un progresso tecnologico enorme ma relativamente poco progresso sociale, forse dovrebbe farci riflettere.
Segnalaci il progetto o la risorsa nel mondo dei dati di cui non potresti fare a meno … Ad essere onesto, non c’è nulla di cui non potrei fare a meno. Diciamo che tante cose sono utili, anche molto, ma ne abbiamo fatto a meno fino a poco tempo fa, quindi sapremmo andare avanti anche senza. Sono tuttavia senz’altro un utente dei vari LLMs, che conosco bene e di cui comprendo i limiti. Non vuol dire che non possano essere utili se usati in maniera appropriata, ma bisogna sapere cosa possono e non possono fare. Per il momento li uso principalmente a titolo personale. Per esempio Cursor mi ha aiutato a creare una “libreria” personale sul mio sito e Lovable a creare un prototipo per giocare a scacchi (un giorno spero di avere il tempo per poter addestrare un LLM che mi insegni a giocare bene). NotebookLM mi è molto utile per studiare e imparare velocemente. Ma, e non è dal mondo dei dati, ciò che uso di più da un paio di anni a questa parte sono le tavolette su cui si può scrivere, tipo Remarkable o Kindle Scribe. Utilissime per prendere appunti, scrivere note, aggiungere appunti a libri, ecc. E li posso usare al lavoro e poi trascrivere le note in pdf di testo. Ormai ne ho sempre una con me.
PSS (Post scriptum di Stefano): A proposito di intelligenza … Valentino ha anche una bellissima newsletter su substack dove parla in maniera decisamente intelligente proprio anche di come funziona la nostra mente!
👃Investimenti in ambito dati e algoritmi. Start-up of the Month Gennaio 2026. Synthesia
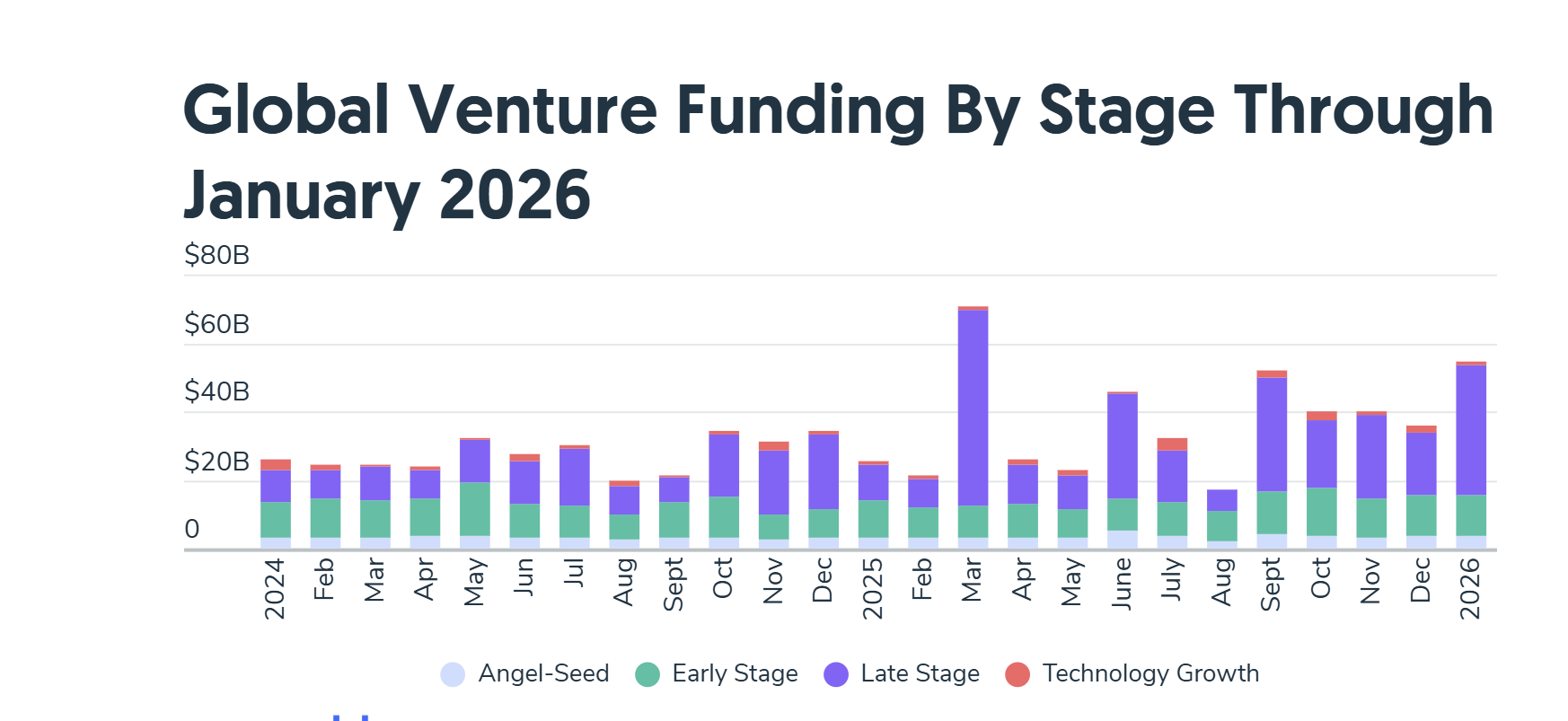
I dati vanno letti sempre con molta attenzione. Se guardassimo solo il totale del funding VC su scala mondiale di gennaio 2026 (numeri riportati sempre con grande puntualità da Crunchbase), potremmo raccontare un’altra crescita significativa della raccolta, con un dato in aumento di più del 100% rispetto a gennaio 2025.
In realtà, al netto dei late stage e soprattutto del round Series E da 20 miliardi di xAI, la storia è diversa: parliamo di una crescita moderata, con early stage abbastanza piatto e con angel-seed in buona crescita. Quello che vedo dal mio database di funding di start-up è comunque una grande concentrazione in quattro settori specifici: AI, Robotica, Healthcare e Infrastrutture, che insieme fanno più del 75% degli investimenti. E c’è anche una concentrazione geografica negli USA, che contano per più di due terzi dei finanziamenti.
La start-up del mese è Synthesia.
Synthesia nasce a Londra nel 2017 dall’incontro fra ricerca e prodotto: Victor Riparbelli (CEO) e un team di co-founder accademici (tra cui Lourdes Agapito e Matthias Niessner), con l’idea (allora controintuitiva) di creare video senza camere, set o attori. Victor Riparbelli è cresciuto a Copenhagen con una passione precoce per i computer e un temperamento che lui stesso definisce “ribelle”. Costruiva siti ed e-commerce per attività locali già da adolescente, usando piattaforme come Shopify. Dopo un semestre a Stanford e un passaggio nella scena startup londinese, nel 2016 si imbatte nel paper “Face-to-Face” del Prof. Matthias Niessner sulla generazione video con AI e capisce subito di aver trovato qualcosa di enorme. Nel tempo, il “trucco” tecnico (avatar realistici che parlano a partire da un testo) è diventato una piattaforma enterprise: trasformi uno script in un video con un avatar, in molte lingue, per training, comunicazione interna e commerciale e knowledge sharing.
A livello di funding, la progressione è molto importante e rapida:
Giugno 2023 – Series C: $90M, round guidato da Accel, con NVIDIA (NVentures) e altri investitori; valutazione dichiarata $1B.
Gennaio 2025 – Series D: $180M, round guidato da NEA; valutazione $2,1B e capitale totale raccolto oltre $330M.
Gennaio 2026 – Series E: $200M, valutazione $4B, round guidato da Google Ventures con partecipazione di Evantic e Hedosophia.
Ho provato e usato la piattaforma per un progetto aziendale e sono rimasto francamente impressionato dalla facilità d’uso e dalla qualità del risultato.
Credo anche che il caso d’uso sia molto importante e ad alto impatto perché affronta un problema enorme e sottovalutato: la produzione di contenuti formativi e comunicazioni interne è lenta, frammentata e costosa. Ridurre tempi e costi dei video significa sbloccare scalabilità (e coerenza) su onboarding, compliance, aggiornamenti di prodotto.
🖐️ Tecnologia (data engineering). 2026: l’anno che ci porterà dal “come” al “cosa”?
Se il 2025 è stato l’anno in cui abbiamo capito che l’intelligenza artificiale renderà la scrittura del codice sempre più semplice ed economica, il 2026 sarà l’anno in cui dovremo chiederci: cosa vogliamo costruire davvero? E, soprattutto, come possiamo coinvolgere il maggior numero di persone in azienda in questo processo?
In questo scenario, il tuo ruolo, se ti occupi di tecnologia, scrivi software o analizzi dati, deve cambiare radicalmente. So bene che questo passaggio non sarà affatto semplice e che il 2026 non basterà a completarlo, ma credo che lo ricorderemo come l’anno in cui il processo si è attivato su larga scala.
L’approfondimento che ti consiglio oggi parla proprio di questo. Lo ha scritto Anish Acharya, General Partner di Andreessen Horowitz (a16z), che guida gli investimenti in ambito Consumer e AI. Pur essendo molto “visionario”, il punto di vista di Acharya offre spunti su cui riflettere seriamente.
Ecco i quattro punti chiave su cui sto ragionando e su cui mi piacerebbe sapere cosa ne pensi:
Dai tool di esecuzione a quelli di esplorazione: finora abbiamo usato l’AI per scrivere codice o creare modelli (pensa a Figma). Ora la sfida si sposta sul cosa costruire. Arriveranno tool che non servono più solo a “fare”, ma a “pensare” insieme a te, esplorando ipotesi e testando feature in autonomia.
L’azienda diventa interamente “software-first”: funzioni tradizionalmente “human-intensive” come il legale, le HR o il procurement devono imparare a usare il software come prima risorsa. Ogni team diventerà, di fatto, un team di sviluppo che usa agenti specializzati nel proprio contesto (e sui propri dati proprietari).
App vs Modelli: c’è chi teme che i grandi modelli (OpenAI, Google, Anthropic) spazzeranno via le startup. Probabilmente non sarà così, o almeno non del tutto. Le App AI stanno divergendo dai modelli di base: vincerà chi saprà orchestrare più modelli, sfruttare dati proprietari e offrire un’interfaccia (UI) specifica per il dominio.
L’interfaccia è il limite: la riga di comando ha frenato l’adozione di massa. Il 2026 sarà l’anno in cui anche chi non ricopre ruoli tech inizierà a capire che creare una soluzione software sta diventando incredibilmente facile. In questo percorso, se ti occupi di dati e integrazione di sistemi, giocherai un ruolo di facilitatore fondamentale.
Se il 2025 ci ha insegnato a produrre codice a basso costo, il 2026 segnerà il momento in cui cambieremo radicalmente il modo in cui lavoriamo e costruiamo le aziende.
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Decidere nell’incertezza: due letture (Cohen + Abraham Thomas) per decidere meglio 🙂
Quando prendi decisioni per te o per un gruppo di persone con cui lavori, la cosa che, più o meno esplicitamente, si fa sempre è fare ipotesi sul futuro. Cioè: costruisci scenari di futuri possibili che possono aiutarti a prendere una decisione. Questo era l’argomento dell’approfondimento del numero 84 della newsletter, ed è stato di gran lunga quello che ti era piaciuto di più. Tra l’altro tocca uno dei punti critici per noi analitici data-lover, abituati a cercare di dettagliare al meglio tutti gli scenari possibili… finendo spesso per perdere tempo e vivere male il processo decisionale. Almeno io ho vissuto tante volte questi momenti e, per fortuna più raramente, mi capita ancora.
L’articolo a cui faccio riferimento è “Navigating the unpredictability of everything” di Jason Cohen. L’articolo, ironicamente, è esso stesso molto analitico e ricco di esempi. Ma per una volta perdere tempo leggendolo potrebbe farti guadagnare tempo in futuro. Soprattutto: il tema dei coni di futuri possibili è qualcosa non facile da metabolizzare e usare quando serve.
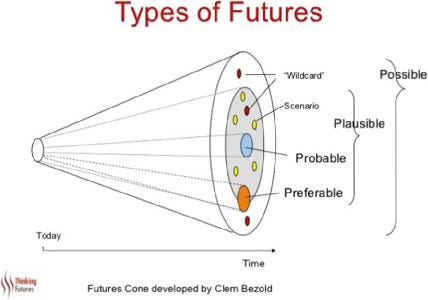
E a proposito di esempi, il modo (raccontato da Cohen nell’articolo) in cui Slack e WhatsApp hanno raggiunto il successo è esemplare. I casi di successo hanno spesso due elementi in comune: una strategia (gestita con opzionalità) e la capacità di seguire il cliente, comprendendo anche gli utilizzi imprevisti, o meglio, serendipici, del prodotto stesso. Più in generale, il punto saliente è che “prendere una decisione e proseguire è spesso più efficace di una lunga riflessione sulla decisione”.
Se posso aggiungere un’altra lettura che ti suggerisco in combo a questa, è il framework decisionale di Abraham Thomas di cui ti ho parlato nel numero 98. L’articolo è breve, incisivo e descrive brillantemente i 4 quadranti in cui possiamo trovare quando dobbiamo prendere una decisione, indicando anche la zona migliore in cui trascorrere la maggior parte del nostro tempo 🙂. E il messaggio è in linea e molto complementare con quello di Cohen.
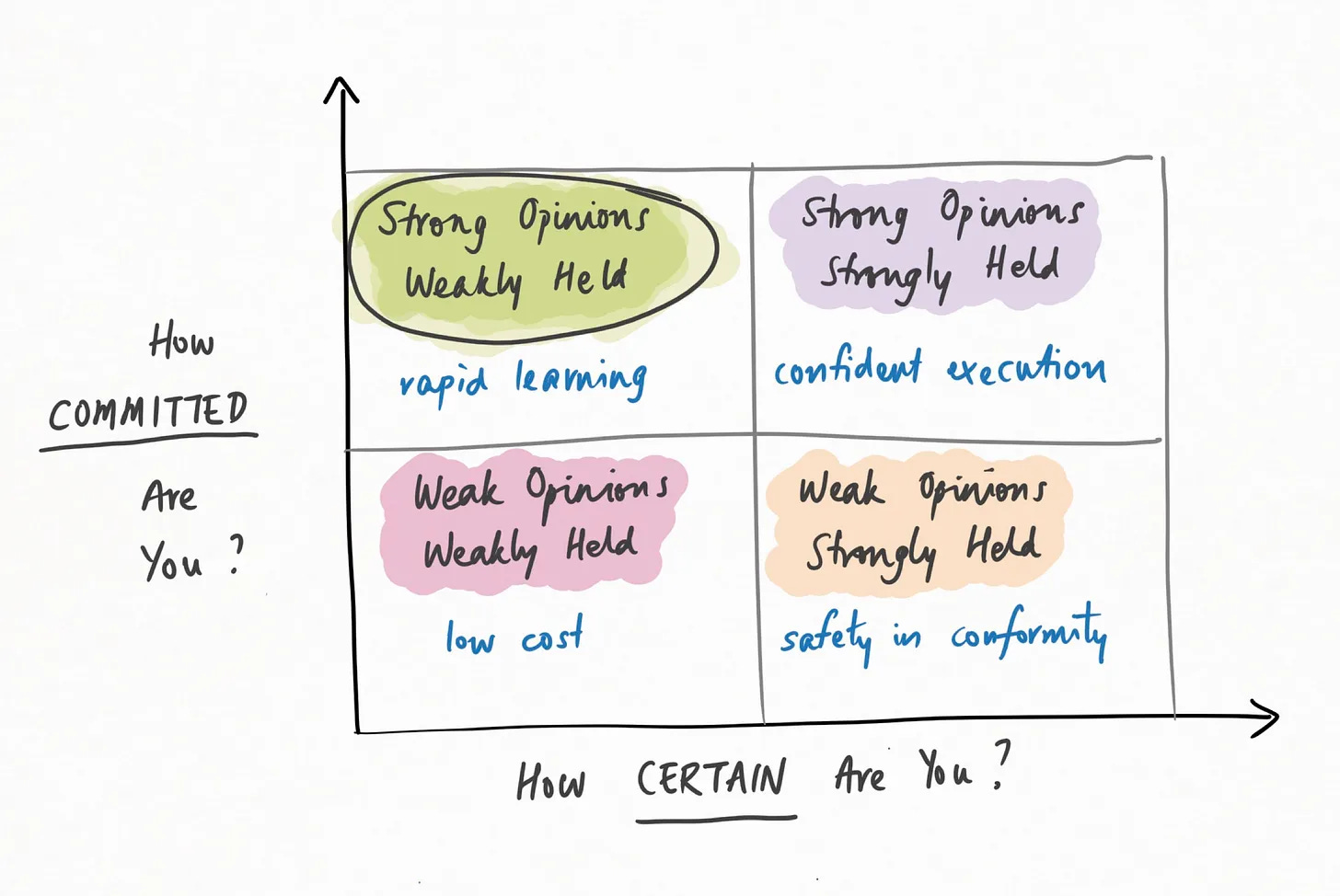
Essere decisionista e metterti in discussione spesso sembra la strategia migliore. Soprattutto nel dinamismo attuale.
👅Etica & regolamentazione & impatto sulla società. AI e ricerca pura: la lezione di Raghavan su grafi, teoremi e collaborazione uomo-macchina
Uno dei temi più interessanti e promettenti nell’uso dell’AI generativa è l’applicazione alla ricerca scientifica e a tutte quelle “scienze pure”, quali la matematica e la fisica, dove la ricerca non ha come obiettivo immediato un’applicazione pratica (come un nuovo cellulare o un farmaco), ma la comprensione delle leggi fondamentali.
Ci sono sicuramente tanti progetti e anche start-up che stanno investendo in questo ambito, ed è sicuramente un utilizzo molto più lungimirante che usare l’AI solo per l’ottimizzazione di attività ripetitive umane. Ma riuscire a ottenere risultati e a dimostrarli non è affatto semplice. L’approfondimento che ti suggerisco oggi può farti percepire quanto complesso e non scontato sia tutto questo.
Il video che ti suggerisco è la registrazione (grazie Paolo Ferragina per la segnalazione) di una conferenza tenuta da Prabhakar Raghavan presso la Scuola Superiore Sant’Anna di Pisa il 2 ottobre 2025. Il tema centrale è l’uso dell’Intelligenza Artificiale come assistente nella ricerca scientifica, con un focus specifico sulla matematica e l’informatica teorica. Prabhakar Raghavan è una figura di spicco nel mondo tecnologico e accademico. Attualmente è Chief Technologist di Google (precedentemente a capo di Search, Ads e Geo), ma è anche un rinomato informatico, noto per i suoi contributi fondamentali agli algoritmi randomizzati e al reperimento di informazioni (Information Retrieval). È co-autore di testi accademici di riferimento come “Randomized Algorithms”. Ha lavorato in IBM Research e Yahoo! Labs prima di approdare in Google. La sua carriera unisce una profonda conoscenza teorica a una visione strategica sull’innovazione su scala globale.
La parte centrale della conferenza è molto tecnica e necessita di un minimo di conoscenza su argomenti relativi ai grafi. In sintesi, la ricerca, che ha utilizzato AlphaEvolve (uno strumento sviluppato da DeepMind che utilizza un approccio evolutivo), è riuscita a trovare una costruzione grafica per un grafo a 19 nodi che ha permesso di migliorare il limite di approssimabilità del problema del Max 4-Cut, superando un record che resisteva dal 2014.
Ma i messaggi chiave sono, a mio parere, all’inizio e alla fine del suo intervento, e sono tre:
Il Paesaggio Frastagliato (Jagged Landscape) dell’AI: Raghavan spiega che l’AI non ha una “intelligenza” uniforme, ma eccelle in alcuni compiti mentre fallisce in altri banali. Lo standard accettabile per un’AI dipende dal compito (es. un chirurgo robotico deve essere migliore del miglior umano, non della media).
Collaborazione Uomo-AI: Raghavan sottolinea che l’AI non ha “capito” la matematica che stava facendo; ha semplicemente ottimizzato un punteggio fornito dagli umani. L’intuizione e la guida rimangono umane.
Evoluzione della Ricerca: Sempre secondo Raghavan, vedremo sempre più teoremi con la dicitura “scoperto per primo dall’AI”, anche se poi gli umani troveranno modi più eleganti per spiegarli.
Se sei un graph-lover (come me), anche la parte più tecnica con Wikipedia e un LLM è accessibile, e la sua comprensione fornisce una soddisfazione umanissima 🙂
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!