LaCulturaDelDato #211
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il duecentoundicesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del duecentoundicesimo numero:
👅Etica & regolamentazione & impatto sulla società. AGI: il paper che prova a mettere ordine nel caos
Tutti i modelli sono sbagliati, ma possono essere molto utili per condividere e discutere in modo comune una tematica o un problema. Questo vale ancora di più quando il modello prova a descrivere qualcosa davvero difficile da definire e su cui convivono punti di vista molto contrastanti. In questo caso sto parlando di AGI (Intelligenza artificiale generale), un tema su cui si è sentito tutto e il contrario di tutto, soprattutto da novembre 2022. Per questo, quando molti lettori mi hanno segnalato il paper oggetto dell’approfondimento di oggi, mi ci sono avvicinato con la speranza che potesse aiutare a fare un po’ di chiarezza su un tema quasi “intrattabile”. E, secondo me, mantiene la promessa. Lo spiega bene anche l’abstract, in cui i 33 autori di grande esperienza nel settore, tra cui ti segnalo Erik Brynjolfsson, Max Tegmark, Gary Marcus, Eric Schmidt e Yoshua Bengio, mostrano l’approccio usato per affrontare il problema.
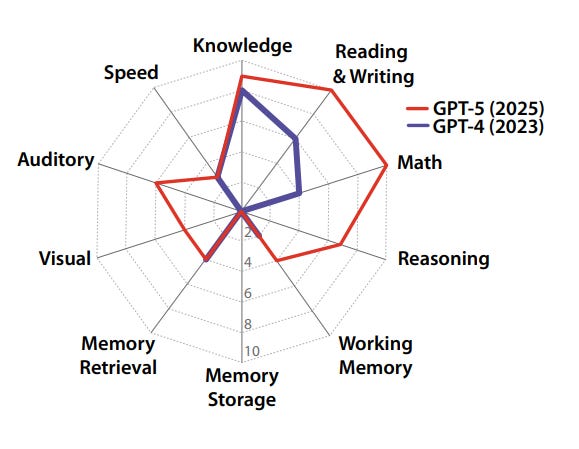
“La mancanza di una definizione concreta di Intelligenza Artificiale Generale, o AGI, rende difficile capire quanto sia ampia la distanza tra l’AI specialistica di oggi e una cognizione di livello umano. Questo paper propone un framework misurabile per affrontare il problema, definendo l’AGI come la capacità di eguagliare la versatilità cognitiva e il livello di competenza di un adulto ben istruito. Per rendere operativa questa definizione, gli autori si basano sulla teoria Cattell-Horn-Carroll, oggi il modello della cognizione umana più solido sul piano empirico. Il framework scompone l’intelligenza generale in dieci domini cognitivi fondamentali, tra cui ragionamento, memoria e percezione, e adatta metriche psicometriche già usate sugli esseri umani per valutare i sistemi di AI. Applicando questo approccio emerge un profilo cognitivo molto irregolare nei modelli contemporanei: se da un lato eccellono nei compiti ad alta intensità di conoscenza, dall’altro mostrano carenze importanti nei meccanismi cognitivi di base, soprattutto nella memoria a lungo termine. I punteggi AGI risultanti, per esempio 27% per GPT-4 e 57% per GPT-5, rendono visibili sia la rapidità dei progressi sia la distanza ancora significativa che separa questi sistemi da una vera AGI.”
Quello che apprezzo è che la definizione, e ci tengo a sottolinearlo, abbraccia solo una parte ben specifica delle capacità umane, cioè “la versatilità cognitiva e il livello di competenza di un adulto ben istruito”, tralasciando altre caratteristiche più vicine agli aspetti fisici dell’uomo, che però, come ormai la scienza ci ha insegnato, sono connesse anche alla parte cognitiva stessa.
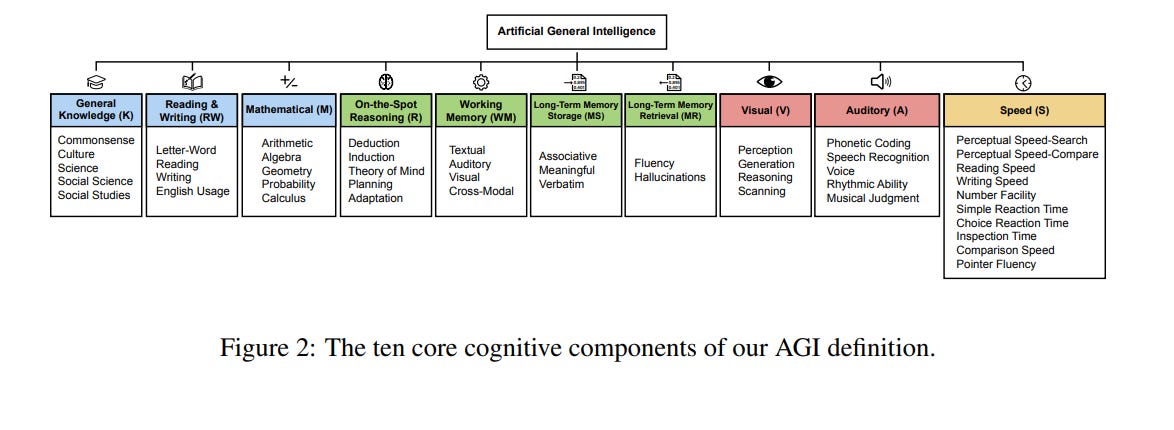
Quello che mi è piaciuto, e che trovo di grande valore, è il framework su cui è costruito: una suddivisione in 10 ambiti, descritti in modo concreto e ulteriormente spezzati in sotto-ambiti, che rende tutto molto più misurabile e monitorabile nel tempo. Il paper, da solo, vale la lettura anche solo per la descrizione degli ambiti e delle tecniche e delle stesse metodologie di misurazione. Il tutto è sintetizzato anche in un grafico radar, che evidenzia bene la progressione osservata negli ultimi due anni. L’utilizzo di ChatGPT può sembrare una limitazione, ma ha senso perché, ad oggi, è il sistema su cui abbiamo la maggiore profondità storica di osservazione. Inoltre, il framework sembra abbastanza adattabile anche ad altre intelligenze artificiali.
Per quanto il concetto di AGI sia discutibile e opinabile, questo paper mi sembra uno dei migliori tentativi visti fin qui per fare chiarezza e dare più trasparenza alla discussione.
👃Investimenti in ambito dati e algoritmi. L’AI non ti renderà (forse) ricco ma può renderti più intelligente 🙂
“Chiunque investa in una cosa nuova deve rispondere a due domande: in primo luogo, quanto valore creerà questa innovazione? E in secondo luogo, chi ne trarrà vantaggio? La tecnologia dell’informazione e della comunicazione (ICT) è stata una rivoluzione il cui valore è stato sfruttato dalle startup e ha portato alla nascita di migliaia di nuovi ricchi imprenditori, dipendenti e investitori. Al contrario, la containerizzazione delle spedizioni è stata una rivoluzione il cui valore è stato distribuito in modo così sottile che, alla fine, ha reso temporaneamente ricco un solo fondatore e solo un po’ più ricco un solo investitore.”
Con queste parole Jerry Neumann, investitore e docente alla Columbia, apre un saggio lungo e denso che smonta una narrazione molto trendy e comoda: l’AI generativa come il nuovo microprocessore, segna l’inizio di un’ondata che premierà chi arriva prima. La sua tesi è diversa, e fa riflettere. L’AI non è l’inizio di una nuova ondata tecnologica. È la fase di maturità dell’ondata ICT iniziata cinquant’anni fa. E nelle fasi di maturità, i soldi non li fanno gli innovatori, li fanno i clienti. L’analogia chiave è con la containerizzazione marittima. Malcom McLean rivoluzionò il trasporto merci negli anni ‘50, ma la tecnologia era visibile a tutti, nessuno fu colto di sorpresa, la competizione scattò immediatamente e i margini crollarono. McLean vendette in tempo. Gli altri, no. Il valore finì a chi usava i container non a chi li costruiva. Secondo Neumann, con l’AI sta succedendo la stessa cosa: i model builder finiranno in oligopolio a margini compressi, le applicazioni saranno schiacciate dalle integrazioni verticali, e l’infrastruttura (Nvidia inclusa) è già prezzata per una curva a S che potrebbe non arrivare.
Gil Dibner, general partner di Angular Ventures, arriva (quasi) alla stessa destinazione da un’altra strada. Il suo punto di partenza non è la storia economica ma una domanda scomoda: e se la vera bolla non fosse l’AI, ma il lavoro umano? Dibner sostiene che esiste una “human labor bubble”, una sopravvalutazione sistemica di task ripetitivi e a basso impatto che assorbono costi enormi senza generare valore proporzionale. Milioni di ore spese in data entry, classificazione manuale, persone che funzionano da “API umane” facendo lavori ripetitivi e a bassissima produttività. Se lavori in una grande azienda (qualunque) puoi capire 🙂. L’opportunità vera dell’AI, dice Dibner, non sta nell’ automatizzare interi mestieri, ma nell’approccio bottom-up: identificare queste sacche di lavoro sopravvalutato ed eliminarle con i modelli che già esistono. Attenzione però: farlo in produzione è tutt’altro che banale: servono guardrail, human-in-the-loop, gestione delle allucinazioni e tanto altro. Ed è proprio questa complessità implementativa a creare spazio per aziende difendibili.
Metti insieme le due prospettive e il messaggio converge: il valore dell’AI si cattura a valle, non a monte. Non costruendo modelli o infrastruttura (lo fanno e faranno in pochissimi), ma applicando l’AI dove il lavoro umano è più sopravvalutato e i processi knowledge-intensive più inefficienti. Entrambi sembrano suggerirci di non guardare solo chi costruisce la tecnologia, ma chi la usa meglio. Detto questo, una critica costruttiva va fatta a entrambi. Il parallelo containerizzazione-AI è interessante ma ha un limite: i container facevano una cosa sola, l’AI è general-purpose e ricombinabile. I modelli open-weight (Llama, Mistral, DeepSeek) stanno rendendo l’AI sempre più distribuita, esattamente la condizione che Neumann stesso indica come necessaria per innescare una nuova ondata. E Dibner, concentrandosi sul lavoro ripetitivo, sottovaluta forse il potenziale trasformativo dell’AI sul lavoro cognitivo complesso, dove i guadagni di produttività potrebbero essere molto più grandi (e difendibili) delle pure efficienze operative.
Come lettore e investitore, il mio consiglio è questo: non prendere queste tesi come profezie, ma usale come stress test. Quando qualcuno ti dice che l’AI è il nuovo internet e che basta salire sul treno giusto, ricordati che c’è una tesi contrarian seria e ben argomentata che dice il contrario. La verità probabilmente sta nel mezzo: ma il mezzo lo trovi solo se ascolti anche le voci fuori dal coro!
🖐️Tecnologia (data engineering). Un sito per ripassare algoritmi (senza delegare tutto all’AI) 🙂
In un momento storico in cui le intelligenze artificiali stanno diventando sempre più brave nel supportare i data scientist e i data lover a scrivere codice e a implementare la parte più operativa degli algoritmi, diventa parte della trasformazione del ruolo avere una conoscenza ancora più orizzontale. E questo comporta, per esempio, conoscere quanti più algoritmi possibili, per risolvere i problemi che abbiamo di fronte. Per questo, tre anni dopo, ti ripropongo una risorsa: la più amata tre anni fa nel numero 89 della newsletter, che cerca proprio di aiutarci a conoscere, capire o anche semplicemente a ripassare una parte degli algoritmi più diffusi in Computer e Data Science. Il tutto viene fatto in maniera visuale e interattiva, e rende la risorsa ancora più preziosa e utile. Tra gli algoritmi raccontati in maniera interattiva c’è una netta prevalenza di algoritmi su grafo che sono anche, a mia esperienza, i più ostici da comprendere senza una trattazione visuale.

Il progetto è anche una bellissima storia di Open Science e Open Education, nata nel Sud-Est del mondo e implementata all’interno dell’Università di Singapore, in un progetto di flipped classroom. Ne avevo parlato appunto presentandola nel numero 89 della newsletter. Se sei curioso, parti da lì, ma usa tutto il tempo restante per navigare qualche algoritmo: ne vale la pena e può essere un’ottima risorsa da salvare tra i preferiti per quando ne avrai bisogno, senza necessariamente delegare anche la scelta dell’algoritmo a un’intelligenza artificiale 🙂
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Serve un AI Transformation Officer in azienda? I 4 ingredienti che fanno la differenza
Le aziende, in questo momento storico, manifestano (quasi) tutte il desiderio di trasformarsi adottando l’AI su larga scala. Con la parola aziende mi riferisco ai vertici, oppure a chi, all’interno dell’organizzazione (anche senza ruoli apicali), percepisce la necessità di questa trasformazione. Spesso mi viene chiesto, durante incontri pubblici, se abbia senso che questo percorso sia guidato da un leader con un team a suo supporto. E quindi se abbia senso definire all’interno di un’organizzazione un ruolo che può avere nomi tra i più diversi, come “AI Transformation Officer”, “Head of AI”, “AI Director”… ma che, più o meno, ha come obiettivo la stessa cosa. Non ho francamente la risposta assoluta: sì o no… ma, come spesso si risponde alle domande complesse… dipende!
Ho avuto, in differenti tipologie di aziende, ruoli simili in domini quali l’innovazione e i dati, che per certi versi hanno anticipato la trasformazione con l’AI di cui si parla più frequentemente oggi. La mia esperienza è che, per essere efficaci, servono 4 ingredienti fondamentali. Li elenco:
Avere il supporto del CEO o di chi guida l’intera strategia aziendale
Avere risorse (budget economico e risorse umane) adeguate agli obiettivi
Poter e saper scegliere le risorse umane che si utilizzeranno in questa trasformazione
Avere a disposizione (e negoziarlo) tempo per permeare la cultura dell’azienda durante questa trasformazione
Chiaramente ogni trasformazione, e l’AI in primis, ha specificità che la rendono diversa da altri tipi di trasformazione. Su questo tema ho letto molto in questi ultimi mesi e ti segnalo tre contributi che mi sono piaciuti e mi hanno fatto pensare. Non sono d’accordo al 100% su quello che dicono, ma anche per questo valgono la lettura:
Datapizza e, in particolare, il bravissimo Giacomo Cialini parla qui di AI Transformation Advisor e di quello che dovrebbe fare
Giuseppe Mayer parla in questo post dell’anatomia di chi ce la fa con l’AI, delineando le caratteristiche dei migliori casi di trasformazione
Michael Spencer, nel suo “AI Supremacy”, parla in questo lunghissimo post di AI adoption, con tantissimi dati e informazioni sulle trasformazioni in corso a varie latitudini e in diverse tipologie di aziende
👀 Data Science. K-means: l’algoritmo di clustering che (quasi) tutti devono conoscere
C’è un algoritmo che ogni data scientist usa, che ogni manager dovrebbe conoscere e che, se lo guardi per la prima volta, ti sembra quasi troppo semplice per essere vero. Si chiama K-means, ed è uno dei più potenti strumenti di apprendimento non supervisionato che esistano. Se vuoi partire da una spiegazione solida e ben costruita, un buon punto di partenza è ML Pills, Issue 106 di David Andrés: chiaro, progressivo, con esempi visivi e codice Python pronto all’uso.
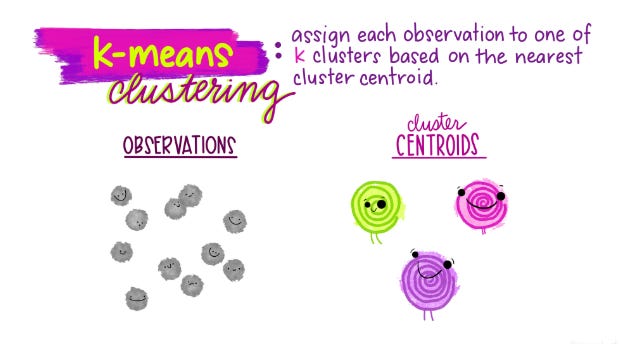
Nella maggior parte del machine learning di cui senti parlare, previsioni di churn (perdita di clienti), scoring del credito, modelli di fraud detection, l’algoritmo impara da esempi già etichettati: “questo cliente ha abbandonato”, “questa transazione è fraudolenta”. Serve qualcuno che abbia già lavorato i dati, li abbia classificati e li abbia ‘insegnati’ al modello. K-means funziona diversamente: non ha bisogno di etichette, né di dati pre-lavorati in modo sofisticato. Gli dai un insieme di dati grezzi, gli dici quanti gruppi vuoi trovare (K, appunto) e lui li trova autonomamente, cercando la struttura nascosta senza che tu gliela mostri prima. Il meccanismo è elegante nella sua semplicità. L’algoritmo posiziona K centri (i centroidi) nello spazio dei dati, assegna ogni punto al centroide più vicino, ricalcola i centroidi come media dei punti assegnati e ripete il processo fino a convergenza. Il nome “K-means” viene proprio da questo: K gruppi, costruiti attorno alle medie. Allison Horst, datascientist e illustratrice, ha creato alcune delle spiegazioni visive più belle che conosca su questo algoritmo: le avevo già segnalate nel numero 41 della newsletter e le consiglio ancora, soprattutto se hai colleghi o studenti a cui vuoi spiegare il concetto senza partire dal codice.
I casi d’uso concreti del K-means sono molti. La segmentazione clienti è il più classico: raggruppa i tuoi utenti per comportamento d’acquisto, frequenza o valore senza definire a priori le categorie e scopri che esistono alcuni tipi di cliente che non sapevi di avere. Ma K-means funziona bene anche per l’anomaly detection (i punti lontani da tutti i centroidi sono candidati ad essere anomalie, utili in contesti di fraud o qualità dei dati), per la sintesi di cataloghi (raggruppa migliaia di prodotti in famiglie omogenee per semplificare pricing e reporting) e per la personalizzazione di contenuti e offerte, senza bisogno di regole definite a mano.
L’algoritmo ha i suoi limiti, che vale la pena conoscere: va aiutato nella scelta del K giusto, soffre con cluster di forma irregolare e richiede che le variabili siano su scale comparabili: va fatta la normalizzazione prima. Vale anche la pena ricordare che la scelta di K è il momento in cui l’algoritmo “non supervisionato” torna a dipendere dal giudizio umano: un bel promemoria sul fatto che anche i modelli più automatici nascondono decisioni di design. Un ultimo punto pratico: nel mondo del clustering esistono algoritmi più sofisticati come DBSCAN, clustering gerarchico, Gaussian Mixture Models, ma K-means rimane il baseline da cui partire. Se un approccio più complesso non produce cluster migliori, stai pagando complessità senza ritorno. E questa è una delle lezioni più utili che questo algoritmo può insegnarci.
📅 Nel Mio Calendario (passato, presente e futuro)
Oggi vi segnalo qualcosa di un po’ insolito: sono io il protagonista di una puntata, uscita ieri, della newsletter StrategyProject Journal di Andrea Macrì. Il titolo dice già tutto: “Comprare fuori non lascia nulla dentro”. Si parla di una scelta che ho fatto nel 2014 in Cerved, investire €1,3M in una startup di Trento invece di aprire un progetto di consulenza, e di come quello stesso principio abbia guidato il mio modo di lavorare negli anni successivi, a scale sempre diverse. È un pezzo su Open Innovation, su come si costruisce competenza che rimane dentro l’organizzazione, e su perché l’allineamento degli incentivi vale più di qualsiasi clausola contrattuale. Con numeri, trade-off espliciti e qualche domanda scomoda da portare in riunione. Se vi interessa capire come si porta l’innovazione dentro senza che se ne vada più, lo trovate qui.
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!
Grazie ancora Stefano per il tuo prezioso contributo in StrategyProject Journal!