

LaCulturaDelDato #163
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il centosessantatreesimo numero della newsletter LaCulturaDelDato: dati & algoritmi attraverso i nostri 5 sensi. Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
🚀 Questa puntata è sponsorizzata da “Data Masters”
L’adozione dell’Intelligenza Artificiale nei contesti aziendali comporta nuove responsabilità, rischi sistemici e obblighi normativi che non possono più essere ignorati. Il Regolamento Europeo sull’AI (AI Act) rappresenta oggi il quadro di riferimento per ogni organizzazione che intenda sviluppare o utilizzare soluzioni di AI in modo conforme, responsabile e sostenibile.
Il corso “AI Act: Governance, Rischi e implementazione responsabile dell’AI in azienda”, promosso da Data Masters, offre un percorso formativo completo per affrontare queste sfide. Si tratta di quattro webinar in diretta, a partire dal 20 maggio, guidati da Pierluigi Casale, ex AI Officer al Parlamento Europeo e contributor dell’AI Act. Il programma è pensato per aiutare imprese e professionisti a comprendere la normativa, anticipare le criticità e applicare strategie di compliance efficaci.
Durante il corso si analizzeranno casi documentati, incidenti legati all’uso scorretto dell’AI e simulazioni guidate per classificare i rischi, valutare la conformità dei sistemi e correggere eventuali bias. L’approccio è operativo e si basa su scenari concreti: chatbot fuori controllo, sistemi di selezione del personale distorti, fallimenti nella gestione algoritmica del rischio, fino alla valutazione dell’Intelligenza Artificiale Generale.
I partecipanti impareranno a:
- Governare l’AI in azienda con audit, responsabilità e documentazione strutturata
- Classificare i sistemi secondo le categorie dell’AI Act, dai sistemi vietati a quelli ad alto rischio
- Applicare strumenti pratici per garantire trasparenza, tracciabilità e sicurezza
- Simulare analisi di rischio sistemico secondo i criteri presenti nell’AI Act
Il corso è rivolto a manager dell’innovazione, compliance officer, sviluppatori, giuristi, policy maker e consulenti, e fornisce le competenze necessarie per affrontare le implicazioni legali, strategiche ed etiche dell’adozione dell’intelligenza artificiale.
Data Masters è una Tech Academy italiana che offre percorsi di formazione per professionisti ed aziende in Data Science, Machine Learning e Intelligenza Artificiale.
Ed ora ecco i cinque spunti del centosessantatreesimo numero:
🖐️Tecnologia (data engineering). Se scrivi software, leggi questi tre articoli (e respira)
In un mondo in cui c’è qualcuno che si definisce "The last piece of software", cioè l'ultimo software che dovrà mai essere scritto manualmente da un essere umano, farsi prendere dall’ansia – per chi ama scrivere software e lo fa da una vita – è decisamente umano. E tra l’altro, a definirsi così è Lovable, un’azienda svedese che realizza un prodotto davvero figo per creare applicazioni web. L’ho provato: utilissimo, sì, ma ben lontano dal risolvere anche solo una piccola parte delle reali necessità che il mondo ha di software fatto bene e resiliente.
Nonostante questo, il mio consiglio a chi scrive codice (che do coerentemente anche a casa, a mio figlio maggiore che sta finendo la triennale in Computer Engineering al Politecnico di Milano) è di rimanere sempre molto aggiornato sui trend e sugli strumenti che aiutano a scrivere codice in modo più facile e veloce. Ma soprattutto: imparare a integrare queste tecnologie in tutte le attività di sviluppo software, non solo nella scrittura del codice in senso stretto.
Per questo, gli approfondimenti che ti consiglio oggi vanno proprio nella direzione di aiutarti a rimanere aggiornato e a capire – da persone molto esperte e ancora legate alla scrittura del codice – i possibili scenari futuri di come cambierà questa professione. Sul fatto che cambierà (o stia già cambiando), francamente, non ho alcun dubbio.
Il primo consiglio arriva da Eugene Yan, Principal Applied Scientist in Amazon, abituato a costruire in prima persona sistemi di raccomandazione e software fortemente integrato con l’AI. Il suo post ha un titolo super accattivante: “39 Lessons on Building ML Systems, Scaling, Execution, and More”. Il tutto nasce da un’esigenza che, almeno una volta nella vita, abbiamo sperimentato: “Le conferenze ML di settore sono intense. Le informazioni, l'apprendimento e il cambio di contesto tra conferenze e conversazioni in corridoio sono talmente tanti da lasciare esausti ogni giorno. Pertanto, ogni volta che c'è una pausa, prendersi qualche minuto per riflettere e prendere appunti aiuta a consolidare l'apprendimento. Ecco i miei appunti dalle conferenze di Machine Learning del 2024.” E sono davvero 39 mini-lezioni dense e utili. Se scrivi codice legato al Machine Learning sono imperdibili – ma anche se non lo fai (ancora), non è tempo perso. La mia preferita? La prima, perché è la più generalmente applicabile: “1. Il mondo reale è un casino. Per costruire sistemi che funzionino, dobbiamo definire le funzioni di ricompensa (che definiscono il modo in cui etichettiamo i dati), descrivere il mondo attraverso i dati, trovare le leve che fanno la differenza e misurare ciò che conta. Diffidate da chi vi dice che il ML è una passeggiata.” Ma anche le altre 38 lezioni meritano!
Il secondo contributo è di Geoff Huntley, Principal Developer Advocate. Nasce da uno scambio di mail con uno studente informatico preoccupato, e diventa una generalizzazione dei suoi consigli a chi studia ingegneria del software. Il titolo è già una sintesi potentissima: “Dear Student: Yes, AI is here, you're screwed unless you take action…”. In realtà, l’articolo è per tutti. Ripercorre 40 anni di inverni e primavere del mondo dello sviluppo software, e nel finale offre consigli validi per sviluppatori di tutte le età.

Non fermarti all’immagine che ti condivido, ma leggi tutto l’articolo: ne vale davvero la pena. Io l’ho obbligato a leggerlo anche a mio figlio maggiore 😄
Il terzo spunto arriva – come piace a me – da un VC molto smart: Angular Ventures. Con una prospettiva originale sulla “fine dello sviluppo software umano”, offre una riflessione preziosa. Soprattutto se stai pensando di investire tempo e denaro in questo ambito. Non so se sia uno scenario davvero probabile, ma – per citare il mio amico
– sicuramente è uno scenario preferibile. Ecco la sintesi finale, davvero illuminante: “Forse il vero stato finale della ‘fine del software’ non è un mondo senza ingegneri informatici o codice, ma un mondo in cui il software diventa malleabile ed espressivo come qualsiasi altro mezzo creativo. [...] In questo stato finale, i confini tra sviluppatore e utente sfumano completamente e il software diventa un'altra tela per la creatività umana: usa e getta, personalizzata, incentrata su una nicchia e continuamente reinventata. [...] E questo è un futuro in cui vale la pena investire.”👃Investimenti in ambito dati e algoritmi. Start-up: la scommessa di Jacob Shiff sulle aziende AI Native su cui investire!
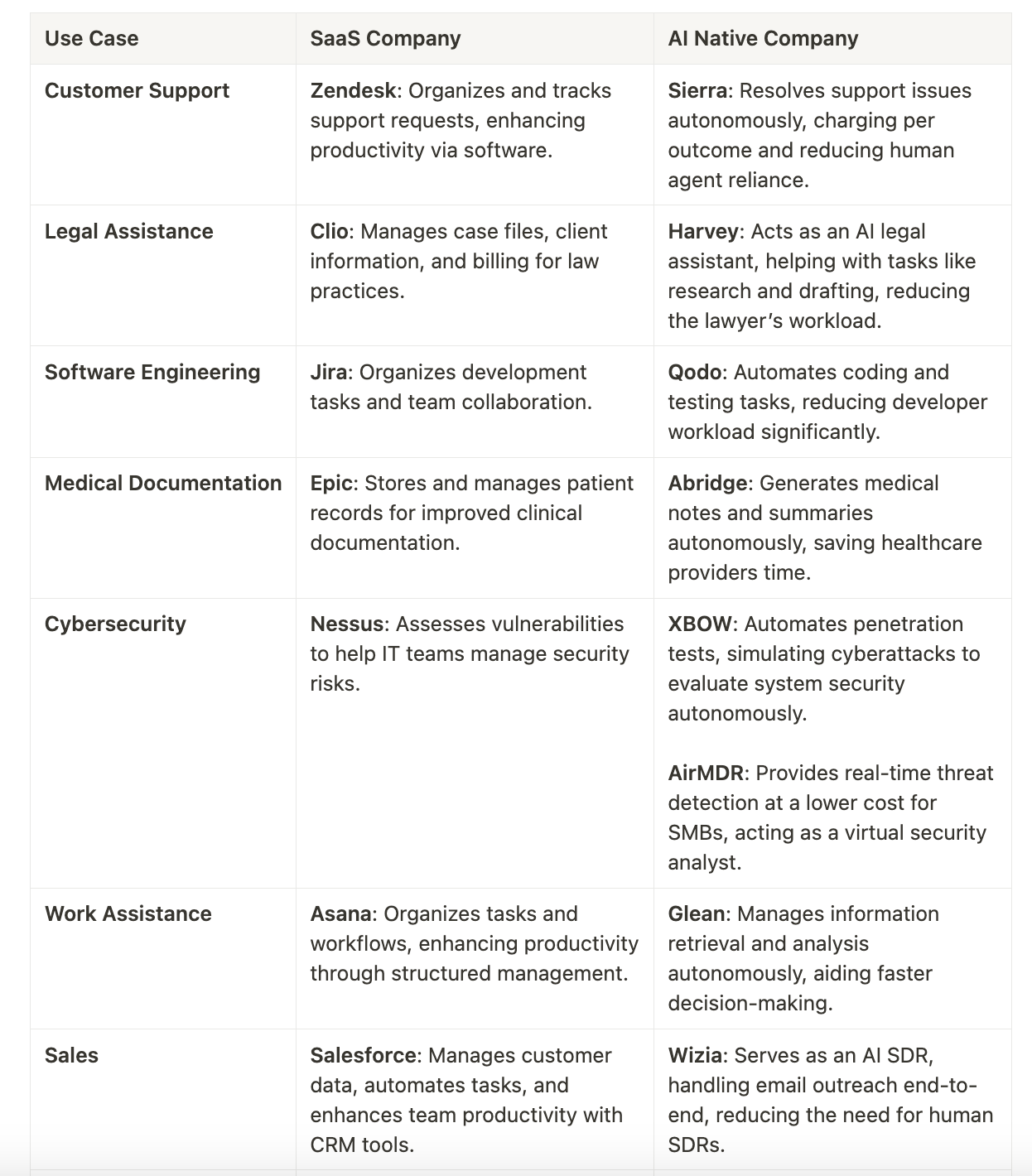
Le AI Native companies non sono semplicemente aziende che usano l’AI, ma sono costruite intorno all’AI. Forniscono servizi direttamente attraverso agenti AI autonomi o semi-autonomi, sostituendo interfacce e flussi di lavoro tradizionali con sistemi “goal-and-guardrails”. A differenza dei modelli SaaS (prezzo per utente/licenza), queste aziende adottano un pricing basato sul lavoro effettivamente svolto (es. per conversazione risolta o attività completata), migliorando, l’allineamento tra fornitore e cliente.
Questa è la sintesi del pensiero sulle aziende più interessanti su cui investire da parte di Jacob Shiff, startupper e investitore nell’ambito AI, il tutto espresso in questo suo articolo decisamente interessante. Per supportare la sua tesi mette a confronto aziende che stanno operando in modo diverso, a livello di modello di business, nel mondo dei servizi. L’immagine che ti riporto qui sotto spiega piuttosto bene il cambiamento di paradigma che Shiff immagina — o, nel caso di Sierra, che è già in corso di implementazione — da parte delle AI Native start-up.

Secondo me, è proprio il cambiamento di modello di business la maggiore complessità di questa possibile trasformazione. Infatti, a parte alcuni rari casi, faccio ancora fatica a vedere crescere questo tipo di monetizzazione "per attività svolta". La trovo personalmente poco favorevole a chi acquista il servizio, che rimane quasi completamente escluso, economicamente parlando, da qualsiasi tipo di ottimizzazione o miglioramento del servizio stesso. Ed infatti, per il momento, (quasi) tutte le aziende che offrono servizi AI lo fanno ancora attraverso i più tradizionali modelli di business SaaS: pay per access o pay per usage.
Le considerazioni di Shiff però vanno oltre il solo tema del business model, e secondo me vale davvero la pena leggerle per intero — anche solo per dare un’occhiata agli esempi di confronto, nella parte finale dell’articolo, tra aziende tradizionali SaaS e le AI native, di cui ti riporto qui sotto la scheda riassuntiva 👇
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Come usare i metric trees per collegare dati, cause e decisioni
Hai mai sentito parlare di metric trees? Sono una di quelle idee che sembrano semplici all’apparenza, ma che possono trasformare profondamente il modo in cui leggiamo, interpretiamo e progettiamo i dati in azienda. In pratica, si tratta di rappresentare una metrica di business – tipo fatturato, retention, conversion rate – come un albero che si scompone nei suoi driver fondamentali.
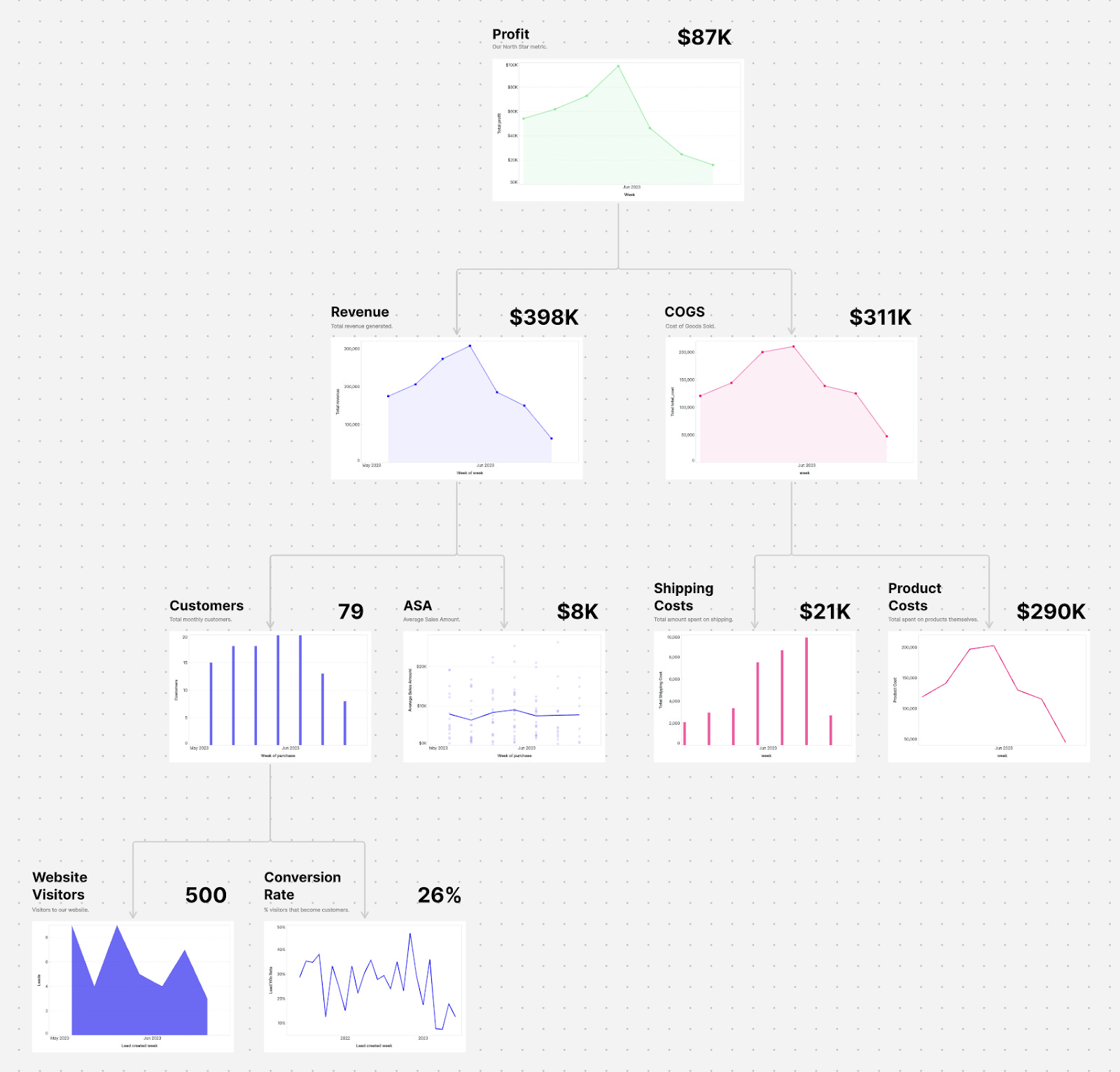
Un modello causale visuale, che permette di passare dal “cosa” al “perché” in modo ordinato, logico e – cosa non da poco – condivisibile. L’idea nasce da Abhi Sivasailam e Trevor Fox, due professionisti con esperienze in aziende come Flexport e Opendoor, che con il loro progetto Levers Labs hanno voluto codificare un approccio analitico capace di rendere trasparente il flusso che collega input e output aziendali.
Invece di perdersi tra mille dashboard e report disallineati, propongono di partire da una metrica-obiettivo e scomporla, passo dopo passo, fino ad arrivare alle leve concrete che un team può effettivamente controllare o monitorare. Il tutto in modo collaborativo, condiviso tra chi costruisce i dati e chi prende decisioni.
Funziona? Francamente non lo so, perché l’ho provato solo su piccoli progetti personali, troppo semplici per arrivare a un giudizio completo. Di sicuro però fa riflettere sulla causalità delle metriche che si vogliono misurare.
Il valore del metodo, secondo me, non sta tanto nella precisione assoluta del modello quanto nella sua capacità di strutturare una conversazione. Un metric tree ben fatto diventa una mappa condivisa per esplorare ipotesi, misurare l’impatto di una feature, valutare l’evoluzione di un funnel.
E’ certamente un metodo impegnativo perché costruirne uno buono richiede tempo, qualità del dato e, soprattutto, dialogo tra chi ha visione di business e chi ha competenze analitiche. Inoltre, il rischio è quello di ipersemplificare: il mondo non è sempre così ordinato come un albero, e molte metriche si influenzano a vicenda in modi non lineari.
Ma proprio per questo vale la pena provarci, partendo da progetti non troppo complessi. In un’epoca in cui i dati sono ovunque ma la comprensione scarseggia, avere uno strumento che riporta le metriche dentro una narrazione causale e condivisa è prezioso. Perché capire perché succedono le cose, in fondo, è sempre meglio che sapere solo che sono successe.
👀 Data Science. Test A/B e trappole statistiche: i consigli di chi ci è passato davvero
Nel mondo dei test A/B, uno degli errori più comuni è il cosiddetto p‑hacking. Questa pratica, che può manifestarsi tanto per furbizia quanto per semplice leggerezza, porta spesso a interpretare come “successi” dei risultati che in realtà sono falsi positivi. Il problema nasce dal fatto che, anche se un test può sembrare significativo a prima vista, l’effetto osservato potrebbe essere semplicemente frutto del caso 🍀.
Il consiglio di approfondimento di questa sezione è dedicato proprio a spiegare questo fenomeno, con esempi tratti da diversi settori produttivi. Ce lo racconta in modo molto concreto un habitué di questa newsletter: Jason Cohen, che ha vissuto sulla sua pelle — prima da imprenditore e ora anche da investitore — gli effetti di questi errori. Il p‑hacking, infatti, può portare imprenditori, marketer e ricercatori a prendere decisioni basate su dati sbagliati 😵💫.
Se vuoi andare un po’ più a fondo e scoprire la formula che Cohen usa per evitare di incappare in questo errore, ti consiglio di investire 10 minuti nel suo video, dove la spiega con grande chiarezza.
Se invece sei più di fretta, almeno leggi questi quattro consigli fondamentali:
🔁 Ripeti i Test per Confermare i Risultati
Non basta ottenere un risultato statisticamente significativo una sola volta. È fondamentale ripetere l’esperimento per verificare se il risultato si ripresenta in modo coerente. Una conferma ripetuta riduce il rischio di affidarsi a un dato isolato e potenzialmente sbagliato.
⏳ Non Fermarti Troppo Presto
Il campione di dati deve essere abbastanza grande per dare vera potenza statistica al test. Fermarsi troppo presto — quando i dati sono ancora “rumorosi” — può far emergere risultati che sembrano significativi ma che, con più dati, tornano nella norma.
💥 Punta su Effetti Sostanziali
Occhio alle piccole variazioni. Gli effetti minimi sono spesso spiegabili con normali fluttuazioni casuali e possono essere falsi positivi. Concentrati invece su cambiamenti che, se reali, porterebbero a impatti evidenti (tipo un incremento a doppia cifra nei tassi di conversione 🚀).
🧠 Formula e Testa Ipotesi Basate su una “Teoria del Cliente”
Evita di “lanciare a caso” varianti per vedere cosa funziona. Parti invece da ipotesi strutturate, basate su una vera comprensione del comportamento del cliente. Questo approccio rende i test più mirati e produce un apprendimento reale. Ogni esperimento diventa così parte di un percorso di validated learning che alimenta decisioni strategiche future.
👅Etica & regolamentazione & impatto sulla società. Data Memos: le 12 lezioni (calviniane) di Lupi e Ciuccarelli che dovremmo rileggere oggi
Era stato, di gran lunga, l’approfondimento più apprezzato tre anni fa — e secondo me ha assunto ancora più importanza oggi. Il titolo e il sottotitolo che Giorgia Lupi e Paolo Ciuccarelli avevano scelto per questo breve saggio erano già di per sé molto esplicativo: “Data Memos - 12 reflections on data (and its representation) that we don’t want to forget in the ‘next-normal’.”
Si stava per uscire dalla pandemia di Covid, e la ferita era ancora fresca: quella consapevolezza di quanto i dati ci fossero stati utili per capire il fenomeno e limitare i danni. Ma avevamo anche toccato con mano quanto fosse difficile maneggiarli, visualizzarli e comunicarli.

Tre anni fa avevo paragonato questo saggio, per il mondo dei dati, a quello che sono state le “Lezioni americane” di Italo Calvino nel 1985 per la letteratura — e per lo scrivere in generale. Innanzitutto, Data Memos possiede tutte le qualità indicate da Calvino: leggerezza, rapidità e visibilità (nelle meravigliose immagini che accompagnano le 12 note), ma anche esattezza, molteplicità e coerenza (nel testo che accompagna ciascuna immagine).
E tra le tesi proposte, ci sono così tanti spunti su cui riflettere per il futuro di chi lavora con i dati — anche in ambiti non strettamente legati alla data visualization.
Non voglio rubarti nemmeno un minuto in più: ti lascio qui sotto solo la mia lezione preferita, perché il tuo tempo merita di essere usato per leggere (o rileggere) questo piccolo capolavoro. 📘✨

Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!
Tra le lezioni di Eugene Yan mi sentirei, di questi tempi, di segnalare soprattutto la 9: "9. Brandolini’s law: The amount of energy needed to refute bullshit is an order of magnitude larger than needed to produce it." [Corollario, sempre di Yan:] "The same applies to using LLMs. "