LaCulturaDelDato #201
Dati & algoritmi attraverso i nostri 5 sensi

For my English speaking friends, click here for the translated version
Ciao,
sono Stefano Gatti e questo è il duecentounesimo numero della newsletter LaCulturaDelDato (e anche il giorno del mio compleanno 🙂) . Le regole che ci siamo dati per questo viaggio le puoi trovare qui.
Ecco i cinque spunti del duecentounesimo numero:
👅Etica & regolamentazione & impatto sulla società. Software Heritage. Codice come patrimonio: SWHID, mirror globali e CodeCommons
Due anni e mezzo fa, quando era stato ospite nel numero 79, Paolo Ferragina, amico e professore di Computer Science alla Scuola Superiore Sant’Anna di Pisa, ci aveva raccontato l’importanza del progetto Software Heritage. Ed era stato l’approfondimento che, dati alla mano, vi era piaciuto più di tutti.
Software Heritage è l’archivio universale del codice sorgente, lanciato nel 2015 da Inria (Francia), grazie a una brillante intuizione di Roberto Di Cosmo e Stefano Zacchiroli , con una missione tanto ambiziosa quanto necessaria: collezionare, preservare e rendere disponibile il codice di tutto il software mai scritto e disponibile pubblicamente. Il cuore del progetto è il referenziamento stabile: gli oggetti archiviati possono essere citati in modo persistente e, oggi, anche a livello di frammento di file. Oggi contiene 27,5 miliardi di file sorgente unici da oltre 420 milioni di progetti: numeri impressionanti, ma che rappresentano solo l’inizio di un lungo percorso che festeggerà quest’anno i 10 anni di attività. Negli ultimi due anni il progetto ha fatto un salto di maturità importante. Dal 2023 il focus si è spostato dalla pura raccolta alla scalabilità e all’integrazione nell’ecosistema Open Science: gli identificatori persistenti (SWHID) sono oggi adottati da repository come HAL e Zenodo, publisher come eLife e iniziative come il Computer Graphics Replicability Stamp. La roadmap 2024 ha segnato un cambio di approccio: da infrastruttura puramente tecnica a piattaforma orientata a prodotti specifici per community definite (ricercatori, archivisti, cybersecurity). Nel 2025 lo SWHID è diventato standard ISO/IEC 18670 e sono arrivati miglioramenti concreti sulle citazioni (BibTeX e frammenti), insieme a investimenti su scansioni massive e momenti di community.

Proprio basandosi su Software Heritage è partito nel febbraio 2025 anche il progetto Code Commons che ha come obiettivo quello di riunire in un unico luogo tutte le informazioni critiche e qualificate necessarie per creare set di dati più piccoli e migliori per la prossima generazione di strumenti di IA. E’ infatti noto che addestrare gli LLM sul codice sorgente aumenti le loro abilità di ragionamento e inferenza. Il progetto CodeCommons pone quindi al centro la trasparenza, l’accessibilità e la tracciabilità, consentendo ai creatori di modelli LLM e ai loro utenti di rispettare i diritti degli autori, promuovendo al contempo un’IA sovrana e sostenibile. E non è teoria: a febbraio 2024 il progetto BigCode ha rilasciato StarCoder2, un modello open allenato usando repository GitHub archiviati in Software Heritage, una prova concreta che si possono fare modelli forti restando trasparenti, e CodeCommons vuole rendere questo approccio la norma offrendo una infrastruttura scalabile, sostenibile e accessibile a tutti. La partnership con UNESCO si è consolidata con symposium annuali (il prossimo sarà a fine gennaio 2026), che hanno portato il tema della preservazione del codice come patrimonio documentale nell’agenda di governi e istituzioni. Particolarmente interessante l’impegno nella costruzione di una rete internazionale di mirror per garantire ridondanza geografica e accesso distribuito: un approccio che riconosce come la preservazione digitale non possa dipendere da un singolo punto di fallimento. E c’è anche un caso italiano: il mirror attivato a Bologna nel dicembre 2023.
E Paolo Ferragina continua a partecipare attivamente ad entrambi i progetti come esperto internazionale sui temi della compressione dati (lossless) e sul progetto di motori di ricerca per la nuova frontiera del “code-to-code similarity search” anche attraverso un importante finanziamento biennale ricevuto dalla Alfred P. Sloan Foundation (USA). I risultati di questi studi permetteranno ai ricercatori di tutto il mondo di effettuare ricerche sofisticate all’interno del codice sorgente del SWH Archive e di rendere la sua infrastruttura computazionale più efficiente, sostenibile, scalabile, e disponibile a tutti.
PS: se hai scritto qualche riga di codice e l’hai pubblicata in un repository pubblico, prova a cercarla: dovresti trovarla. Il mio codice c’è … anche se non merita certo di essere patrimonio dell’umanità 🙂
👃Investimenti in ambito dati e algoritmi. Team più piccoli, meno assunzioni, più solo founder: che sta succedendo nel VC?
Carta è una piattaforma per gestire equity e “cap table” delle aziende private, con workflow per emissioni, piani di stock option e valutazioni, pensata come “ERP del private capital”. Dichiara di gestire, nel suo ambito operativo, più del 50% delle start-up americane che hanno ricevuto un investimento da un fondo di Venture Capital. Per questo, come ti ho raccontato in altre puntate della newsletter, è probabilmente uno dei punti di vista migliori per valutare alcuni trend del mondo del Venture Capital. La cosa più interessante, da questo punto di vista, sono i loro dati: cap table, round, valutazioni, diluizione, term sheet e segnali di liquidità, osservati su una base ampia di società e investitori. Tra l’altro, nel 2022 hanno acquisito Capdesk, un’azienda che operava nel loro settore in Europa (UK incluso).
Per questo, l’approfondimento che ti consiglio oggi, e cioè l’intervista di Gergely Orosz (in arte The Pragmatic Engineer) a Peter Walker, Head of Insights di Carta, offre informazioni uniche che non vanno assolutamente trascurate, sia che tu lavori nell’ambito del VC o del private equity, sia che tu sia founder (e non solo) in una start-up, o che tu sia “semplicemente” appassionato di innovazione. Ascoltare interamente l’ora e venti minuti dell’intervista è un’opzione, perché è decisamente gradevole anche per lo stile coinvolgente di entrambi. L’articolo fornisce comunque un’ottima sintesi, anche grafica, dei takeaways più interessanti. Di seguito ti elenco i segnali che considero più interessanti e che segnano evoluzioni possibili del mercato:
Le start-up stanno assumendo sempre meno.
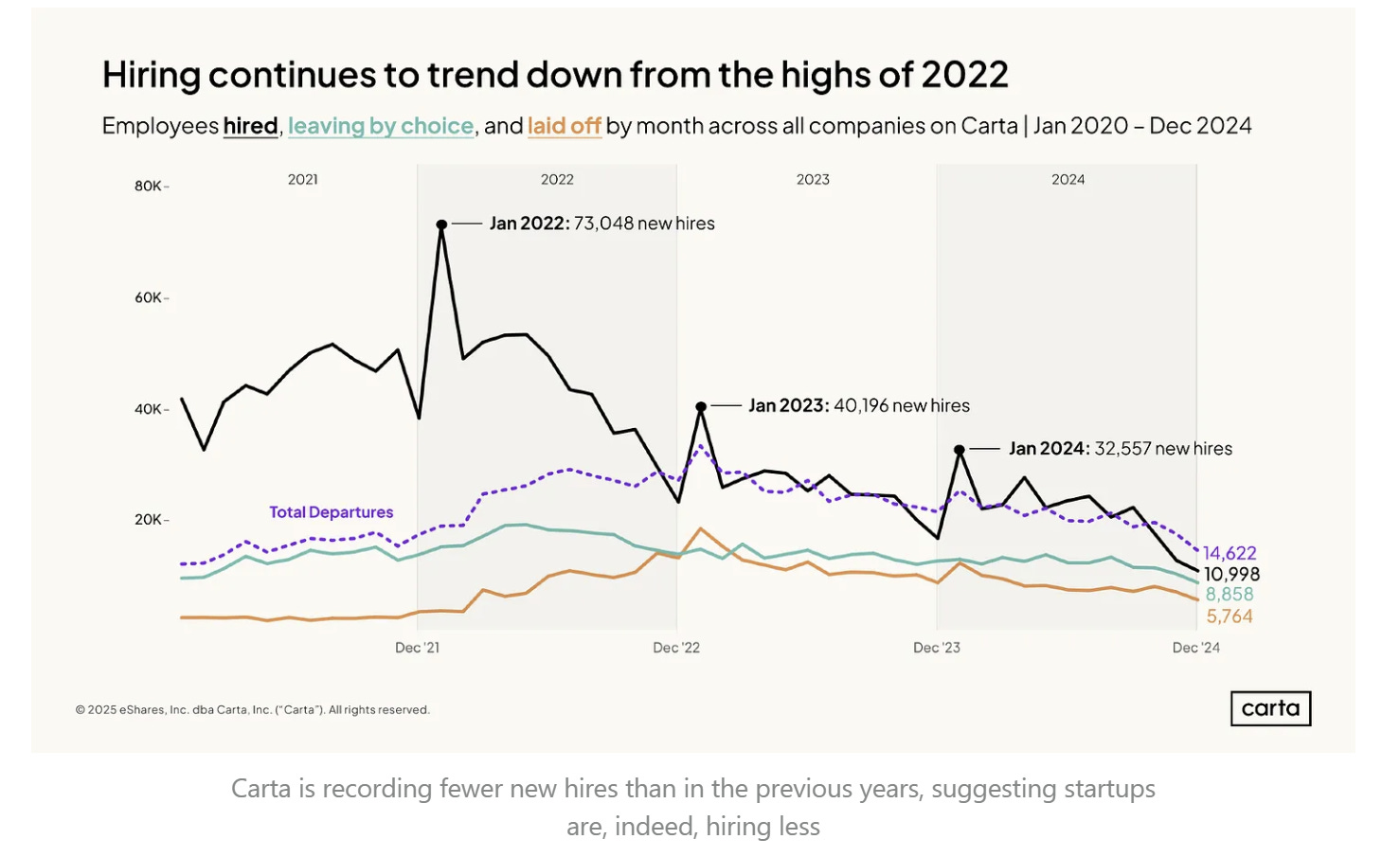
I team delle start-up, a parità di stadio evolutivo, sono sempre più piccoli.
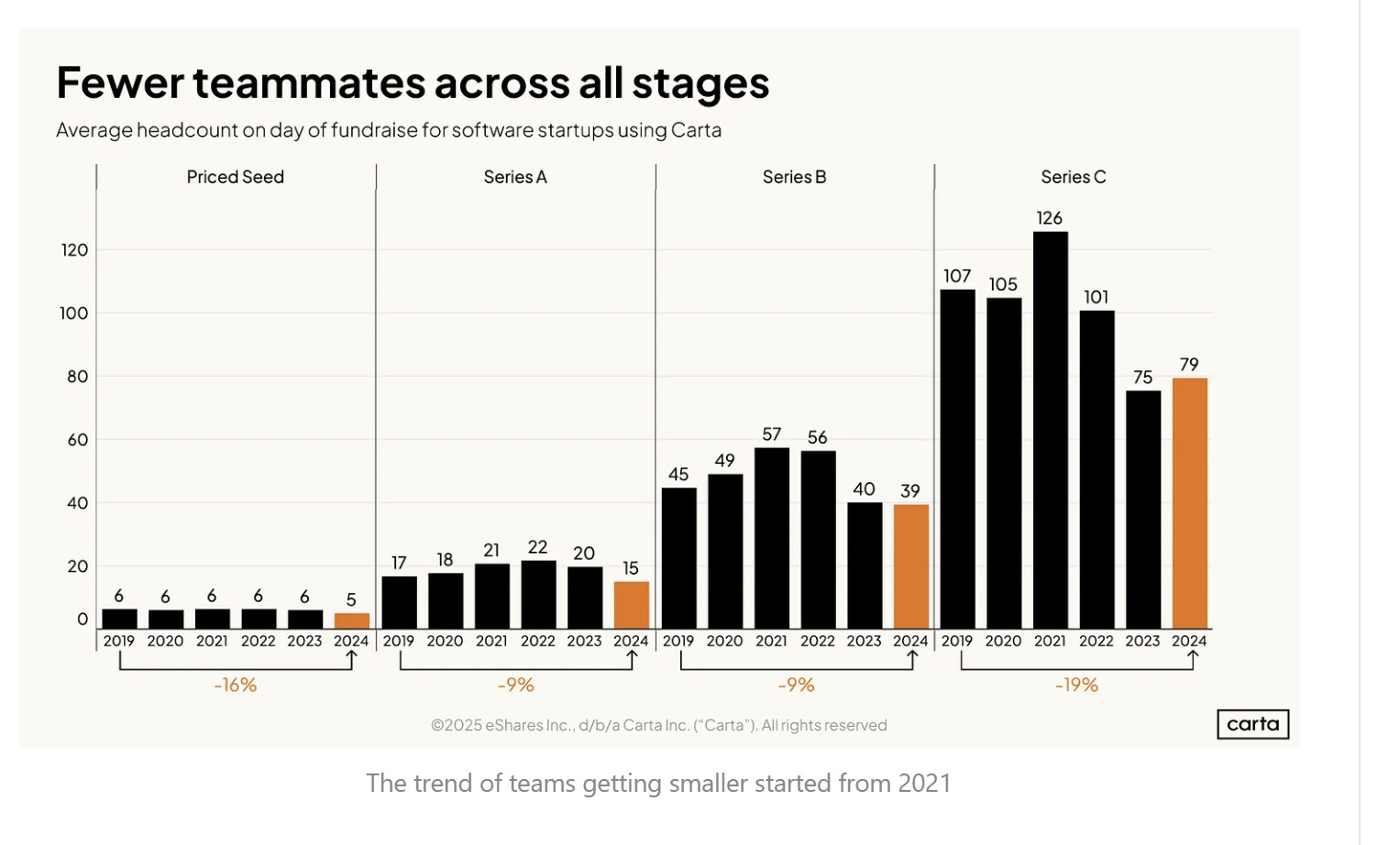
Cresce il numero di start-up formate da un solo founder.
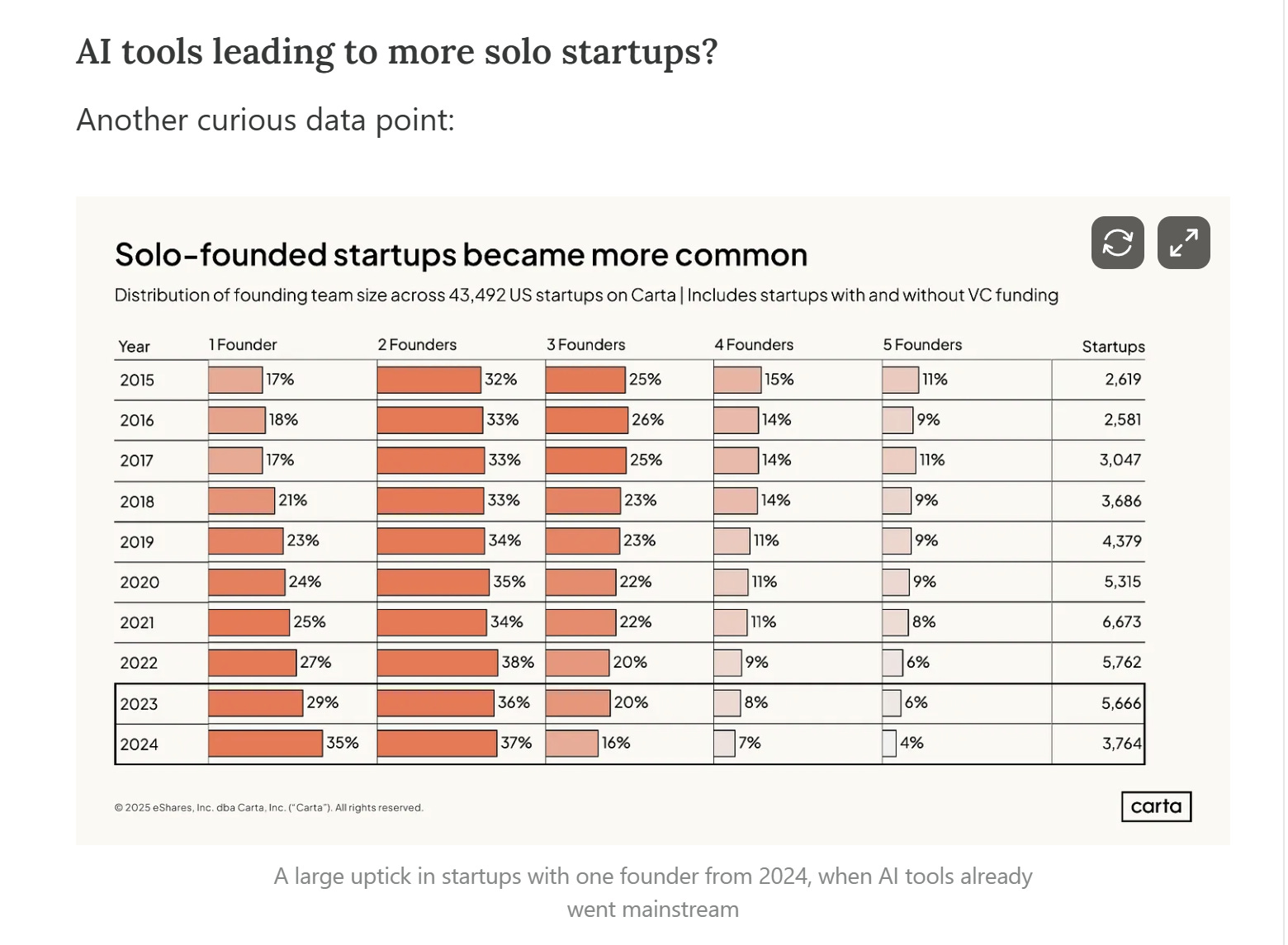
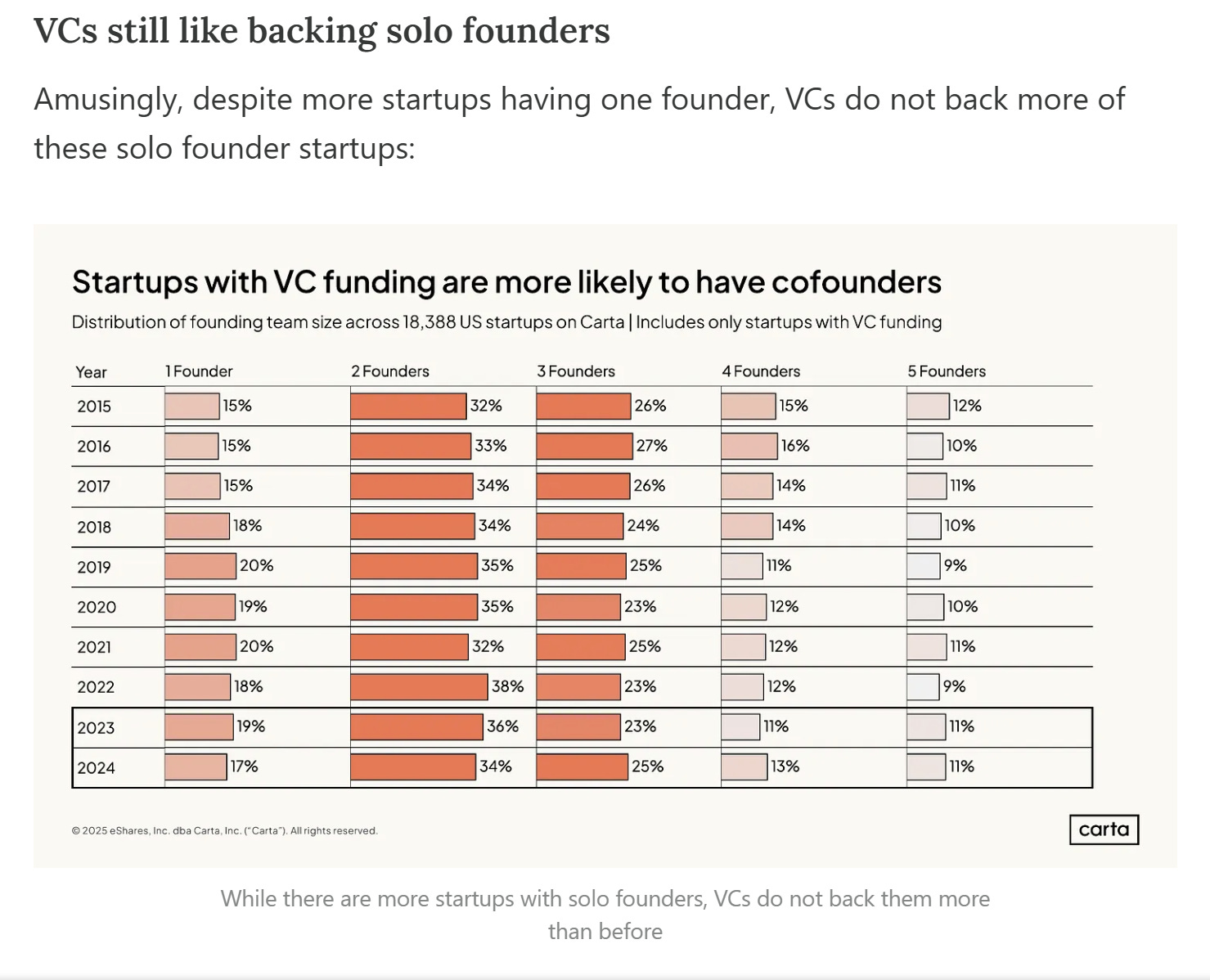
Ma diminuiscono le start-up con un solo founder che hanno ricevuto un finanziamento da un VC.
Questi quattro segnali, messi insieme, mi fanno affermare con una certa confidenza (non del 95% però 🙂) che:
l’impatto dell’AI sulle start-up sta iniziando ad essere molto forte. Come ti scrivo da più di un anno, credo che questo tipo di azienda sia quello che possa più facilmente avvantaggiarsi dei nuovi tool. E per diverse ragioni!
Il bootstrapping (cercare di crescere senza fondi esterni) inizia ad essere sempre più diffuso tra i founder con più talento.
Il mercato dei VC diventerà sempre più selettivo e con un’attenzione maggiore alle fasi iniziali di vita delle start-up, perché se non sei Sequoia o a16z è in questa fase che si intercetta il maggior valore. Ma la fase di sourcing e scouting si complica… e bisognerà mettere in campo strumenti che non sono solo i soldi!
Ma ci sono un sacco di altre cose interessanti nell’intervista: per esempio le metriche con cui si valutano le start-up e, se sei un advisor, di quali quote puoi accedere. Buona lettura (o visione), se vuoi scendere anche nei dettagli più piccoli!
🖐️Tecnologia (data engineering). Anthropic sorpassa OpenAI (in enterprise): i numeri di Menlo VC che spiegano il ribaltone 2025
Ti avevo già segnalato 6 numeri fa la storia e la crescita di Anthropic nel mercato enterprise nel 2025. L’aggiornamento dei dati a fine 2025, presi dalla stessa fonte (cioè i report di Menlo Ventures), oltre a confermare un ribaltone clamoroso nel 2025 da parte di Anthropic rispetto a OpenAI, mostra trend interessanti.
Ma guardiamo i dati: questo era il grafico sulle quote di mercato contenuto a metà 2025 in questo report.
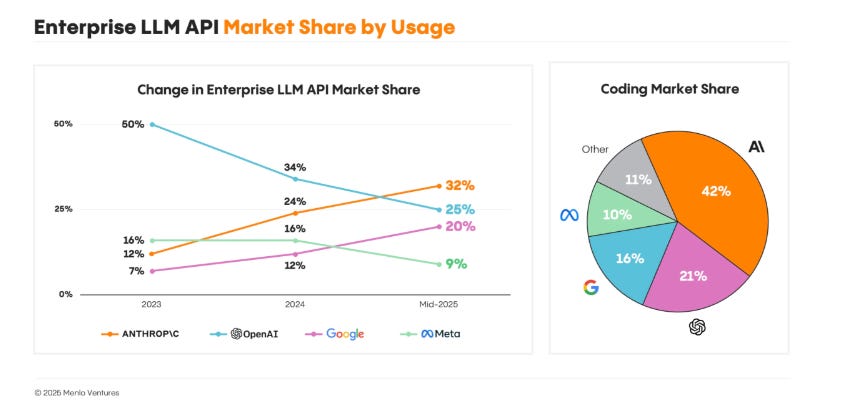
A dicembre Menlo VC ha aggiornato i dati nel documento, peraltro degno di essere letto nella sua interezza: “The state of generative AI in the enterprise”.
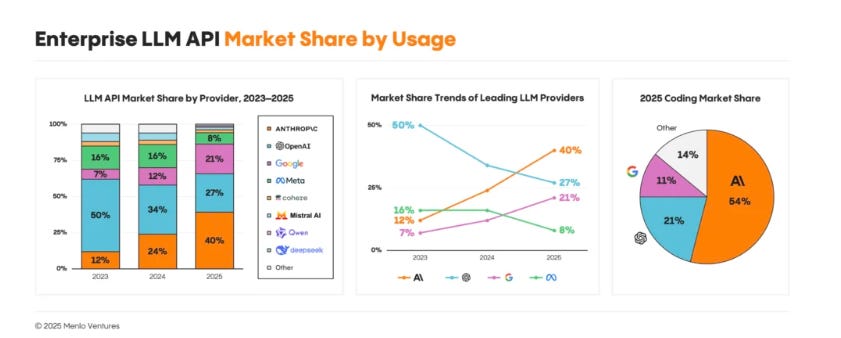
I trend sembrano accentuarsi negli ultimi 6 mesi, e cioè:
Leadership di Anthropic nel settore corporate: dal 32% al 40% di mercato B2B overall, e con crescita forte sul coding dal 42% al 54%.
Ulteriore rafforzamento delle quote di mercato dei tre leader (Anthropic, OpenAI e Google): sia sul mercato B2B overall (dal 77% all’88% totale) sia su quello del coding (dal 79% all’86%).
Un dato importante su tutti: solo l’11% dei team ha cambiato provider nell’ultimo anno; il 66% ha fatto upgrade rimanendo con lo stesso vendor. Se ti affidi a un’API LLM, tendi a restarci incollato: questo rende ancora più significativa la crescita di Anthropic.
Di fronte a questi numeri, e anche alle recenti riduzioni di prezzo per milione di token di OpenAI, i due consigli che a mio modo di vedere sono più utili se fai scelte tecnologiche in azienda sono:
Valuta strategie multi-vendor fin da subito: migrare dopo è costoso, ma il differenziale di prezzo GPT-5 vs Claude potrebbe superare l’inerzia.
Monitora il rapporto performance/costo su workload reali in produzione: Anthropic sembra vincere in termini di qualità, ma la guerra dei prezzi è appena iniziata.
Il mercato enterprise AI è arrivato a 37 miliardi di dollari nel 2025. La spesa in API LLM ha superato gli 8,4 miliardi nei primi sei mesi, più del doppio dell’intero 2024. E un mercato così in crescita lascia spazio anche a chi è dietro di recuperare!
👂🏾Organizzazione e cultura dei dati e algoritmi nelle organizzazioni. Più slide, meno tempo: il (possibile) paradosso delle presentazioni efficaci
Spesso e volentieri, quando faccio presentazioni o chiedo ad altri di farle, mi concentro sul numero di slide per avere un’indicazione del tempo di cui si avrà bisogno. Tante volte ho sbagliato: sia perché è difficile stimare il tempo necessario per ogni slide, sia (soprattutto) perché ho sottovalutato la capacità di comprensione o di interazione dell’audience in base alle slide preparate. Con il tempo sto imparando che, in molti casi, il paradigma “less is more” funziona anche sulle slide, soprattutto per quanto riguarda la densità informativa. Cioè: meno informazione c’è nella slide, più l’audience riesce a seguire, a essere coinvolta e più “adattabile” diventa la presentazione (anche in termini di tempo per slide). Questo approccio richiede di avere chiari, fin dall’inizio, quali sono i pochi concetti chiave che vuoi trasmettere. E se non conosci l’audience, questo può diventare un rischio di questa strategia.
Proprio su questo approccio, cioè su come presentare bene dati e informazioni a un’audience, è dedicato l’approfondimento che ti consiglio oggi. Se credi che limitare il numero di slide accorci automaticamente le presentazioni, può essere che ti stia sbagliando. Alex Velez di Storytelling with Data dimostra, in questo post, esattamente il contrario: ha trasformato una singola slide ultra-densa (discussa in 5-10 minuti in un board meeting) in nove slide pulite, presentabili in soli due minuti. Il problema delle restrizioni sul numero di slide è che portano a condensare tutto in poche pagine sovraccariche. L’audience perde tempo a decifrare grafici illeggibili invece di seguire il ragionamento. La soluzione proposta è semplice ma controintuitiva: controlla i minuti, non le slide.
Dall’articolo risultano tre consigli pratici per chi presenta:
Chiedi quanto tempo hai a disposizione, non quante slide puoi usare.
Dedica una slide a un concetto: meglio nove slide chiare che una illeggibile.
Usa tipi di grafico migliori: nel caso mostrato, slope graph e square area chart hanno sostituito i pie chart, guadagnando chiarezza.
Se sei un manager che organizza meeting, smetti di mandare (come faccio a volte anche io ☹️) email con “massimo 2 slide”. Dai invece un tempo limite chiaro e lascia che il team decida come usarlo al meglio.
👀 Data Science. Da equazioni a intuizione visiva: 4 capitoli di Machine Learning “dai primi principi” in notebook Jupyter
“Raccolta di notebook Jupyter che implementano e derivano matematicamente, a partire dai principi fondamentali, algoritmi di machine learning. L’output di ciascun notebook è una visualizzazione dell’algoritmo durante la fase di addestramento, fino alla convergenza sui pesi ottimali. Buono studio! – Gavin”
Questa è la presentazione molto minimalista di un progetto di open learning science di Gavin Hung, ora software engineer in Nvidia ed ex-studente di computer science dell’università di Maryland con la passione della divulgazione scientifica.
C’è una differenza enorme tra leggere le formule del gradient descent e vedere i pesi di una rete neurale che convergono passo dopo passo. ML Visualized è un progetto che raccoglie Jupyter Notebook interattivi per implementare algoritmi di machine learning dai primi principi, con animazioni che mostrano il training in tempo reale.
Il progetto copre 4 capitoli: Optimization (gradient descent), Clustering & Reduction (PCA, K-Means), Linear Models (perceptron, logistic regression) e Neural Networks (backpropagation). Ogni notebook genera visualizzazioni animate del processo di apprendimento fino alla convergenza ottimale.
A mio giudizio, è una risorsa eccellente per capire davvero come funzionano gli algoritmi, non solo in teoria ma vedendo i parametri che cambiano ad ogni iterazione. Il limite, se vogliamo è che richiede basi solide di matematica e programmazione, non è entry-level.
Se devi spiegare machine learning a colleghi o studenti, ML Visualized è perfetto come ponte tra equazioni e intuizione visiva. Ogni notebook include anche derivazioni matematiche dettagliate per chi vuole approfondire.
Se hai ulteriori suggerimenti e riflessioni sui temi di questo numero o per migliorare questa newsletter scrivimi (st.gatti@gmail.com) o commenta su substack.
Se ti è piaciuta e non sei ancora iscritto lascia la tua mail qui sotto e aiutami a diffonderla!
Alla prossima!